Sending signals to a Debezium connector
Overview
The Debezium signaling mechanism provides a way to modify the behavior of a connector, or to trigger a one-time action, such as initiating an ad hoc snapshot of a table. To use signals to trigger a connector to perform a specified action, you can configure the connector to use one or more of the following channels:
- SourceSignalChannel
-
You can issue a SQL command to add a signal message to a specialized signaling data collection. The signaling data collection, which you create on the source database, is designated exclusively for communicating with Debezium.
- KafkaSignalChannel
-
You submit signal messages to a configurable Kafka topic.
- JmxSignalChannel
-
You submit signals through the JMX
signaloperation. - FileSignalChannel
-
You can use a file to send signals.
- Custom
-
You submit signals to a custom channel that you implement.
When Debezium detects that a new logging record or ad hoc snapshot record is added to the channel, it reads the signal, and initiates the requested operation.
Signaling is available for use with the following Debezium connectors:
-
Db2
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SQL Server
You can specify which channel is enabled by setting the signal.enabled.channels configuration property. The property lists the names of the channels that are enabled. By default, Debezium provides the following channels: source and kafka.
The source channel is enabled by default, because it is required for incremental snapshot signals.
Enabling source signaling channel
By default, the Debezium source signaling channel is enabled.
You must explicitly configure signaling for each connector that you want to use it with.
-
On the source database, create a signaling data collection table for sending signals to the connector. For information about the required structure of the signaling data collection, see Structure of a signaling data collection.
-
For source databases such as Db2 or SQL Server that implement a native change data capture (CDC) mechanism, enable CDC for the signaling table.
-
Add the name of the signaling data collection to the Debezium connector configuration.
In the connector configuration, add the propertysignal.data.collection, and set its value to the fully-qualified name of the signaling data collection that you created in Step 1.
For example,signal.data.collection = inventory.debezium_signals.
The format for the fully-qualified name of the signaling collection depends on the connector.
The following example shows the naming formats to use for each connector:- Db2
-
<schemaName>.<tableName> - MongoDB
-
<databaseName>.<collectionName> - MySQL
-
<databaseName>.<tableName> - Oracle
-
<databaseName>.<schemaName>.<tableName> - PostgreSQL
-
<schemaName>.<tableName> - SQL Server
-
<databaseName>.<schemaName>.<tableName>
For more information about setting thesignal.data.collectionproperty, see the table of configuration properties for your connector.
Structure of a signaling data collection
A signaling data collection, or signaling table, stores signals that you send to a connector to trigger a specified operation. The structure of the signaling table must conform to the following standard format.
-
Contains three fields (columns).
-
Fields are arranged in a specific order, as shown in Table 1.
| Field | Type | Description |
|---|---|---|
|
|
An arbitrary unique string that identifies a signal instance. |
|
|
Specifies the type of signal to send. |
|
|
Specifies JSON-formatted parameters to pass to a signal action. |
| The field names in a data collection are arbitrary. The preceding table provides suggested names. If you use a different naming convention, ensure that the values in each field are consistent with the expected content. |
Creating a signaling data collection
You create a signaling table by submitting a standard SQL DDL query to the source database.
-
You have sufficient access privileges to create a table on the source database.
-
Submit a SQL query to the source database to create a table that is consistent with the required structure, as shown in the following example:
CREATE TABLE <tableName> (id VARCHAR(<varcharValue>) PRIMARY KEY, type VARCHAR(<varcharValue>) NOT NULL, data VARCHAR(<varcharValue>) NULL);
|
The amount of space that you allocate to the |
The following example shows a CREATE TABLE command that creates a three-column debezium_signal table:
CREATE TABLE debezium_signal (id VARCHAR(42) PRIMARY KEY, type VARCHAR(32) NOT NULL, data VARCHAR(2048) NULL);Enabling Kafka signaling channel
You can enable the Kafka signaling channel by adding it to the signal.enabled.channels configuration property, and then adding the name of the topic that receives signals to the signal.kafka.topic property.
After you enable the signaling channel, a Kafka consumer is created to consume signals that are sent to the configured signal topic.
|
To use Kafka signaling to trigger ad hoc incremental snapshots for most connectors, you must first enable a |
Message format
The key of the Kafka message must match the value of the topic.prefix connector configuration option.
The value is a JSON object with type and data fields.
When the signal type is set to execute-snapshot, the data field must include the fields that are listed in the following table:
| Field | Default | Value | ||
|---|---|---|---|---|
|
|
The type of the snapshot to run.
Currently Debezium supports the |
||
|
N/A |
An array of comma-separated regular expressions that match the fully-qualified names of the data collections to include in the snapshot. |
||
|
N/A |
An optional string that specifies a condition that the connector evaluates to designate a subset of records to include in a snapshot.
|
||
|
N/A |
An optional array that specifies a set of additional conditions that the connector evaluates to determine the subset of records to include in a snapshot.
|
The following example shows a typical execute-snapshot Kafka message:
Key = `test_connector`
Value = `{"type":"execute-snapshot","data": {"data-collections": ["schema1.table1", "schema1.table2"], "type": "INCREMENTAL"}}`
Enabling a JMX signaling channel
You can enable the JMX signaling by adding jmx to the signal.enabled.channels property in the connector configuration, and then enabling the JMX MBean Server to expose the signaling bean.
Sending JMX signals
-
Use your preferred JMX client (for example. JConsole or JDK Mission Control) to connect to the MBean server.
-
Search for the Mbean
debezium.<connector-type>.management.signals.<server>. The Mbean exposessignaloperations that accept the following input parameters:- p0
-
The id of the signal.
- p1
-
The type of the signal, for example,
execute-snapshot. - p2
-
A JSON data field that contains additional information about the specified signal type.
-
Send an
execute-snapshotsignal by providing value for the input parameters.
In the JSON data field, include the information that is listed in the following table:Table 3. Execute snapshot data fields Field Default Value typeincrementalThe type of the snapshot to run. Currently Debezium supports the
incrementalandblockingtypes.data-collectionsN/A
An array of comma-separated regular expressions that match the fully-qualified names of the tables to include in the snapshot.
Specify the names by using the same format as is required for the signal.data.collection configuration option.additional-conditionN/A
An optional string that specifies a condition that the connector evaluates to designate a subset of records to include in a snapshot.
This property is deprecated and should be replaced by the
additional-conditionsproperty.additional-conditionsN/A
An optional array that specifies a set of additional conditions that the connector evaluates to determine the subset of records to include in a snapshot.
Each additional condition is an object that specifies the criteria for filtering the data that an ad hoc snapshot captures. You can set the following properties for each additional condition:data-collection-
The fully-qualified name of the {data-collection} that the filter applies to. You can apply different filters to each {data-collection}.
filter-
Specifies column values that must be present in a database record for the snapshot to include it, for example,
"color='blue'".
The snapshot process evaluates records in the {data-collection} against thefiltervalue and captures only records that contain matching values.
The specific values that you assign to thefilterproperty depend on the type of ad hoc snapshot:-
For incremental snapshots, you specify a search condition fragment, such as
"color='blue'", that the snapshot appends to the condition clause of a query. -
For blocking snapshots, you specify a full
SELECTstatement, such as the one that you might set in thesnapshot.select.statement.overridesproperty.
-
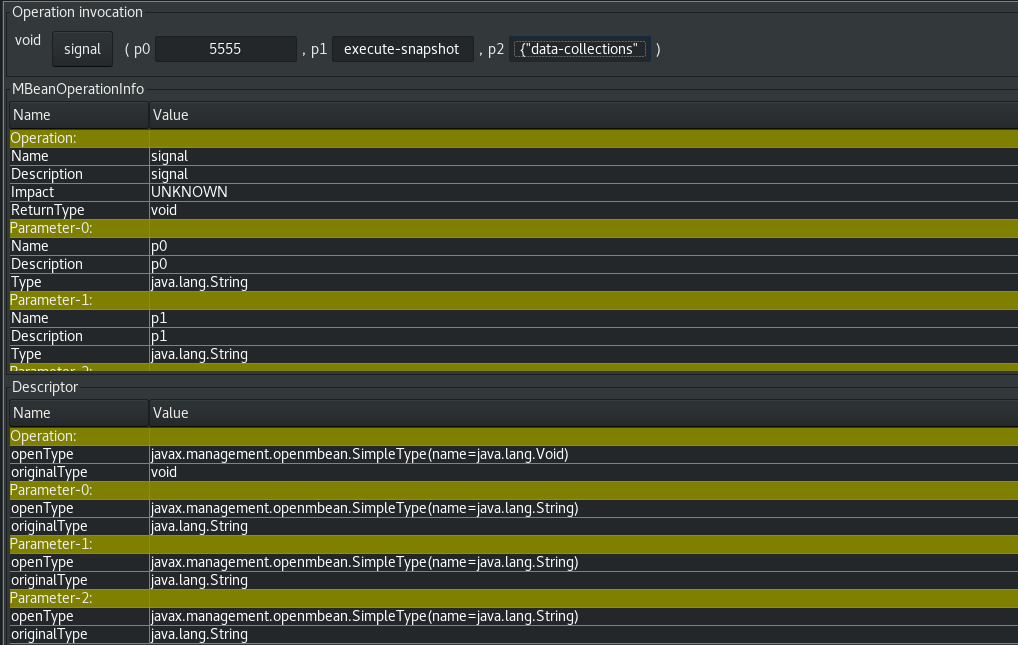
The following image shows an example of how to use JConsole to send a signal:
Custom signaling channel
The signaling mechanism is designed to be extensible. You can implement channels as needed to send signals to Debezium in a manner that works best in your environment.
Adding a signaling channel involves several steps:
Provide custom signaling channel
Custom signaling channels are Java classes that implement the io.debezium.pipeline.signal.channels.SignalChannelReader service provider interface (SPI).
For example:
public interface SignalChannelReader {
String name(); (1)
void init(CommonConnectorConfig connectorConfig); (2)
List<SignalRecord> read(); (3)
void close(); (4)
}| 1 | The name of the reader.
To enable Debezium to use the channel, specify this name in the connector’s signal.enabled.channels property. |
| 2 | Initializes specific configuration, variables, or connections that the channel requires. |
| 3 | Reads signal from the channel.
The SignalProcessor class calls this method to retrieve the signal to process. |
| 4 | Closes all allocated resources. Debezium calls this methods when the connector is stopped. |
Debezium core module dependencies
A custom signaling channel Java project has compile dependencies on the Debezium core module.
You must include these compile dependencies in your project’s pom.xml file, as shown in the following example:
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-core</artifactId>
<version>${version.debezium}</version> (1)
</dependency>| 1 | ${version.debezium} represents the version of the Debezium connector. |
Declare your implementation in the META-INF/services/io.debezium.pipeline.signal.channels.SignalChannelReader file.
Deploying a custom signaling channel
-
You have a custom signaling channel Java program.
-
To use a custom signaling channel with a Debezium connector, export the Java project to a JAR file, and copy the file to the directory that contains the JAR file for each Debezium connector that you want to use it with.
For example, in a typical deployment, the Debezium connector files are stored in subdirectories of a Kafka Connect directory (/kafka/connect), with each connector JAR in its own subdirectory (/kafka/connect/debezium-connector-db2,/kafka/connect/debezium-connector-mysql, and so forth).
| To use a custom signaling channel with multiple connectors, you must place a copy of the custom signaling channel JAR file in the subdirectory for each connector. |
Signal actions
You can use signaling to initiate the following actions:
Some signals are not compatible with all connectors.
Logging signals
You can request a connector to add an entry to the log by creating a signaling table entry with the log signal type.
After processing the signal, the connector prints the specified message to the log.
Optionally, you can configure the signal so that the resulting message includes the streaming coordinates.
| Column | Value | Description |
|---|---|---|
id |
|
|
type |
|
The action type of the signal. |
data |
|
The |
Ad hoc snapshot signals
You can request a connector to initiate an ad hoc snapshot by creating a signal with the execute-snapshot signal type.
After processing the signal, the connector runs the requested snapshot operation.
Unlike the initial snapshot that a connector runs after it first starts, an ad hoc snapshot occurs during runtime, after the connector has already begun to stream change events from a database. You can initiate ad hoc snapshots at any time.
Ad hoc snapshots are available for the following Debezium connectors:
-
Db2
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SQL Server
| Column | Value |
|---|---|
id |
|
type |
|
data |
|
| Key | Value |
|---|---|
test_connector |
|
For more information about ad hoc snapshots, see the Snapshots topic in the documentation for your connector.
Ad hoc snapshot stop signals
You can request a connector to stop an in-progress ad hoc snapshot by creating a signal table entry with the stop-snapshot signal type.
After processing the signal, the connector will stop the current in-progress snapshot operation.
You can stop ad hoc snapshots for the following Debezium connectors:
-
Db2
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SQL Server
| Column | Value |
|---|---|
id |
|
type |
|
data |
|
You must specify the type of the signal.
The data-collections field is optional.
Leave the data-collections field blank to request the connector to stop all activity in the current snapshot.
If you want the incremental snapshot to proceed, but you want to exclude specific collections from the snapshot, provide a comma-separated list of the names of the collections or regular expressions to exclude.
After the connector processes the signal, the incremental snapshot proceeds, but it excludes data from the collections that you specify.
Incremental snapshots
Incremental snapshots are a specific type of ad hoc snapshot. In an incremental snapshot, the connector captures the baseline state of the tables that you specify, similar to an initial snapshot. However, unlike an initial snapshot, an incremental snapshot captures tables in chunks, rather than all at once. The connector uses a watermarking method to track the progress of the snapshot.
By capturing the initial state of the specified tables in chunks rather than in a single monolithic operation, incremental snapshots provide the following advantages over the initial snapshot process:
-
While the connector captures the baseline state of the specified tables, streaming of near real-time events from the transaction log continues uninterrupted.
-
If the incremental snapshot process is interrupted, it can be resumed from the point at which it stopped.
-
You can initiate an incremental snapshot at any time.
Incremental snapshot pause signals
You can request a connector to pause an in-progress incremental snapshot by creating a signal table entry with the pause-snapshot signal type.
After processing the signal, the connector will stop pause current in-progress snapshot operation.
Therefor it’s not possible to specify the data collection as the snapshot processing will be paused in position where it is in time of processing of the signal.
You can pause incremental snapshots for the following Debezium connectors:
-
Db2
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SQL Server
| Column | Value |
|---|---|
id |
|
type |
|
You must specify the type of the signal.
The data field is ignored.
Incremental snapshot resume signals
You can request a connector to resume a paused incremental snapshot by creating a signal table entry with the resume-snapshot signal type.
After processing the signal, the connector will resume previously paused snapshot operation.
You can resume incremental snapshots for the following Debezium connectors:
-
Db2
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SQL Server
| Column | Value |
|---|---|
id |
|
type |
|
You must specify the type of the signal.
The data field is ignored.
For more information about incremental snapshots, see the Snapshots topic in the documentation for your connector.
Blocking snapshot signals
You can request a connector to initiate an ad hoc blocking snapshot by creating a signal with the execute-snapshot signal type and data.type with value blocking.
After processing the signal, the connector runs the requested snapshot operation.
Unlike the initial snapshot that a connector runs after it first starts, an ad hoc blocking snapshot occurs during runtime, after the connector has stopped to stream change events from a database. You can initiate ad hoc blocking snapshots at any time.
Blocking snapshots are available for the following Debezium connectors:
-
Db2
-
MongoDB
-
MySQL
-
Oracle
-
PostgreSQL
-
SQL Server
| Column | Value |
|---|---|
id |
|
type |
|
data |
|
| Key | Value |
|---|---|
test_connector |
|
For more information about blocking snapshots, see the Snapshots topic in the documentation for your connector.
Defining a custom action
Custom actions enable you to extend the Debezium signaling framework to trigger actions that are not available in the default implementation. You can use a custom action with multiple connectors.
To define a custom signal action, you must define the following interface:
@FunctionalInterface
public interface SignalAction<P extends Partition> {
/**
* @param signalPayload the content of the signal
* @return true if the signal was processed
*/
boolean arrived(SignalPayload<P> signalPayload) throws InterruptedException;
}The io.debezium.pipeline.signal.actions.SignalAction exposes a single method with one parameter, which represents the message payloads sent through the signaling channel.
After you define a custom signaling action, use the following SPI interface to make the custom action available to the signaling mechanism: io.debezium.pipeline.signal.actions.SignalActionProvider.
public interface SignalActionProvider {
/**
* Create a map of signal action where the key is the name of the action.
*
* @param dispatcher the event dispatcher instance
* @param connectorConfig the connector config
* @return a concrete action
*/
<P extends Partition> Map<String, SignalAction<P>> createActions(EventDispatcher<P, ? extends DataCollectionId> dispatcher, CommonConnectorConfig connectorConfig);
}Your implementation must return a map of the signal action.
Set the map key to the name of the action.
The key is used as the type of the signal.
Debezium core module dependencies
A custom actions Java project has compile dependencies on the Debezium core module.
Include the following compile dependencies in your project’s pom.xml file:
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-core</artifactId>
<version>${version.debezium}</version> (1)
</dependency>| 1 | ${version.debezium} represents the version of the Debezium connector. |
Declare your provider implementation in the META-INF/services/io.debezium.pipeline.signal.actions.SignalActionProvider file.
Deploying a custom action
-
You have a custom actions Java program.
-
To use a custom action with a Debezium connector, export the Java project to a JAR file, and copy the file to the directory that contains the JAR file for each Debezium connector that you want to use it with.
For example, in a typical deployment, the Debezium connector files are stored in subdirectories of a Kafka Connect directory (/kafka/connect), with each connector JAR in its own subdirectory (/kafka/connect/debezium-connector-db2,/kafka/connect/debezium-connector-mysql, and so forth).
| To use a custom action with multiple connectors, you must place a copy of the custom signaling channel JAR file in the subdirectory for each connector. |