
Microservice-based architectures can be considered an industry trend and are thus often found in enterprise applications lately. One possible way to keep data synchronized across multiple services and their backing data stores is to make us of an approach called change data capture, or CDC for short.
Essentially CDC allows to listen to any modifications which are occurring at one end of a data flow (i.e. the data source) and communicate them as change events to other interested parties or storing them into a data sink. Instead of doing this in a point-to-point fashion, it’s advisable to decouple this flow of events between data sources and data sinks. Such a scenario can be implemented based on Debezium and Apache Kafka with relative ease and effectively no coding.
As an example, consider the following microservice-based architecture of an order management system:
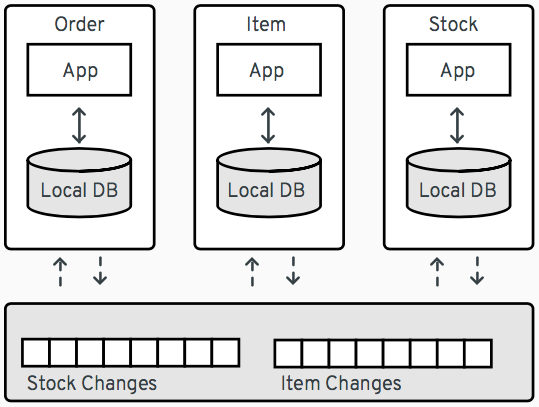
This system comprises three services, Order, Item and Stock. If the Order service receives an order request, it will need information from the other two, such as item definitions or the stock count for specific items. Instead of making synchronous calls to these services to obtain this information, CDC can be used to set up change event streams for the data managed by the Item and Stock services. The Order service can subscribe to these event streams and keep a local copy of the relevant item and stock data in its own database. This approach helps to decouple the services (e.g. no direct impact by service outages) and can also be beneficial for overall performance, as each service can hold optimized views just of those data items owned by other services which it is interested in.
How to Handle Aggregate Objects?
There are use cases however, where things are a bit more tricky. It is sometimes useful to share information across services and data stores by means of so-called aggregates, which are a concept/pattern defined by domain-driven design (DDD). In general, a DDD aggregate is used to transfer state which can be comprised of multiple different domain objects that are together treated as a single unit of information.
Concrete examples are:
-
customers and their addresses which are represented as a customer record aggregate storing a customer and a list of addresses
-
orders and corresponding line items which are represented as an order record aggregate storing an order and all its line items
Chances are that the data of the involved domain objects backing these DDD aggregates are stored in separate relations of an RDBMS. When making use of the CDC capabilities currently found in Debezium, all changes to domain objects will be independently captured and by default eventually reflected in separate Kafka topics, one per RDBMS relation. While this behaviour is tremendously helpful for a lot of use cases it can be pretty limiting to others, like the DDD aggregate scenario described above. Therefore, this blog post explores how DDD aggregates can be built based on Debezium CDC events, using the Kafka Streams API.
Capturing Change Events from a Data Source
The complete source code for this blog post is provided in the Debezium examples repository on GitHub. Begin by cloning this repository and changing into the kstreams directory:
git clone https://github.com/debezium/debezium-examples.git
cd kstreamsThe project provides a Docker Compose file with services for all the components you may already know from the Debezium tutorial:
-
A Kafka Connect instance with the Debezium CDC connectors
-
MySQL (populated with some test data)
In addition it declares the following services:
-
MongoDB which will be used as a data sink
-
Another Kafka Connect instance which will host the MongoDB sink connector
-
A service for running the DDD aggregation process we’re going to build in the following
We’ll get to those three in a bit, for now let’s prepare the source side of our pipeline:
export DEBEZIUM_VERSION=0.7
docker-compose up mysql zookeeper kafka connect_sourceOnce all services have been started, register an instance of the Debezium MySQL connector by submitting the following JSON document:
{
"name": "mysql-source",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"database.server.name": "dbserver1",
"table.whitelist": "inventory.customers,inventory.addresses",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"transforms": "unwrap",
"transforms.unwrap.type":"io.debezium.transforms.UnwrapFromEnvelope",
"transforms.unwrap.drop.tombstones":"false"
}
}To do so, run the following curl command:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @mysql-source.jsonThis sets up the connector for the specified database, using the given credentials. For our purposes we’re only interested in changes to the customers and addresses tables, hence the table.whitelist property is given to just select these two tables. Another noteworthy thing is the "unwrap" transform that is applied. By default, Debezium’s CDC events would contain the old and new state of changed rows and some additional metadata on the source of the change. By applying the UnwrapFromEnvelope SMT (single message transformation), only the new state will be propagated into the corresponding Kafka topics.
We can take a look at them once the connector has been deployed and finished its initial snapshot of the two captured tables:
docker-compose exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic dbserver1.inventory.customers # or dbserver1.inventory.addressesE.g. you should see the following output
(formatted and omitting the schema information for the sake of readability) for the topic with customer changes:
{
"schema": { ... },
"payload": {
"id": 1001
}
}
{
"schema": { ... },
"payload": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
}
}
...Building DDD Aggregates
The KStreams application is going to process data from the two Kafka topics. These topics receive CDC events based on the customers and addresses relations found in MySQL, each of which has its corresponding Jackson-annotated POJO (Customer and Address), enriched by a field holding the CDC event type (i.e. UPSERT/DELETE).
Since the Kafka topic records are in Debezium JSON format with unwrapped envelopes, a special SerDe has been written in order to be able to read/write these records using their POJO or Debezium event representation respectively. While the serializer simply converts the POJOs into JSON using Jackson, the deserializer is a "hybrid" one, being able to deserialize from either Debezium CDC events or jsonified POJOs.
With that in place, the KStreams topology to create and maintain DDD aggregates on-the-fly can be built as follows:
Customers Topic ("parent")
All the customer records are simply read from the customer topic into a KTable which will automatically maintain the latest state per customer according to the record key (i.e. the customer’s PK)
KTable<DefaultId, Customer> customerTable =
builder.table(parentTopic, Consumed.with(defaultIdSerde,customerSerde));Addresses Topic ("children")
For the address records the processing is a bit more involved and needs several steps. First, all the address records are read into a KStream.
KStream<DefaultId, Address> addressStream = builder.stream(childrenTopic,
Consumed.with(defaultIdSerde, addressSerde));Second, a 'pseudo' grouping of these address records is done based on their keys (the original primary key in the relation), During this step the relationships towards the corresponding customer records are maintained. This effectively allows to keep track which address record belongs to which customer record, even in the light of address record deletions. To achieve this an additional LatestAddress POJO is introduced which allows to store the latest known PK <→ FK relation in addition to the Address record itself.
KTable<DefaultId,LatestAddress> tempTable = addressStream
.groupByKey(Serialized.with(defaultIdSerde, addressSerde))
.aggregate(
() -> new LatestAddress(),
(DefaultId addressId, Address address, LatestAddress latest) -> {
latest.update(
address, addressId, new DefaultId(address.getCustomer_id()));
return latest;
},
Materialized.<DefaultId,LatestAddress,KeyValueStore<Bytes, byte[]>>
as(childrenTopic+"_table_temp")
.withKeySerde(defaultIdSerde)
.withValueSerde(latestAddressSerde)
);Third, the intermediate KTable is again converted to a KStream. The LatestAddress records are transformed to have the customer id (FK relationship) as their new key in order to group them per customer. During the grouping step, customer specific addresses are updated which can result in an address record being added or deleted. For this purpose, another POJO called Addresses is introduced, which holds a map of address records that gets updated accordingly. The result is a KTable holding the most recent Addresses per customer id.
KTable<DefaultId, Addresses> addressTable = tempTable.toStream()
.map((addressId, latestAddress) ->
new KeyValue<>(latestAddress.getCustomerId(),latestAddress))
.groupByKey(Serialized.with(defaultIdSerde,latestAddressSerde))
.aggregate(
() -> new Addresses(),
(customerId, latestAddress, addresses) -> {
addresses.update(latestAddress);
return addresses;
},
Materialized.<DefaultId,Addresses,KeyValueStore<Bytes, byte[]>>
as(childrenTopic+"_table_aggregate")
.withKeySerde(defaultIdSerde)
.withValueSerde(addressesSerde)
);Combining Customers With Addresses
Finally, it’s easy to bring customers and addresses together by joining the customers KTable with the addresses KTable and thereby building the DDD aggregates which are represented by the CustomerAddressAggregate POJO. At the end, the KTable changes are written to a KStream, which in turn gets saved into a kafka topic. This allows to make use of the resulting DDD aggregates in manifold ways.
KTable<DefaultId,CustomerAddressAggregate> dddAggregate =
customerTable.join(addressTable, (customer, addresses) ->
customer.get_eventType() == EventType.DELETE ?
null :
new CustomerAddressAggregate(customer,addresses.getEntries())
);
dddAggregate.toStream().to("final_ddd_aggregates",
Produced.with(defaultIdSerde,(Serde)aggregateSerde));| Records in the customers KTable might receive a CDC delete event. If so, this can be detected by checking the event type field of the customer POJO and e.g. return 'null' instead of a DDD aggregate. Such a convention can be helpful whenever consuming parties also need to act to deletions accordingly._ |
Running the Aggregation Pipeline
Having implemented the aggregation pipeline, it’s time to give it a test run. To do so, build the poc-ddd-aggregates Maven project which contains the complete implementation:
mvn clean package -f poc-ddd-aggregates/pom.xmlThen run the aggregator service from the Compose file which takes the JAR built by this project and launches it using the java-jboss-openjdk8-jdk base image:
docker-compose up -d aggregatorOnce the aggregation pipeline is running, we can take a look at the aggregated events using the console consumer:
docker-compose exec kafka /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka:9092 \
--from-beginning \
--property print.key=true \
--topic final_ddd_aggregatesTransferring DDD Aggregates to Data Sinks
We originally set out to build these DDD aggregates in order to transfer data and synchronize changes between a data source (MySQL tables in this case) and a convenient data sink. By definition, DDD aggregates are typically complex data structures and therefore it makes perfect sense to write them to data stores which offer flexible ways and means to query and/or index them. Talking about NoSQL databases, a document store seems the most natural choice with MongoDB being the leading database for such use cases.
Thanks to Kafka Connect and numerous turn-key ready connectors it is almost effortless to get this done. Using a MongoDB sink connector from the open-source community, it is easy to have the DDD aggregates written into MongoDB. All it needs is a proper configuration which can be posted to the REST API of Kafka Connect in order to run the connector.
So let’s start MongoDb and another Kafka Connect instance for hosting the sink connector:
docker-compose up -d mongodb connect_sinkIn case the DDD aggregates should get written unmodified into MongoDB, a configuration may look as simple as follows:
{
"name": "mongodb-sink",
"config": {
"connector.class": "at.grahsl.kafka.connect.mongodb.MongoDbSinkConnector",
"tasks.max": "1",
"topics": "final_ddd_aggregates",
"mongodb.connection.uri": "mongodb://mongodb:27017/inventory?w=1&journal=true",
"mongodb.collection": "customers_with_addresses",
"mongodb.document.id.strategy": "at.grahsl.kafka.connect.mongodb.processor.id.strategy.FullKeyStrategy",
"mongodb.delete.on.null.values": true
}
}As with the source connector, deploy the connector using curl:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8084/connectors/ -d @mongodb-sink.jsonThis connector will consume messages from the "final_ddd_aggregates" Kafka topic and write them as MongoDB documents into the "customers_with_addresses" collection.
You can take a look by firing up a Mongo shell and querying the collection’s contents:
docker-compose exec mongodb bash -c 'mongo inventory'
> db.customers_with_addresses.find().pretty(){
"_id": {
"id": "1001"
},
"addresses": [
{
"zip": "76036",
"_eventType": "UPSERT",
"city": "Euless",
"street": "3183 Moore Avenue",
"id": "10",
"state": "Texas",
"customer_id": "1001",
"type": "SHIPPING"
},
{
"zip": "17116",
"_eventType": "UPSERT",
"city": "Harrisburg",
"street": "2389 Hidden Valley Road",
"id": "11",
"state": "Pennsylvania",
"customer_id": "1001",
"type": "BILLING"
}
],
"customer": {
"_eventType": "UPSERT",
"last_name": "Thomas",
"id": "1001",
"first_name": "Sally",
"email": "sally.thomas@acme.com"
}
}Due to the combination of the data in a single document some parts aren’t needed or redundant. To get rid of any unwanted data (e.g. _eventType, customer_id of each address sub-document) it would also be possible to adapt the configuration in order to blacklist said fields.
Finally, you update some customer or address data in the MySQL source database:
docker-compose exec mysql bash -c 'mysql -u $MYSQL_USER -p$MYSQL_PASSWORD inventory'
mysql> update customers set first_name= "Sarah" where id = 1001;Shortly thereafter, you should see that the corresponding aggregate document in MongoDB has been updated accordingly.
Drawbacks and Limitations
While this first version for creating DDD aggregates from table-based CDC events basically works, it is very important to understand its current limitations:
-
not generically applicable thus needs custom code for POJOs and intermediate types
-
cannot be scaled across multiple instances as is due to missing but necessary data repartitioning prior to processing
-
limited to building aggregates based on a single JOIN between 1:N relationships
-
resulting DDD aggregates are eventually consistent, meaning that it is possible for them to temporarily exhibit intermediate state before converging
The first few can be addressed with a reasonable amount of work on the KStreams application. The last one, dealing with the eventually consistent nature of resulting DDD aggregates is much harder to correct and will require some efforts at Debezium’s own CDC mechanism.
Outlook
In this post we described an approach for creating aggregated events from Debezium’s CDC events. In a follow-up blog post we may dive a bit more into the topic of how to be able to horizontally scale the DDD creation by running multiple KStreams aggregator instances. For that purpose, the data needs proper re-partitioning before running the topology. In addition, it could be interesting to look into a somewhat more generic version which only needs custom classes to the describe the two main POJOs involved.
We also thought about providing a ready-to-use component which would work in a generic way (based on Connect records, i.e. not tied to a specific serialization format such as JSON) and could be set up as a configurable stand-alone process running given aggregations.
Also on the topic of dealing with eventual consistency we got some ideas, but those will need some more exploration and investigation for sure. Stay tuned!
We’d love to hear about your feedback on the topic of event aggreation. If you got any ideas or thoughts on the subject, please get in touch by posting a comment below or sending a message to our mailing list.

Gunnar Morling
Gunnar is a software engineer and open-source enthusiast by heart, currently working as a Technologist at Confluent. Previously, he helped to build a realtime stream processing platform based on Apache Flink and led the Debezium project, a distributed platform for change data capture. He is a Java Champion and has founded multiple open source projects such as JfrUnit, kcctl, and MapStruct. Gunnar is an avid blogger (morling.dev) and has spoken at various conferences like QCon, Java One, and Devoxx. He lives in Hamburg, Germany.

About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.