
It is a common requirement for business applications to maintain some form of audit log, i.e. a persistent trail of all the changes to the application’s data. If you squint a bit, a Kafka topic with Debezium data change events is quite similar to that: sourced from database transaction logs, it describes all the changes to the records of an application. What’s missing though is some metadata: why, when and by whom was the data changed? In this post we’re going to explore how that metadata can be provided and exposed via change data capture (CDC), and how stream processing can be used to enrich the actual data change events with such metadata.
Reasons for maintaining data audit trails are manyfold: e.g. regulatory requirements may mandate businesses to keep complete historic information of their customer, purchase order, invoice or other data. Also for an enterprise’s own purposes it can be very useful to have insight into why and how certain data has changed, e.g. allowing to improve business processes or analyze errors.
One common approach for creating audit trails are application-side libraries. Hooked into the chosen persistence library, they’d maintain specific column(s) in the data tables ("createdBy", "lastUpdated" etc.), and/or copy earlier record versions into some form of history tables.
There are some disadvantages to this, though:
-
writing records in history tables as part of OLTP transactions increases the number of executed statements within the transaction (for each update or delete, also an insert must be written into the corresponding history table) and thus may cause longer response times of the application
-
oftentimes no audit events can be provided in case of bulk updates and deletes (e.g.
DELETE from purchaseorders where status = 'SHIPPED'), as the listeners used to hook the library into the persistence framework are not aware of all the affected records -
changes done directly in the database cannot be tracked, e.g. when running a data load, doing batch processing in a stored procedure or when bypassing the application during an emergency data patch
Another technique are database triggers. They won’t miss any operations, no matter whether issued from the application or the database itself. They’ll also be able to process each record affected by a bulk statement. On the downside, there’s still is the problem of increased latency when executing triggers as part of OLTP transactions. Also, a process must be in place for installing and updating the triggers for each table.
Audit Logs Based on Change Data Capture
The aforementioned problems don’t exist when leveraging the transaction log as the source for an audit trail and using change data capture for retrieving the change information and sending it into a message broker or log such as Apache Kafka.
Running asynchronously, the CDC process can extract the change data without impacting OLTP transactions. The transaction logs contain one entry whenever there’s a data change, be it issued from the application or directly executed in the database. There’ll be a log entry for each record updated or deleted in a bulk operation, so a change event for each of them can be produced. Also there is no impact on the data model, i.e. no special columns or history tables must be created.
But how can CDC access the metadata we’d discussed initially? This could for instance be data such as the application user that performed a data change, their IP address and device configuration, a tracing span id, or an identifier for the application use case.
As that metadata typically isn’t (nor shouldn’t) be stored in the actual business tables of an application, it must be provided separately. One approach is to have a separate table where this metadata is stored. For each executed transaction, the business application produces one record in that table, containing all the required metadata and using the transaction id as a primary key. When running manual data changes, it is easy to also provide the metadata record with an additional insert. As Debezium’s data change events contain the id of the transaction causing the specific change, the data change events and the metadata records can be correlated.
In the remainder of this post we’re going to take a closer look at how a business application can provide the transaction-scoped metadata and how data change events can be enriched with the corresponding metadata using the Kafka Streams API.
Solution Overview
The following image shows the overall solution design, based on the example of a microservice for managing vegetable data:
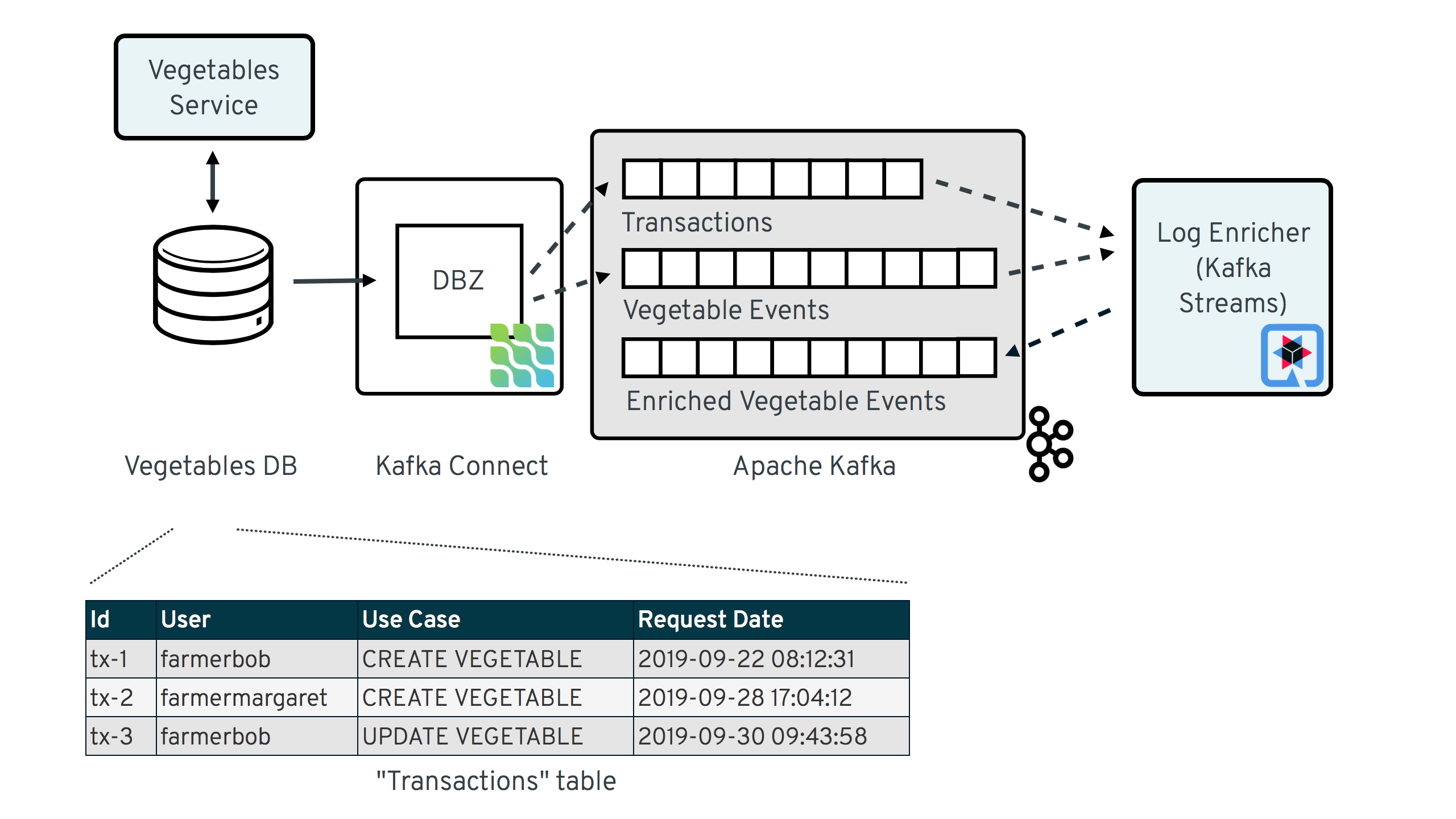
There are two services involved:
-
vegetables-service: a simple REST service for inserting and updating vegetable data into a Postgres database; as part of its processing, it will not only update its actual "business table"
vegetable, but also insert some auditing metadata into a dedicated metadata tabletransaction_context_data; Debezium is used to stream change events from the two tables into corresponding topics in Apache Kafka -
log-enricher: a stream processing application built with Kafka Streams and Quarkus, which enriches the messages from the CDC topic containing the vegetable change events (
dbserver1.inventory.vegetable) with the corresponding metadata in thedbserver1.inventory.transaction_context_datatopic and writes the enriched vegetable change event back to Kafka into thedbserver1.inventory.vegetable.enrichedtopic.
You can find a complete example with all the components and instructions for running them on GitHub.
Providing Auditing Metadata
Let’s first discuss how an application such as the vegetable service can provide the required auditing metadata. As an example, the following metadata should be made available for auditing purposes:
-
The application user that did a data change, as represented by the
subclaim of a JWT token (JSON Web Token) -
The request timestamp, as represented by the
DateHTTP header -
A use case identifier, as provided via a custom Java annotation on the invoked REST resource method
Here is a basic implementation of a REST resource for persisting a new vegetable using the JAX-RS API:
@Path("/vegetables")
@RequestScoped
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
public class VegetableResource {
@Inject
VegetableService vegetableService;
@POST
@RolesAllowed({"farmers"})
@Transactional
@Audited(useCase="CREATE VEGETABLE")
public Response createVegetable(Vegetable vegetable) {
if (vegetable.getId() != null) {
return Response.status(Status.BAD_REQUEST.getStatusCode()).build();
}
vegetable = vegetableService.createVegetable(vegetable);
return Response.ok(vegetable).status(Status.CREATED).build();
}
// update, delete ...
}If you’ve ever built REST services with JAX-RS before, the implementation will look familiar to you: a resource method annotated with @POST takes the incoming request payload and passes it to a service bean which is injected via CDI. The @Audited annotation is special, though. It is a custom annotation type which serves two purposes:
-
Specifying the use case that should be referenced in the audit log ("CREATE VEGETABLE")
-
Binding an interceptor which will be triggered for each invocation of a method annotated with
@Audited
That interceptor kicks in whenever a method annotated with @Audited is invoked and implements the logic for writing the transaction-scoped audit metadata. It looks like this:
@Interceptor (1)
@Audited(useCase = "")
@Priority(value = Interceptor.Priority.APPLICATION + 100) (2)
public class TransactionInterceptor {
@Inject
JsonWebToken jwt; (3)
@Inject
EntityManager entityManager;
@Inject
HttpServletRequest request;
@AroundInvoke
public Object manageTransaction(InvocationContext ctx) throws Exception {
BigInteger txtId = (BigInteger) entityManager (4)
.createNativeQuery("SELECT txid_current()")
.getSingleResult();
String useCase = ctx.getMethod().getAnnotation(Audited.class).useCase();
TransactionContextData context = new TransactionContextData(); (5)
context.transactionId = txtId.longValueExact();
context.userName = jwt.<String>claim("sub").orElse("anonymous");
context.clientDate = getRequestDate();
context.useCase = useCase;
entityManager.persist(context);
return ctx.proceed(); (6)
}
private ZonedDateTime getRequestDate() {
String requestDate = request.getHeader(HttpHeaders.DATE);
return requestDate != null ?
ZonedDateTime.parse(requestDate, DateTimeFormatter.RFC_1123_DATE_TIME) :
null;
}
}| 1 | @Interceptor and @Audited mark this as an interceptor bound to our custom @Audited annotion. |
| 2 | The @Priority annotation controls at which point in the interceptor stack the auditing interceptor should be invoked. Any application-provided interceptors should have a priority larger than Priority.APPLICATION (2000); in particular, this ensures that a transaction will have been started before by means of the @Transactional annotation and its accompanying interceptor which run in the Priority.PLATFORM_BEFORE range (< 1000). |
| 3 | The caller’s JWT token injected via the MicroProfile JWT RBAC API |
For each audited method the interceptor fires and will
-
obtain the current transaction id (the exact way for doing so is database-specific, in the example the
txid_current()function from Postgres is called) -
persist a
TransactionContextDataentity via JPA; its primary key value is the transaction id selected before, and it has attributes for the user name (obtained from the JWT token), the request date (obtained from theDATEHTTP request header) and the use case identifier (obtained from the@Auditedannotation of the invoked method) -
continue the call flow of the invoked method
When invoking the REST service to create and update a few vegetables, the following records should be created in the database (refer to the README in the provided example for instructions on building the example code and invoking the vegetable service with a suitable JWT token):
vegetablesdb> select * from inventory.vegetable;
+------+---------------+---------+
| id | description | name |
|------+---------------+---------|
| 1 | Spicy! | Potato |
| 11 | Delicious! | Pumpkin |
| 10 | Tasty! | Tomato |
+------+---------------+---------+vegetablesdb> select * from inventory.transaction_context_data;
+------------------+---------------------+------------------+----------------+
| transaction_id | client_date | usecase | user_name |
|------------------+---------------------+------------------+----------------|
| 608 | 2019-08-22 08:12:31 | CREATE VEGETABLE | farmerbob |
| 609 | 2019-08-22 08:12:31 | CREATE VEGETABLE | farmerbob |
| 610 | 2019-08-22 08:12:31 | UPDATE VEGETABLE | farmermargaret |
+------------------+---------------------+------------------+----------------+Enriching Change Events with Auditing Metadata
With the business data (vegetables) and the transaction-scoped metadata being stored in the database, it’s time to set up the Debezium Postgres connector and stream the data changes from the vegetable and transaction_context_data tables into corresponding Kafka topics. Again refer to the example README file for the details of deploying the connector.
The dbserver1.inventory.vegetable topic should contain change events for created, updated and deleted vegetable records, whereas the dbserver1.inventory.transaction_context_data topic should only contain create messages for each inserted metadata record.
| Topic Retention In order to manage the growth of involved topics, the retention policy for each topic should be well-defined. For instance for the actual audit log topic with the enriched change events, a time based retention policy might be suitable, keeping each log event for as long as needed as per your requirements. The transaction metadata topic on the other hand can be fairly short-lived, as its entries are not needed any longer, once all corresponding data change events have been processed. It may be a good idea to set up some monitoring of the end-to-end lag in order to make sure the log enricher stream application keeps up with the incoming messages and doesn’t fall behind that far so it is at risk of transaction messages being discarded before processing the corresponding change events. |
Now, if we look at messages from the two topics, we can see that they can be correlated based on the transaction id. It is part of the source structure of vegetable change events, and it is the message key of transaction metadata events:

Once we’ve found the corresponding transaction event for a given vegetable change event, the client_date, usecase and user_name attributes from the former can be added to the latter:
This kind of message transformation is a perfect use case for Kafka Streams, a Java API for implementing stream processing applications on top of Kafka topics, providing operators that let you filter, transform, aggregate and join Kafka messages.
As runtime environment for our stream processing application we’re going to use Quarkus, which is "a Kubernetes Native Java stack tailored for GraalVM & OpenJDK HotSpot, crafted from the best of breed Java libraries and standards".
| Building Kafka Streams Applications with Quarkus Amongst many others, Quarkus comes with an extension for Kafka Streams, which allows to build stream processing applications running on the JVM and as native code compiled ahead-of-time. It takes care of the lifecycle of the streaming topology, so you don’t have to deal with details like registering JVM shutdown hooks, awaiting the creation of all input topics and more. The extension also comes with "live development" support, which automatically reloads the stream processing application while you’re working on it, allowing for very fast turnaround cycles during development. |
The Joining Logic
When thinking about the actual implementation of the enrichment logic, a stream-to-stream join might appear as a suitable solution. By creating KStreams for the two topics, we may try and implement the joining functionality. One challenge though is how to define a suitable joining window, as there is no timing guarantees between messages on the two topics, and we must not miss any event.
Another problem arises in regards to ordering guarantees of the change events. By default, Debezium will use a table’s primary key as the message key for the corresponding Kafka messages. This means that all messages for the same vegetable record will have the same key and thus will go into the same partition of the vegetables Kafka topic. This in turn guarantees that a consumer of these events sees all the messages pertaining to the same vegetable record in the exact same order as they were created.
Now, in order to join the two streams, the message key must be the same on both sides. This means the vegetables topic must be re-keyed by transaction id (we cannot re-key the transaction metadata topic, as there’s no information about concerned vegetables contained in the metadata events; and even if that were the case, one transaction might impact multiple vegetable records). By doing so, we’d loose the original ordering guarantees, though. One vegetable record might be modified in two subsequent transactions, and its change events may end up in different partitions of the re-keyed topic, which may cause a consumer to receive the second change event before the first one.
If a KStream-KStream join isn’t feasible, what else could be done? A join between a KStream and GlobalKTable looks promising, too. It doesn’t have the co-partitioning requirements of stream-to-stream joins, as all partitions of the GlobalKTable are present on all nodes of a distributed Kafka Streams application. This seems like an acceptable trade-off, because the messages from the transaction metadata topic can be discarded rather quickly and the size of the corresponding table should be within reasonable bounds. So we could have a KStream sourced from the vegetables topic and a GlobalKTable based on the transaction metadata topic.
But unfortunately, there is a timing issue: as the messages are consumed from multiple topics, it may happen that at the point in time when an element from the vegetables stream is processed, the corresponding transaction metadata message isn’t available yet. So depending on whether we’d be using an inner join or a left join, we’d in this case either skip change events or propagate them without having enriched them with the transaction metadata. Both outcomes are not desirable.
Customized Joins With Buffering
The combination of KStream and GlobalKTable still hints into the right direction. Only that instead of relying on the built-in join operators we’ll have to implement a custom joining logic. The basic idea is to buffer messages arriving on the vegetable KStream until the corresponding transaction metadata message is available from the GlobalKTables state store. This can be achieved by creating a custom transformer which implements the required buffering logic and is applied to the vegetable KStream.
Let’s begin with the streaming topology itself. Thanks to the Quarkus Kafka Streams extension, a CDI producer method returning the Topology object is all that’s needed for that:
@ApplicationScoped
public class TopologyProducer {
static final String STREAM_BUFFER_NAME = "stream-buffer-state-store";
static final String STORE_NAME = "transaction-meta-data";
@ConfigProperty(name = "audit.context.data.topic")
String txContextDataTopic;
@ConfigProperty(name = "audit.vegetables.topic")
String vegetablesTopic;
@ConfigProperty(name = "audit.vegetables.enriched.topic")
String vegetablesEnrichedTopic;
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder();
StoreBuilder<KeyValueStore<Long, JsonObject>> streamBufferStateStore =
Stores
.keyValueStoreBuilder(
Stores.persistentKeyValueStore(STREAM_BUFFER_NAME),
new Serdes.LongSerde(),
new JsonObjectSerde()
)
.withCachingDisabled();
builder.addStateStore(streamBufferStateStore); (1)
builder.globalTable(txContextDataTopic, Materialized.as(STORE_NAME)); (2)
builder.<JsonObject, JsonObject>stream(vegetablesTopic) (3)
.filter((id, changeEvent) -> changeEvent != null)
.filter((id, changeEvent) -> !changeEvent.getString("op").equals("r"))
.transform(() -> new ChangeEventEnricher(), STREAM_BUFFER_NAME)
.to(vegetablesEnrichedTopic);
return builder.build();
}
}| 1 | State store which will serve as the buffer for change events that cannot be processed yet |
| 2 | GlobalKTable based on the transaction metadata topic |
| 3 | KStream based on the vegetables topic; on this stream, any incoming tombstone markers are filtered, the reasoning being that the retention policy for an audit trail topic typically should be time-based than based on log compaction; similarly, snapshot events are filtered, assuming they are not relevant for an audit trail and there wouldn’t be any corresponding metadata provided by the application for the snapshot transaction initiated by the Debezium connector Any other messages are enriched with the corresponding transaction metadata via a custom |
The topic names are injected using the MicroProfile Config API, with the values being provided in Quarkus application.properties configuration file. Besides the topic names, this file also has the information about the Kafka bootstrap server, default serdes any more:
audit.context.data.topic=dbserver1.inventory.transaction_context_data
audit.vegetables.topic=dbserver1.inventory.vegetable
audit.vegetables.enriched.topic=dbserver1.inventory.vegetable.enriched
# may be overridden with env vars
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-id=auditlog-enricher
quarkus.kafka-streams.topics=${audit.context.data.topic},${audit.vegetables.topic}
# pass-through
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUG
kafka-streams.default.key.serde=io.debezium.demos.auditing.enricher.JsonObjectSerde
kafka-streams.default.value.serde=io.debezium.demos.auditing.enricher.JsonObjectSerde
kafka-streams.processing.guarantee=exactly_onceIn the next step let’s take a look at the ChangeEventEnricher class, our custom transformer. The implemention is based on the assumption that change events are serialized as JSON, but of course it could be done equally well using other formats such as Avro or Protocol Buffers.
This is a bit of code, but hopefully its decomposition into multiple smaller methods makes it comprehensible:
class ChangeEventEnricher implements Transformer
<JsonObject, JsonObject, KeyValue<JsonObject, JsonObject>> {
private static final Long BUFFER_OFFSETS_KEY = -1L;
private static final Logger LOG = LoggerFactory.getLogger(ChangeEventEnricher.class);
private ProcessorContext context;
private KeyValueStore<JsonObject, JsonObject> txMetaDataStore;
private KeyValueStore<Long, JsonObject> streamBuffer; (5)
@Override
@SuppressWarnings("unchecked")
public void init(ProcessorContext context) {
this.context = context;
streamBuffer = (KeyValueStore<Long, JsonObject>) context.getStateStore(
TopologyProducer.STREAM_BUFFER_NAME
);
txMetaDataStore = (KeyValueStore<JsonObject, JsonObject>) context.getStateStore(
TopologyProducer.STORE_NAME
);
context.schedule(
Duration.ofSeconds(1),
PunctuationType.WALL_CLOCK_TIME, ts -> enrichAndEmitBufferedEvents()
); (4)
}
@Override
public KeyValue<JsonObject, JsonObject> transform(JsonObject key, JsonObject value) {
boolean enrichedAllBufferedEvents = enrichAndEmitBufferedEvents(); (3)
if (!enrichedAllBufferedEvents) {
bufferChangeEvent(key, value);
return null;
}
KeyValue<JsonObject, JsonObject> enriched = enrichWithTxMetaData(key, value); (1)
if (enriched == null) { (2)
bufferChangeEvent(key, value);
}
return enriched;
}
/**
* Enriches the buffered change event(s) with the metadata from the associated
* transactions and forwards them.
*
* @return {@code true}, if all buffered events were enriched and forwarded,
* {@code false} otherwise.
*/
private boolean enrichAndEmitBufferedEvents() { (3)
Optional<BufferOffsets> seq = bufferOffsets();
if (!seq.isPresent()) {
return true;
}
BufferOffsets sequence = seq.get();
boolean enrichedAllBuffered = true;
for(long i = sequence.getFirstValue(); i < sequence.getNextValue(); i++) {
JsonObject buffered = streamBuffer.get(i);
LOG.info("Processing buffered change event for key {}",
buffered.getJsonObject("key"));
KeyValue<JsonObject, JsonObject> enriched = enrichWithTxMetaData(
buffered.getJsonObject("key"), buffered.getJsonObject("changeEvent"));
if (enriched == null) {
enrichedAllBuffered = false;
break;
}
context.forward(enriched.key, enriched.value);
streamBuffer.delete(i);
sequence.incrementFirstValue();
}
if (sequence.isModified()) {
streamBuffer.put(BUFFER_OFFSETS_KEY, sequence.toJson());
}
return enrichedAllBuffered;
}
/**
* Adds the given change event to the stream-side buffer.
*/
private void bufferChangeEvent(JsonObject key, JsonObject changeEvent) { (2)
LOG.info("Buffering change event for key {}", key);
BufferOffsets sequence = bufferOffsets().orElseGet(BufferOffsets::initial);
JsonObject wrapper = Json.createObjectBuilder()
.add("key", key)
.add("changeEvent", changeEvent)
.build();
streamBuffer.putAll(Arrays.asList(
KeyValue.pair(sequence.getNextValueAndIncrement(), wrapper),
KeyValue.pair(BUFFER_OFFSETS_KEY, sequence.toJson())
));
}
/**
* Enriches the given change event with the metadata from the associated
* transaction.
*
* @return The enriched change event or {@code null} if no metadata for the
* associated transaction was found.
*/
private KeyValue<JsonObject, JsonObject> enrichWithTxMetaData(JsonObject key,
JsonObject changeEvent) { (1)
JsonObject txId = Json.createObjectBuilder()
.add("transaction_id", changeEvent.get("source").asJsonObject()
.getJsonNumber("txId").longValue())
.build();
JsonObject metaData = txMetaDataStore.get(txId);
if (metaData != null) {
LOG.info("Enriched change event for key {}", key);
metaData = Json.createObjectBuilder(metaData.get("after").asJsonObject())
.remove("transaction_id")
.build();
return KeyValue.pair(
key,
Json.createObjectBuilder(changeEvent)
.add("audit", metaData)
.build()
);
}
LOG.warn("No metadata found for transaction {}", txId);
return null;
}
private Optional<BufferOffsets> bufferOffsets() {
JsonObject bufferOffsets = streamBuffer.get(BUFFER_OFFSETS_KEY);
if (bufferOffsets == null) {
return Optional.empty();
}
else {
return Optional.of(BufferOffsets.fromJson(bufferOffsets));
}
}
@Override
public void close() {
}
}| 1 | When a vegetables change event arrives, look up the corresponding metadata in the state store of the transaction topic’s GlobalKTable, using the transaction id from the source block of the change event as the key; if the metadata could be found, add the metadata to change event (under the audit field) and return that enriched event |
| 2 | If the metadata could not be found, add the incoming event into the buffer of change events and return |
| 3 | Before actually getting to the incoming event, all buffered events are processed; this is required to make sure that the original change events is retained; only if all could be enriched, the incoming event will be processed, too |
| 4 | In order to emit buffered events also if no new change event is coming in, a punctuation is scheduled that periodically processes the buffer |
| 5 | A buffer for vegetable events whose corresponding metadata hasn’t arrived yet |
The key piece is the buffer for unprocessable change events. To maintain the order of events, the buffer must be processed in order of insertion, beginning with the event inserted first (think of a FIFO queue). As there’s no guaranteed traversing order when getting all the entries from a KeyValueStore, this is implemented by using the values of a strictly increasing sequence as the keys. A special entry in the key value store is used to store the information about the current "oldest" index in the buffer and the next sequence value.
One could also think of alternative implementations for such buffer, e.g. based on a Kafka topic or a custom KeyValueStore implementation that ensures iteration order from oldest to newest entry. Ultimately, it could also be useful if Kafka Streams came with built-in means of retrying a stream element that cannot be joined yet; this would avoid any custom buffering implementation.
| If Things Go Wrong For a reliable and consistent processing logic it’s vital to think about the behavior in case of failures, e.g. if the stream application crashes after adding an element to the buffer but before updating the sequence value. The key to this is the Consumers of the enriched vegetable events should apply an isolation level of |
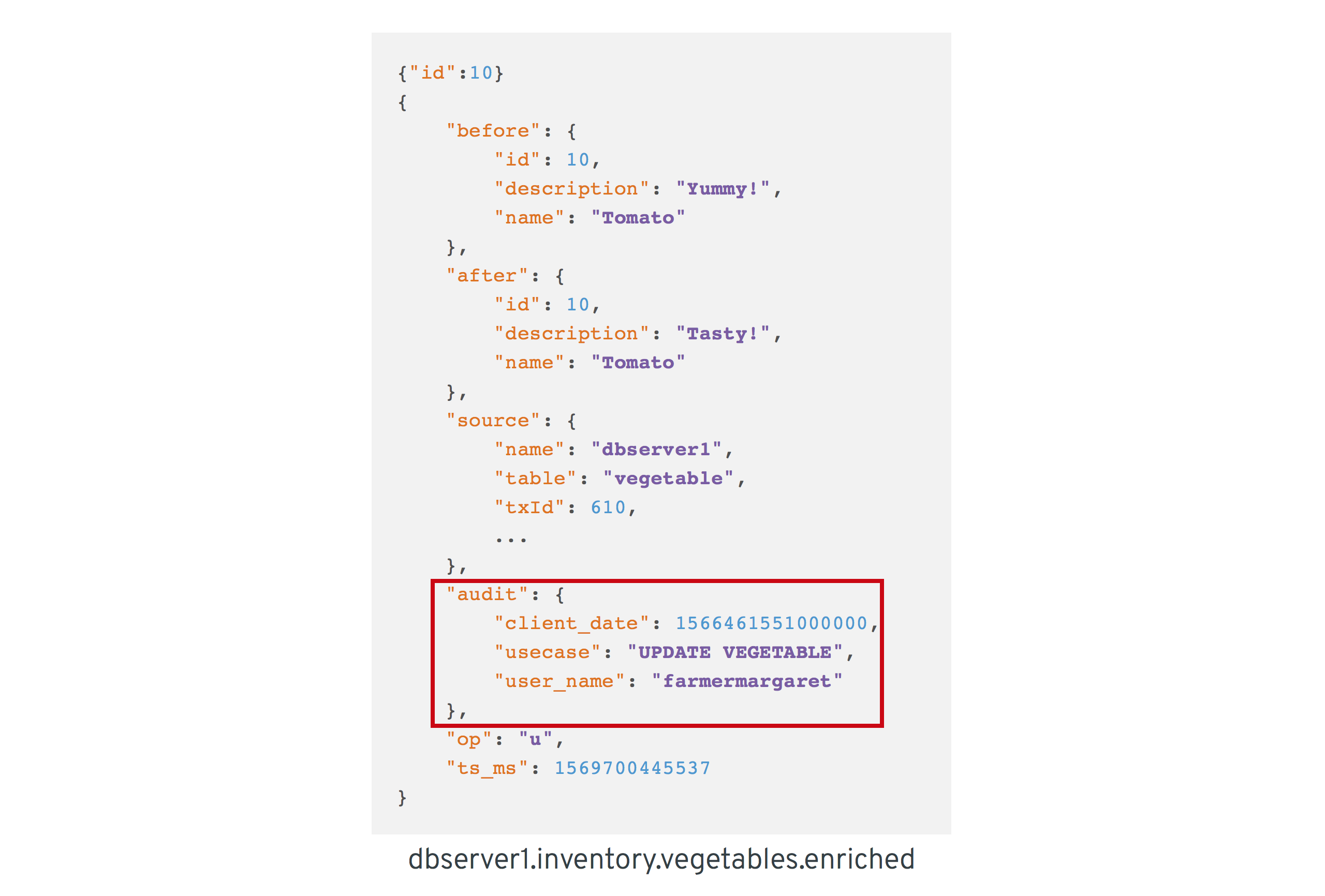
With the custom transformer logic in place, we can build the Quarkus project and run the stream processing application. You should see messages like this in the dbserver1.inventory.vegetable.enriched topic:
{"id":10}
{
"before": {
"id": 10,
"description": "Yummy!",
"name": "Tomato"
},
"after": {
"id": 10,
"description": "Tasty!",
"name": "Tomato"
},
"source": {
"version": "0.10.0-SNAPSHOT",
"connector": "postgresql",
"name": "dbserver1",
"ts_ms": 1569700445392,
"snapshot": "false",
"db": "vegetablesdb",
"schema": "inventory",
"table": "vegetable",
"txId": 610,
"lsn": 34204240,
"xmin": null
},
"op": "u",
"ts_ms": 1569700445537,
"audit": {
"client_date": 1566461551000000,
"usecase": "UPDATE VEGETABLE",
"user_name": "farmermargaret"
}
}Of course, the buffer processing logic may be adjusted as per your specific requirements; for instance instead of indefinitely waiting for corresponding transaction metadata, we may also decide that it makes more sense to propagate change events unenriched after some waiting time or to raise an exception indicating the missing metadata.
In order to see whether the buffering works as expected, you could do a small experiment: modify a vegetable record using SQL directly in the database. Debezium will capture the event, but as there’s no corresponding transaction metadata provided, the event will not be forwarded to the enriched vegetables topic. If you add another vegetable using the REST API, this one also will not be propagated: although there is a metadata record for it, it’s blocked by the other change event. Only once you have inserted a metadata record for the first change’s transaction into the transaction_context_data table, both change events will be processed and sent to the output topic.
Summary
In this blog post we’ve discussed how change data capture in combination with stream processing can be used to build audit logs in an efficient, low-overhead way. In contrast to library and trigger-based approaches, the events that form the audit trail are retrieved via CDC from the database’s transaction logs, and apart from the insertion of a single metadata record per transaction (which in similar form would be required for any kind of audit log), no overhead to OLTP transactions is incurred. Also audit log entries can be obtained when data records are subject to bulk updates or deletes, something typically not possible with library-based auditing solutions.
Additional metadata that typically should be part of an audit log, can be provided by the application via a separate table, which also is captured via Debezium. With the help of Kafka Streams the actual data change events can be enriched with the data from that metadata table.
One aspect we haven’t discussed yet is querying the audit trail entries, e.g. to examine specific earlier versions of the data. To do so, the enriched change data events typically would be stored in a queryable database. Unlike a basic data replication pipeline, not only the latest version of each record would be stored in the database in that case, but all the versions, i.e. the primary keys typically would be amended with the transaction id of each change. This would allow to select single data records or even joins of multiple tables to get the data valid as per a given transaction id. How this could be implemented in detail may be discussed in a future post.
Your feedback on this approach for building audit logs is very welcomed, just post a comment below. To get started with your own implementation, you can check out the code in the Debezium examples repository on GitHub.
Many thanks to Chris Cranford, Hans-Peter Grahsl, Ashhar Hasan, Anna McDonald and Jiri Pechanec for their feedback while working on this post and the accompanying example code!
Gunnar Morling
Gunnar is a software engineer and open-source enthusiast by heart, currently working as a Technologist at Confluent. Previously, he helped to build a realtime stream processing platform based on Apache Flink and led the Debezium project, a distributed platform for change data capture. He is a Java Champion and has founded multiple open source projects such as JfrUnit, kcctl, and MapStruct. Gunnar is an avid blogger (morling.dev) and has spoken at various conferences like QCon, Java One, and Devoxx. He lives in Hamburg, Germany.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.