
This post originally appeared on the Bolt Labs Engineering blog.
Traditionally, MySQL has been used to power most of the backend services at Bolt. We’ve designed our schemas in a way that they’re sharded into different MySQL clusters. Each MySQL cluster contains a subset of data and consists of one primary and multiple replication nodes.
Once data is persisted to the database, we use the Debezium MySQL Connector to capture data change events and send them to Kafka. This gives us an easy and reliable way to communicate changes between back-end microservices.
Vitess at Bolt
Bolt has grown considerably over the past few years, and so did the volume of data written to MySQL. Manual database sharding has become quite an expensive and long-lasting process prone to errors. So we started to evaluate more scalable databases, one of which is Vitess. Vitess is an open-source database clustering system that is based on MySQL and provides horizontal scalability for it. Originated and battle-tested at YouTube, it was later open-sourced and is used by companies like Slack, Github, JD.com to power their backend storage. It combines important MySQL features with the scalability of a NoSQL database.
One of the most important features that Vitess provides is its built-in sharding. It allows the database to grow horizontally by adding new shards in a way that is transparent to back-end application logic. To your application, Vitess appears like a giant single database, but in fact data is partitioned into multiple physical shards behind the scenes. For any table, an arbitrary column can be chosen as the sharding key, and all inserts and updates will be seamlessly directed to a proper shard by Vitess itself.
Figure 1 below illustrates how back-end services interact with Vitess. At a high level, services connect to the stateless VTGate instances through a load balancer. Each VTGate has the Vitess cluster’s topology cached in its memory and redirects queries to the correct shards and the correct VTTablet (and its underlying MySQL instance) within the shards. More on VTTablet is written below.
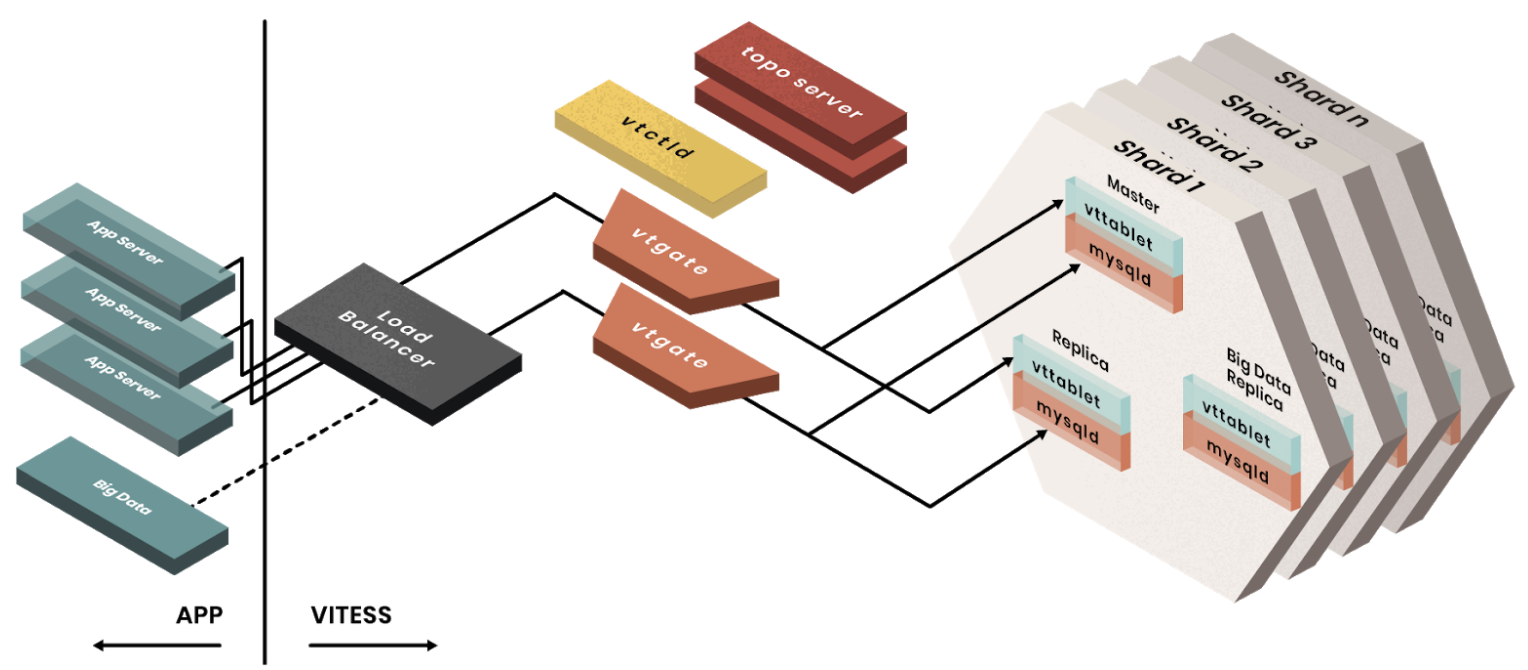
Figure 1. Vitess architecture. Reference: https://www.planetscale.com/vitess
Other useful features provided by Vitess are:
-
Failover (a.k.a. Reparenting) is easy and transparent for clients. Clients only talk to a VTGate who takes care of failover and service discovery of the new primary transparently.
-
It automatically rewrites “problematic” queries that could potentially cause database performance degradation.
-
It has a caching mechanism that prevents duplicate queries to reach the underlying MySQL database simultaneously. Only one query will reach the database and its result will be cached and returned to answer duplicate queries.
-
It has its connection pool and eliminates the high-memory overhead of MySQL connections. As a result, it can easily handle thousands of connections at the same time.
-
Connection timeout and transaction timeout can be configured.
-
It has minimal downtime when doing resharding operations.
-
Its VStream feature can be used by downstream CDC applications to read change events from Vitess.
Streaming Vitess Options
The ability to capture data changes and publish them to Apache Kafka was one of the requirements for adopting Vitess at Bolt. There were several different options we’ve considered.
Option 1: Using Debezium MySQL Connector
Applications connect to Vitess VTGate to send queries. VTGate supports the MySQL protocol and has a SQL parser. You can use any MySQL client (e.g. JDBC) to connect to VTGate, which redirects your query to the correct shard and returns the result to your client.
However, VTGate is not equal to a MySQL instance, it is rather a stateless proxy to various MySQL instances. For the MySQL connector to receive change events, the Debezium MySQL connector needs to connect to a real MySQL instance. To make it more obvious, VTGate also has some known compatibility issues, which makes connecting to VTGate different from MySQL.
Another option is to use the Debezium MySQL Connector to connect directly to the underlying MySQL instances of different shards. It has its advantages and disadvantages.
One advantage is that for an unsharded keyspace (Vitess’s terminology for a database), the MySQL Connector can continue to work correctly and we don’t need to include additional logic or specific implementation. It should just work fine.
One of the biggest disadvantages is that resharding operations would become more complex. For example, the GTID of the original MySQL instance would change when resharded, and the MySQL connector depends on the GTID to work correctly. We also believe that having the MySQL connector connected directly to each underlying MySQL instance defies the purpose of Vitess’s operational simplicity as a new connector has to be added (or removed) each time resharding is done. Not to mention that such operation would lead to data duplication inside Kafka brokers.
Option 2: Using JDBC Source Connector
We’ve also considered using the JDBC Source Connector. It allows sourcing data from any relational databases that support the JDBC driver into Kafka. Therefore, it is compatible with Vitess VTGate. It has its advantages and disadvantages as well.
Advantages:
-
It is compatible with VTGate.
-
It handles Vitess resharding operation better. During resharding operation, reads are simply automatically redirected (by VTGate) to the target shards. It won’t generate any duplicates or lose any data.
Disadvantages:
-
It is poll-based, meaning that the connector polls the database for new change events on a defined interval (typically every few seconds). This means that we would have a much higher latency, compared to the Debezium MySQL Connector.
-
Its offsets are managed by either the table’s incremental primary key or one of the table’s timestamp columns. If we use the timestamp column for offset, we’d have to create a secondary-index of the timestamp column for each table. This adds more constraints on our backend services. If we use the incremental primary key, we would miss the change events for row-updates because the primary key is simply not updated.
-
The topic name created by the JDBC connector doesn’t include the table’s schema name. Using the
topic.prefixconnector configuration would mean that we’ll have one connector per schema. At Bolt, we have a large number of schemas, which means we would need to create a large number of JDBC Source Connectors. -
At Bolt, our downstream applications are already set up to use Debezium’s data formats and topic naming conventions, e.g. we’d need to change our downstream application’s decoding logic to the new data formats.
-
Row deletes are not captured.
Option 3: Using VStream gRPC
VTGate exposes a gRPC service called VStream. It is a server-side streaming service. Any gRPC client can subscribe to the VStream service to get a continuous stream of change events from the underlying MySQL instances. The change events that VStream emits have similar information to the MySQL binary logs of the underlying MySQL instances. A single VStream can even subscribe to multiple shards for a given keyspace, making it quite a convenient API to build CDC tools.
Behind the scene, as shown in Figure 2, VStream reads change events from multiple VTTablets, one VTTablet per shard. Therefore, it doesn’t send duplicates from multiple VTTablets for a given shard. Each VTTablet is a proxy to its MySQL instance. A typical topology would include one master VTTablet and its corresponding MySQL instance, and multiple replica VTTablets, each of which is the proxy of its own replica MySQL instance. A VTTablet gets change events from its underlying MySQL instance and sends the change events back to VTGate, which in turn sends the change events back to VStream’s gRPC client.
When subscribing to the VStream service, the client can specify a VGTID and Tablet Type (e.g. MASTER, REPLICA). The VGTID tells the position from which VStream starts to send change events. Essentially, VGTID includes a list of (keyspace, shard, shard GTID) tuples. The Tablet Type tells which MySQL instance (primary or replica) in each shard do we read change events from.
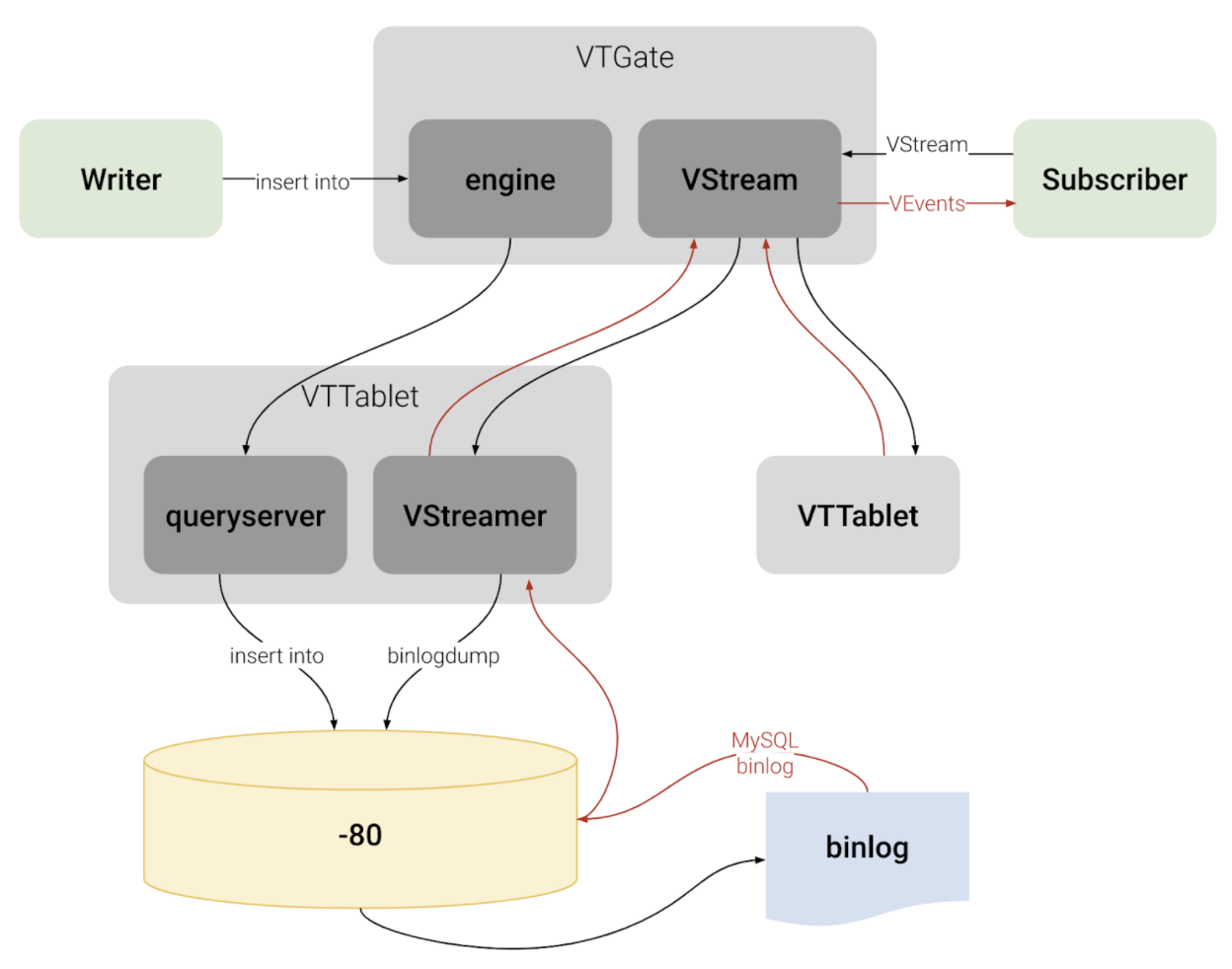
Figure 2. VStream architecture. Reference: https://vitess.io/docs/concepts/vstream
Some advantages of using VStream gRPC are:
-
It is a simple way to receive change events from Vitess. It is also recommended in Vitess’s documentation to use VStream to build CDC processes downstream.
-
VTGate hides the complexity of connecting to various source MySQL instances.
-
It has low latency since change events are streamed to the client as soon as they happen.
-
The change events include not only inserts and updates, but also deletes.
-
Probably one of the biggest advantages is that the change events contain the schema of each table. So you don’t have to worry about fetching each table’s schema in advance (by, for example, parsing DDLs or querying the table’s definition).
-
The change events have VGTID included, which the CDC process can store and use as the offset from where to restart the CDC process next time.
-
Also importantly, VStream is designed to work well with Vitess operations such as Resharding and Moving Tables.
There are also some disadvantages:
-
Although it includes table schemas, some important information is still missing. For example, the
EnumandSetcolumn types don’t provide all the allowed values yet. This should be fixed in the next major release (Vitess 9) though. -
Since VStream is a gRPC service, we cannot use the Debezium MySQL Connector out-of-the-box. However, it is quite straightforward to implement the gRPC client in other languages.
All things considered, we’ve decided to use VStream gRPC to capture change events from Vitess and implement our Vitess Connector based on all the best practices of Debezium.
Vitess Connector Deep Dive and Open Source
After we’ve decided to implement our Vitess Connector, we started looking into the implementation details of various Debezium source connectors (MySQL, Postgres, SQLServer), to borrow some ideas. Almost all of them are implemented using a common Connector development framework. So it was clear we should develop the Vitess connector on top of it. Given we are very active users of the MySql Connector and we benefit from it being open-sourced, as it allows us to contribute to it things we were missing ourselves. So we decided we want to give back to community and open-source the Vitess source connector code-base under the Debezium umbrella. Please feel free to learn more at Debezium Connector Vitess. We welcome and value any contributions.
At a high level, as you can see below, connector instances are created in Kafka Connect workers. At the time of writing, you have two options to configure the connector to read from Vitess:
Option 1 (recommended):
As shown in Figure 3, each connector captures change events from all shards in a specific keyspace. If the keyspace is not sharded, the connector can still capture change events from the only shard in the keyspace. When it’s the first time that the connector starts, it reads from the current VGTID position of all shards in the keyspace. Because it subscribes to all shards, it continuously captures change events from all shards and sends them to Kafka. It automatically supports the Vitess Reshard operation, there is no data loss, nor duplication.
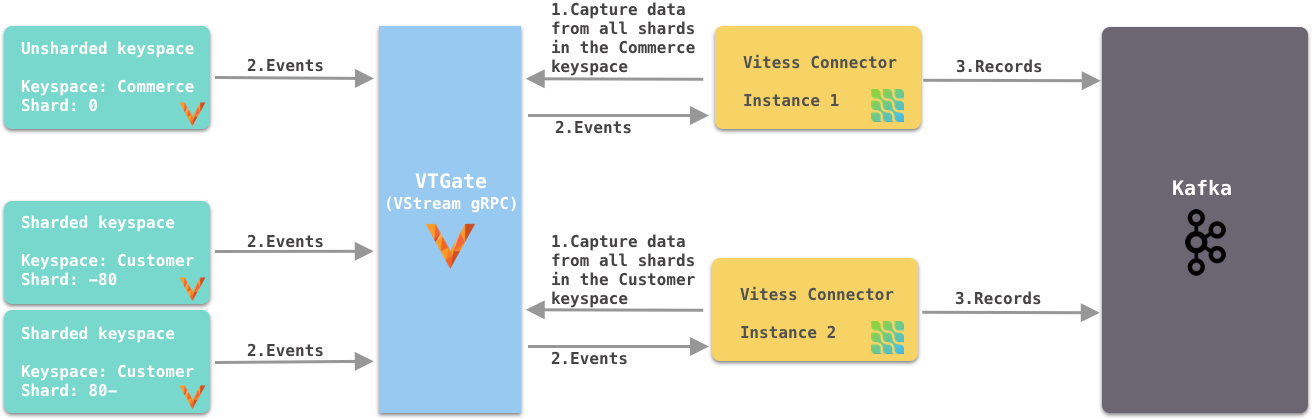
Figure 3. Each connector subscribes to all shards of a specific keyspace
Option 2:
As shown in Figure 4, each connector instance captures change events from a specific keyspace/shard pair. The connector instance gets the initial (the current) VGTID position of the keyspace/shard pair from VTCtld gRPC, which is another Vitess component. Each connector instance, independently, uses the VGTID it gets to subscribe to VStream gRPC and continuously capture change events from VStream and sends them to Kafka. To support the Vitess Reshard operation, you would need more manual operations.
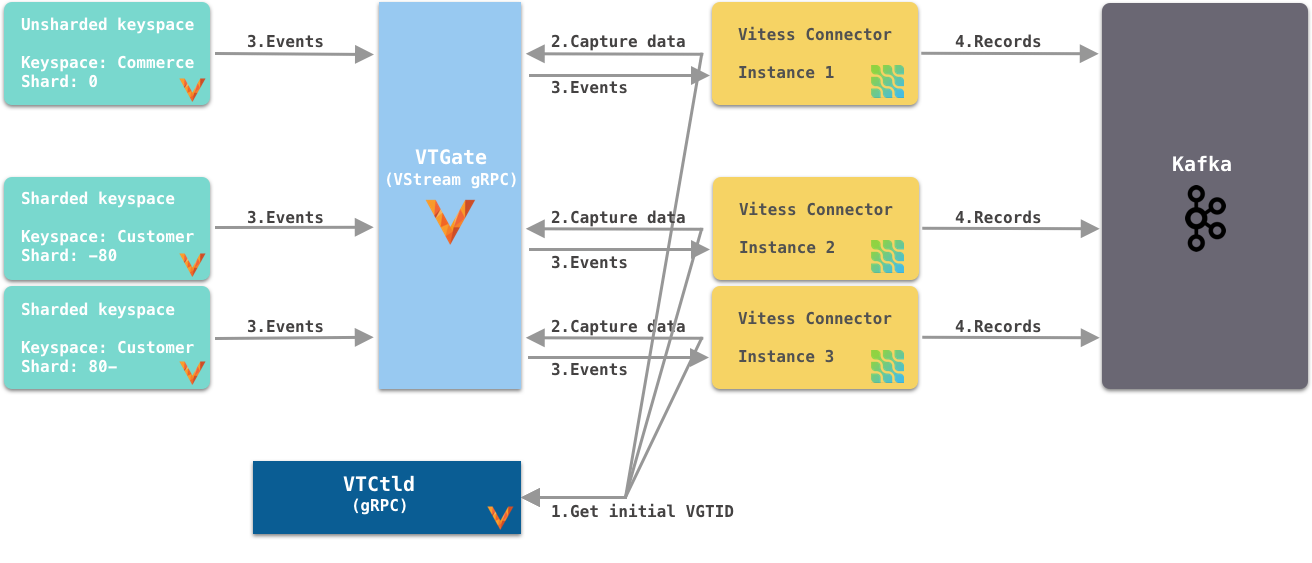
Figure 4. Each connector subscribes to one shard of a specific keyspace
Internally, each connector task uses a gRPC thread to constantly receive change events from VStream and puts the events into an internal blocking queue. The connector task thread polls events out of the queue and sends them to Kafka, as can be seen in Figure 5.
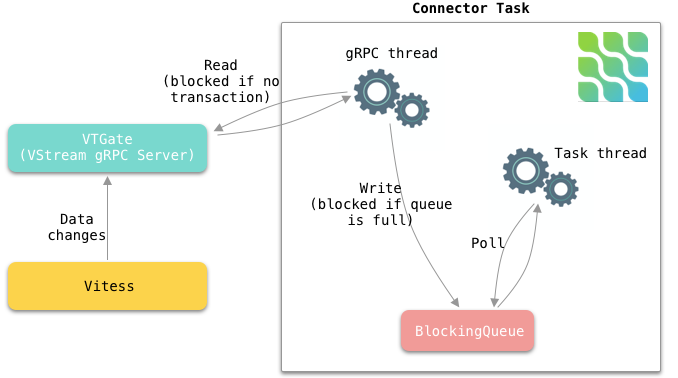
Figure 5. How each connector task works internally
Replication Challenges
While we were implementing the Vitess Connector and digging deeper into Vitess, we’ve also realized a few challenges.
Vitess Reshard
The Vitess connector supports the Vitess Reshard operation when the connector is configured to subscribe to all shards of a given keyspace. VStream sends a VGTID that contains the shard GTID for all shards. Vitess Resharding is transparent to users. Once it’s completed, Vitess will send the VGTID of the new shards. Therefore, the connector will use the new VGTID after reshard. However, you need to make sure that the connector is up and running when the reshard operation takes place. Especially please check that the offset topic of the connector has the new VGTID before deleting the old shards. This is because in case the old shards are deleted, VStream will not be able to recognize the VGTID from the old shards.
If you decide to subscribe to one shard per connector, the connector does not provide out-of-the-box support for Vitess resharding. One manual workaround to support resharding is creating one new connector per target shard. For example, one new connector for the commerce/-80 shard, and another new connector for the commerce/80- shard. Bear in mind that because they’re new connectors, by default, new topics will be created, however, you could use the Debezium logical topic router to route the records to the same Kafka topics.
Offset Management
VStream includes a VGTID event in its response. We save the VGTID as the offset in the Kafka offset topic, so when the connector restarts, we can start from the saved VGTID. However, in rare cases when a transaction includes a huge amount of rows, VStream batches the change events into multiple responses, and only the last response has the VGTID. In such cases, we don’t have the VGTID for every change event we receive. We have a few options to solve this particular issue:
-
We can buffer all the change events in memory and wait for the last response that contains the VGTID to arrive. So all events will have the correct VGTID associated with them. A few disadvantages are that we’ll have higher latency before events are sent to Kafka. Also, memory usage could potentially increase quite a lot due to buffering. Buffering also adds complexity to the logic. We also have no control over the number of events VStream sends to us.
-
We can use the latest VGTID we have, which is the VGTID from the previous VStream response. If the connector fails and restarts when processing such a big transaction, it’ll restart from the VGTID of the previous VStream response, thus reprocessing some events. Therefore, it has at-least-once event delivery semantics and it expects the downstream to be idempotent. Since most transactions are not big enough, most VStream responses will have VGTID in the response, so the chance of having duplicates is low. In the end, we chose this approach for its at-least-once delivery guarantee and its design simplicity.
Schema Management
VStream’s response also includes a FIELD event. It’s a special event that contains the schemas of the tables of which the rows are affected. For example, let’s assume we have 2 tables, A and B. If we insert a few rows into table A, the FIELD event will only contain table A’s schema. The VStream is smart enough to only include the FIELD event whenever necessary. For example, when a VStream client reconnects, or when a table’s schema is changed.
The older version of VStream includes only the column type (e.g. Integer, Varchar), no additional information such as whether the column is the primary key, whether the column has a default value, Decimal type’s scale and precision, Enum type’s allowed values, etc.
The newer version (Vitess 8) of VStream starts to include more information on each column. This will help the connector to deserialize more accurately certain types and have a more precise schema in the change events sent to Kafka.
Future Development Work
-
We can use VStream’s API to start streaming from the latest VGTID position, instead of getting the initial VGTID position from VTCtld gRPC. Doing so would eliminate the dependency from VTCtld.
-
We don’t support automatically extracting the primary keys from the change events yet. Currently, by default, all change events sent to Kafka have
nullas the key, unless themessage.key.columnsconnector configuration is specified. Vitess recently added flags of each column in the VStream FIELD event, which allows us to implement this feature soon. -
Add support for initial snapshots to capture all existing data before streaming changes.
Summary
MySQL has been used to power most of our backend services at Bolt. Due to the considerable growth of the volume of data and operational complexity, Bolt started to evaluate Vitess for its scalability and its built-in features such as resharding.
To capture data changes from Vitess, as what we’ve been doing with Debezium MySQL Connector, we’ve considered a few options. In the end, we have implemented our own Vitess Connector based on the common Debezium connector framework. While implementing the Vitess connector, we’ve encountered a few challenges. For example, support for the Vitess reshard operation, offset management, and schema management. We reasoned about ways to address the challenges and what we worked out as solutions.
We’ve also received quite some interest from multiple communities in this project and we’ve decided to open-source Vitess Connector under the Debezium umbrella. Please feel free to learn more, and we welcome and value any contributions.


About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.