
In the realm of data streaming optimization, even subtle improvements can make a significant impact. This article focuses on one such refinement: the introduction of batch support in Debezium’s JDBC connector. We’ll guide you through the process of enabling batches and share the practical outcomes of our performance testing.
Configuring batches
Since our previous releases were primarily focused on core functionalities, our latest release is dedicated to addressing the main pain point associated with the connector: performance.
The goal was to improve throughput in terms of events processed per second (EPS). To achieve this, we revisited the connector to enable the processing of batches of events.
You can now fine-tune the size of the batch using a new property: batch.size.
The batch.size property defines the number of records to be attempted for batching into the destination table. However, it’s crucial to note that the actual size of processed records is contingent upon the consumer.max.poll.records property of the Kafka Connect worker.
It’s important to be aware that if you set consumer.max.poll.records in the Connect worker properties to a value lower than batch.size, batch processing will be constrained by consumer.max.poll.records, and the intended batch.size may not be achieved.
Configure consumer max poll records
If you prefer not to configure the consumer.max.poll.records property globally on the Connect worker, you have the option to set the underlying consumer’s max.poll.records for a specific connector using consumer.override.max.poll.records in the connector configuration.
To enable per-connector configuration properties and override the default worker properties, add the following parameter to the worker properties file: connector.client.config.override.policy (see override-the-worker-configuration).
This property defines which configurations can be overridden by the connector. The default implementation is All, but other possible policies include None and Principal.
When connector.client.config.override.policy=All, each connector belonging to the worker is permitted to override the worker configuration. You can now utilize the following override prefixes for sink connector configurations: consumer.override.<sink-configuration-property>.
It’s worth noting that even if you set max.poll.records (with the default value of 500), you may receive fewer records. This is due to other properties that can impact record fetching from the topic/partitions.
Name: fetch.max.bytes
Default: 52428800 (52MB)
Name: max.partition.fetch.bytes
Default: 1048576 (1MB)
Name: message.max.bytes
Default: 1048588 (1MB)
Name: max.message.bytes
Default: 1048588 (1MB)
So adjust these based on your expected payload size to reach the desired number of poll records.
Results from performance testing
The objective of the performance tests was to provide a sense of how batch support improved the EPS. Therefore, these numbers do not reflect any real scenario but rather showcase relative improvements compared to the old JDBC version.
Configuration used for the tests
All tests executed on a ThinkPad T14s Gen 2i
CPU: Intel® Core™ i7-1185G7 @ 3.00GHz (8 cores)
RAM: 32GB
Disk: 512GB NVMe
All required components (Kafka, Connect, Zookeeper, etc.) inside docker containers.
The table used for the test has the following structure:
CREATE TABLE `aviation` (
`id` int NOT NULL,
`aircraft` longtext,
`airline` longtext,
`passengers` int DEFAULT NULL,
`airport` longtext,
`flight` longtext,
`metar` longtext,
`flight_distance` double DEFAULT NULL
)Test plan
We planned to execute these tests:
-
100K events from single table
-
MySQL batch vs without batch
-
-
100K events from three different table
-
MySQL batch vs without batch
-
-
1M events from single table
-
MySQL batch with batch size: 500, 1000, 5000, 10000 vs without batch
-
MySQL batch with batch size: 500, 1000, 5000, 10000 with JSONConverter
-
MySQL batch with batch size: 500, 1000, 5000, 10000 with Avro
-
MySQL batch with batch size: 500, 1000, 5000, 10000 with Avro and no index on destination table
-
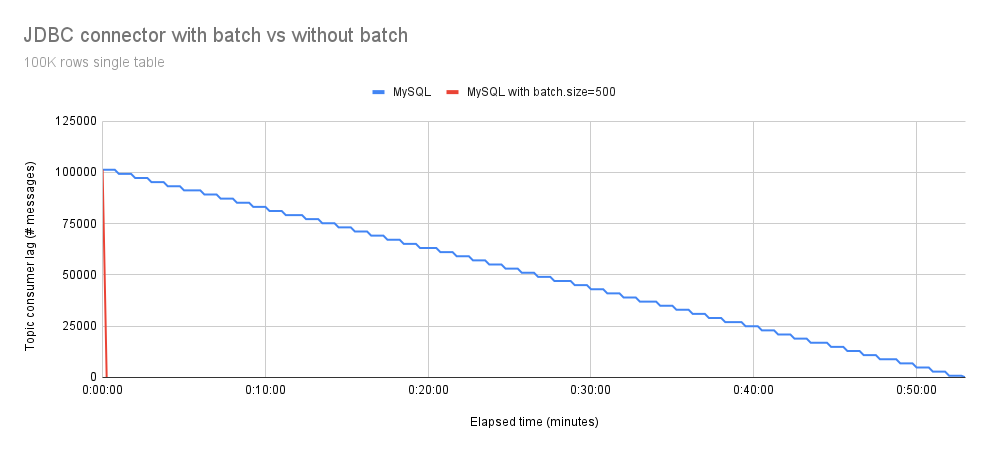
Figure 1 illustrates the total execution time required to process 100,000 events from a single table, comparing MySQL connector with and without the batch support.
| Despite the default values being set to |
We can observe, as expected, that the Debezium JDBC connector with batch support is faster.
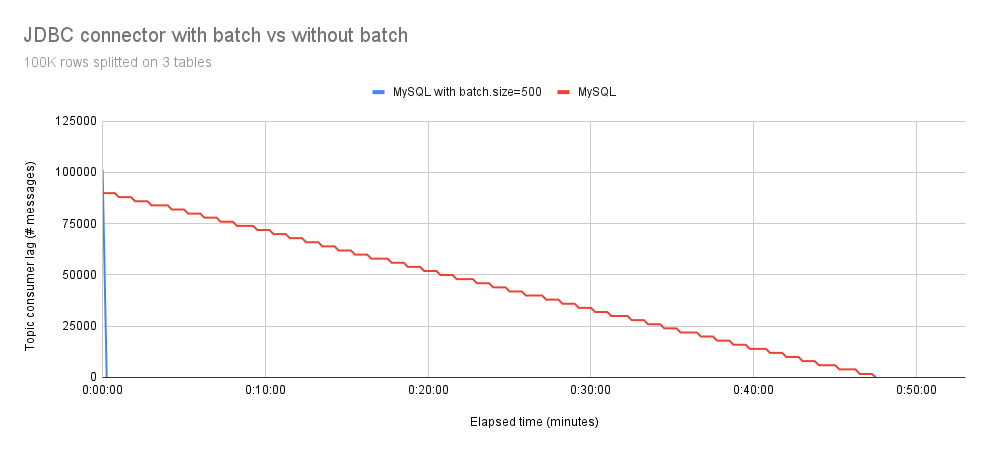
In Figure 2, we observe that splitting 100,000 events into three tables does not impact the results. The Debezium JDBC connector with batch support remains faster compared to the non-batch version.
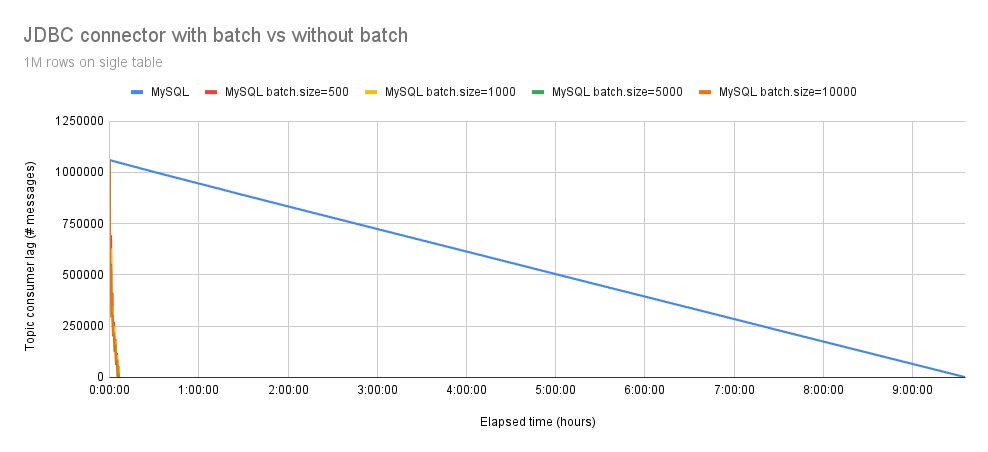
In Figure 3, it is evident that the performance gain becomes more pronounced with 1,000,000 events. The Debezium JDBC connector with batch support took approximately 7 minutes to insert all events, with an average throughput of 2300 eps, while the process without batch support took 570 minutes (9.5 hours). Therefore, the Debezium JDBC connector with batch support is 79 times faster than the version without batch support.
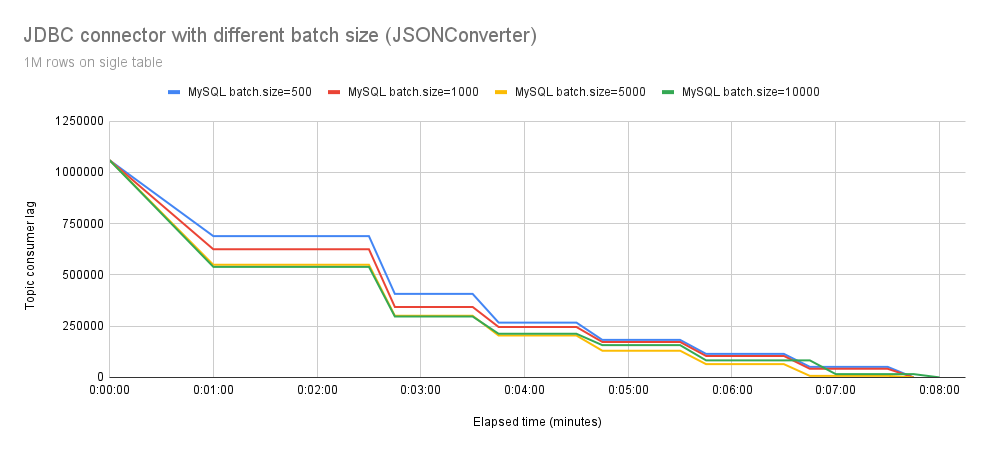
In Figure 4, we observe the behavior of the Debezium JDBC connector using the org.apache.kafka.connect.json.JsonConverter converter and writing to MySQL with different batch.size settings. While the initial differences are noticeable, it becomes apparent that the throughput continues to slow down. On average, all the batch.size configurations take about 7 minutes to process all events.
This raised a concern for us. After conducting a thorough analysis (profiling), we identified another issue: event deserialization. With high probability, this was the cause of the non-scalability of batch.size settings.
Although serialization improved scalability, we still lack an answer regarding the slowdown of EPS during the test run. One hypothesis could involve a certain type of buffer somewhere.
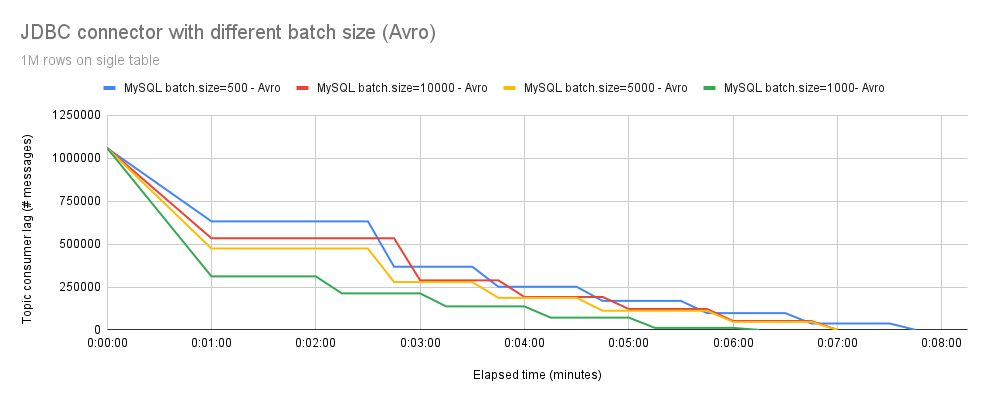
We then conducted experiments with Avro, and as depicted in Figure 5, the results show a significant improvement. As expected, processing 1,000,000 events with batch.size=500 is slower than with batch.size=10000. Notably, in our test configuration, the optimal value for batch.size is 1000, resulting in the fastest processing time.
Although the results are better compared to JSON, there is still some performance degradation.
To identify potential bottlenecks in the code, we added some metrics and found that the majority of time was spent executing batch statements on the database.
Further investigation revealed that our table had an index defined on the primary key, which was slowing down the inserts.
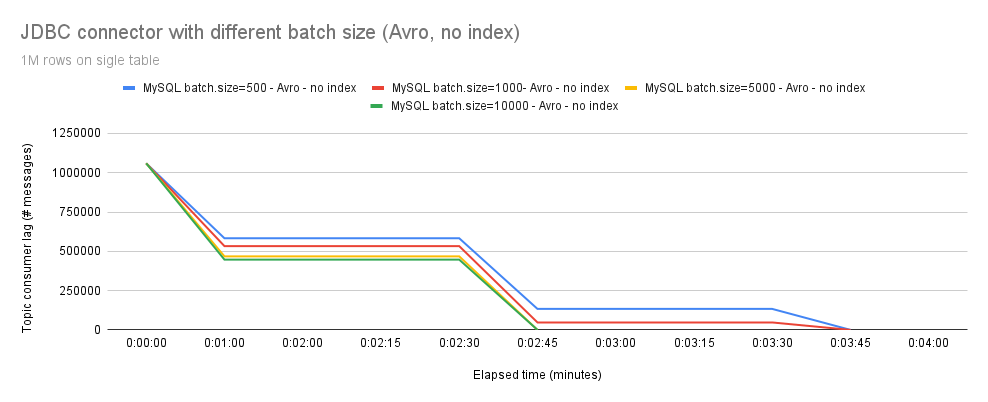
in Figure 6 you can see the improved performance with Avro and without primary key index. It is also evident the performance boost with a high value of batch.size.
Conclusion
We’ve explored how adjusting the batch.size can enhance the performance of the Debezium JDBC connector and discussed the proper configuration for maximizing its benefits. Equally crucial is adhering to performance tips and general guidelines for efficient inserts tailored to your specific database.
Here are a few examples:
While some settings may be specific to certain databases, several general principles apply across the majority of them.
Fiore Mario Vitale
Active in the open-source community with contributions to various projects, Mario is deeply involved in developing Debezium, the distributed platform for change data capture. During his career he developed extensive experience in event-driven architectures heavily influenced by data. Throughout his career, Mario has predominantly focused on data-intensive software and product development, which has heightened his sensitivity to developer experience and data-driven applications. Beyond his professional pursuits, Mario finds his sweet spot where tech and his personal interests come together. He loves taking photos, especially when he manages to freeze a beautiful moment. He's also passionate about motorsports and racing. When he's not coding, you can often find him exploring the great outdoors on his mountain bike, fueling his passion for adventure.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.