
This post originally appeared on the WePay Engineering blog.
Historically, MySQL had been the de-facto database of choice for microservices at WePay. As WePay scales, the sheer volume of data written into some of our microservice databases demanded us to make a scaling decision between sharded MySQL (i.e. Vitess) and switching to a natively sharded NoSQL database. After a series of evaluations, we picked Cassandra, a NoSQL database, primarily because of its high availability, horizontal scalability, and ability to handle high write throughput.
Batch ETL Options
After introducing Cassandra to our infrastructure, our next challenge was to figure out a way to expose data in Cassandra to BigQuery, our data warehouse, for analytics and reporting. We quickly built an Airflow hook and operator to execute full loads. This obviously doesn’t scale, as it rewrites the entire database on each load. To scale the pipeline, we evaluated two incremental load approaches, but both have their shortcomings:
-
Range query. This is a common ETL approach where data is extracted via a range query at regular intervals, such as hourly or daily. Anyone familiar with Cassandra data modelling would quickly realize how unrealistic this approach is. Cassandra tables need to be modeled to optimize query patterns used in production. Adding this query pattern for analytics in most cases means cloning the table with different clustering keys. RDBMS folks might suggest secondary index to support this query pattern, but secondary index in Cassandra are local, therefore this approach would pose performance and scaling issues of its own.
-
Process unmerged SSTables. SSTables are Cassandra’s immutable storage files. Cassandra offers a sstabledump CLI command that converts SSTable content into human-readable JSON. However, Cassandra is built on top of the concept of Log-Structured Merge (LSM) Tree, meaning SSTables merge periodically into new compacted files. Depending on the compaction strategy, detecting unmerged SSTable files out-of-band may be challenging (we later learned about the incremental backup feature in Cassandra which only backs up uncompacted SSTables; so this approach would have worked as well.)
Given these challenges, and having built and operated a streaming data pipeline for MySQL, we began to explore streaming options for Cassandra.
Streaming Options
Double-Writing
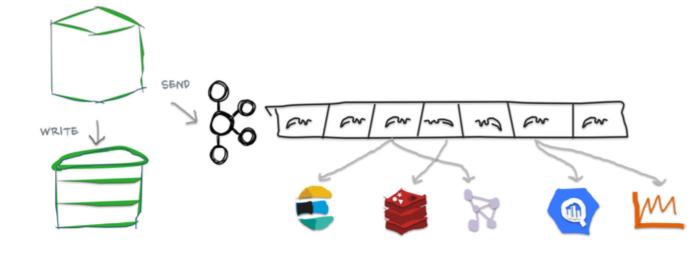
The idea is to publish to Kafka every time a write is performed on Cassandra. This double-writing could be performed via the built-in trigger or a custom wrapper around the client. There are performance problems with this approach. First, due to the fact that we now need to write to two systems instead of one, write latency is increased. More importantly, when a write to one system fails due to a timeout, whether the write is successful or not is indeterministic. To guarantee data consistency on both systems, we would have to implement distributed transactions, but multiple roundtrips for consensus will increase latency and reduce throughput further. This defeats the purpose of a high write-throughput database.
Kafka as Event Source
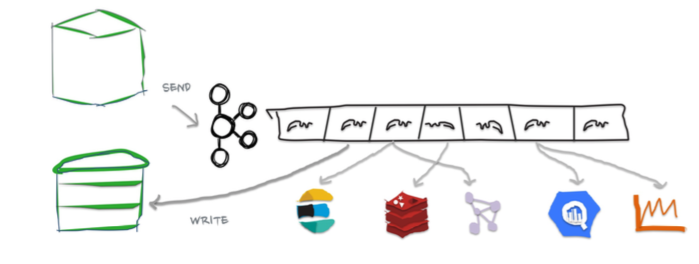
The idea is to write to Kafka rather than directly writing to Cassandra; and then apply the writes to Cassandra by consuming events from Kafka. Event sourcing is a pretty popular approach these days. However, if you already have existing services directly writing to Cassandra, it would require a change in application code and a nontrivial migration. This approach also violates read-your-writes consistency: the requirement that if a process performs a write, then the same process performing a subsequent read must observe the write’s effects. Since writes are routed through Kafka, there will be a lag between when the write is issued and when it is applied; during this time, reads to Cassandra will result in stale data. This may cause unforeseeable production issues.
Parsing Commit Logs
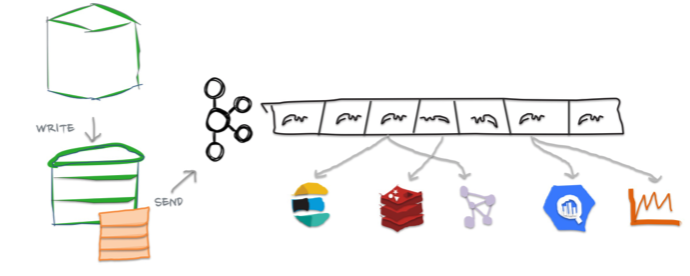
Cassandra introduced a change data capture (CDC) feature in 3.0 to expose its commit logs. Commit logs are write-ahead logs in Cassandra designed to provide durability in case of machine crashes. They are typically discarded upon flush. With CDC enabled, they are instead transferred to a local CDC directory upon flush, which is then readable by other processes on the Cassandra node. This allows us to use the same CDC mechanism as in our MySQL streaming pipeline. It decouples production operations from analytics, and thus does not require additional work from application engineers.
Ultimately, after considering throughput, consistency, and separation of concerns, the final option – parsing commit logs – became the top contender.
Commit Log Deep Dive
Aside from exposing commit logs, Cassandra also provides CommitLogReader and CommitLogReadHandler classes to help with the deserialization of logs. It seems like the hard work has been done, and what’s left is applying transformations – converting deserialized representations into Avro records and publish them to Kafka. However, as we dug further into the implementation of the CDC feature and of Cassandra itself, we realized that there are many new challenges.
Delayed Processing
Commit logs only arrive in the CDC directory when it is full, in which case it would be flushed/discarded. This implies there is a delay between when the event is logged and when the event is captured. If little to no writes are executed, then the delay in event capturing could be arbitrarily long.
Space Management
In MySQL you can set binlog retention such that the logs will be automatically deleted after the configured retention period. However in Cassandra there is no such option. Once the commit logs are transferred to CDC directory, consumption must be in place to clean up commit logs after processing. If the available disk space for CDC directory exceeds a given threshold, further writes to the database will be rejected.
Duplicated Events
Commit logs on an individual Cassandra node do not reflect all writes to the cluster; they only reflect writes to the node. This makes it necessary to process commit logs on all nodes. But with a replication factor of N, N copies of each event are sent downstream.
Out-of-Order Events
Writes to an individual Cassandra node are logged serially as they arrive. However, these events may arrive out-of-order from when they are issued. Downstream consumers of these events must understand the event time and implement last write wins logic similar to Cassandra’s read path to get the correct result.
Out-of-Band Schema Change
Schema changes of tables are communicated via a gossip protocol and are not recorded in commit logs. Therefore changes in schema could only be detected on a best-effort basis.
Incomplete Row Data
Cassandra does not perform read before write, as a result change events do not capture the state of every column, they only capture the state of modified columns. This makes the change event less useful than if the full row is available.
Once we acquired a deep understanding of Cassandra commit logs, we re-assessed our requirements against the given constraints in order to design a minimum viable infrastructure.
Minimum Viable Infrastructure
Borrowing from the minimum viable product philosophy, we want to design a data pipeline with a minimum set of features and requirements to satisfy our immediate customers. For Cassandra CDC, this means:
-
Production database’s health and performance should not be negatively impacted by introducing CDC; slowed operations and system downtimes are much costlier than a delay in the analytics pipeline
-
Querying Cassandra tables in our data warehouse should match the results of querying the production database (barring delays); having duplicate and/or incomplete rows amplifies post-processing workload for every end user With these criteria in front of us, we began to brainstorm for solutions, and ultimately came up with three approaches:
Stateless Stream Processing
This solution is inspired by Datastax’s advanced replication blog post. The idea is to deploy an agent on each Cassandra node to process local commit logs. Each agent is considered as “primary” for a subset of writes based on partition keys, such that every event has exactly one primary agent. Then during CDC, in order to avoid duplicate events, each agent only sends an event to Kafka if it is the primary agent for the event. To handle eventual consistency, each agent would sort events into per-table time-sliced windows as they arrive (but doesn’t publish them right away); when a window expires, events in that window are hashed, and the hash is compared against other nodes. If they don’t match, data is fetched from the inconsistent node so the correct value could be resolved by last write wins. Finally the corrected events in that window will be sent to Kafka. Any out-of-order event beyond the time-sliced windows would have to be logged into an out-of-sequence file and handled separately. Since deduplication and ordering are done in-memory, concerns with agent failover causing data loss, OOM issues impacting production database, and the overall complexity of this implementation stopped us from exploring it further.
Stateful Stream Processing
This solution is the most feature rich. The idea is that the agent on each Cassandra node will process commit logs and publish events to Kafka without deduplication and ordering. Then a stream processing engine will consume these raw events and do the heavy lifting (such as filtering out duplicate events with a cache, managing event orders with event-time windowing, and capturing state of unmodified columns by performing read before write on a state store), and then publish these derived events to a separate Kafka topic. Finally, KCBQ will be used to consume events from this topic and upload them to BigQuery. This approach is appealing because it solves the problem generically – anyone can subscribe to the latter Kafka topic without needing to handle deduplication and ordering on their own. However, this approach introduces a nontrivial amount of operational overhead; we would have to maintain a stream processing engine, a database, and a cache.
Processing-On-Read
Similar to the previous approach, the idea is to process commit logs on each Cassandra node and send events to Kafka without deduplication and ordering. Unlike the previous approach, the stream processing portion is completely eliminated. Instead the raw events will be directly uploaded to BigQuery via KCBQ. Views are created on top of the raw tables to handle deduplication, ordering, and merging of columns to form complete rows. Because BigQuery views are virtual tables, the processing is done lazily each time the view is queried. To prevent the view query from getting too expensive, the views would be materialized periodically. This approach removes both operational complexity and code complexity by leveraging BigQuery’s massively parallel query engine. However, the drawback is that non-KCBQ downstream consumers must do all the work on their own.
Given that our main purpose of streaming Cassandra is data warehousing, we ultimately decided to implement processing-on-read. It provides the essential features for our existing use case, and offers the flexibility to expand into the other two more generic solutions mentioned above in the future.
Open Source
During this process of building a real-time data pipeline for Cassandra, we have received a substantial amount of interest on this project. As a result, we have decided to open-source the Cassandra CDC agent under the Debezium umbrella as an incubating connector. If you would like to learn more or contribute, check out the work-in-progress pull request for source code and documentation.
In the second half of this blog post series, we will elaborate on the CDC implementation itself in more details. Stay tuned!
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.