
Most of the times Debezium is used to stream data changes into Apache Kafka. What though if you’re using another streaming platform such as Apache Pulsar or a cloud-based solution such as Amazon Kinesis, Azure Event Hubs and the like? Can you still benefit from Debezium’s powerful change data capture (CDC) capabilities and ingest changes from databases such as MySQL, Postgres, SQL Server etc.?
Turns out, with just a bit of glue code, you can! In the following we’ll discuss how to use Debezium to capture changes in a MySQL database and stream the change events into Kinesis, a fully-managed data streaming service available on the Amazon cloud.
Introducing the Debezium Embedded Engine
Debezium is implemented as a set of connectors for Kafka and thus usually is run via Kafka Connect. But there’s one little gem in Debezium which isn’t as widely known yet, which is the embedded engine.
When using this engine, the Debezium connectors are not executed within Kafka Connect, but as a library embedded into your own Java application. For this purpose, the debezium-embedded module provides a small runtime environment which performs the tasks that’d otherwise be handled by the Kafka Connect framework: requesting change records from the connector, committing offsets etc. Each change record produced by the connector is passed to a configured event handler method, which in our case will convert the record into its JSON representation and submit it to a Kinesis stream, using the Kinesis Java API.
The overall architecture looks like so:
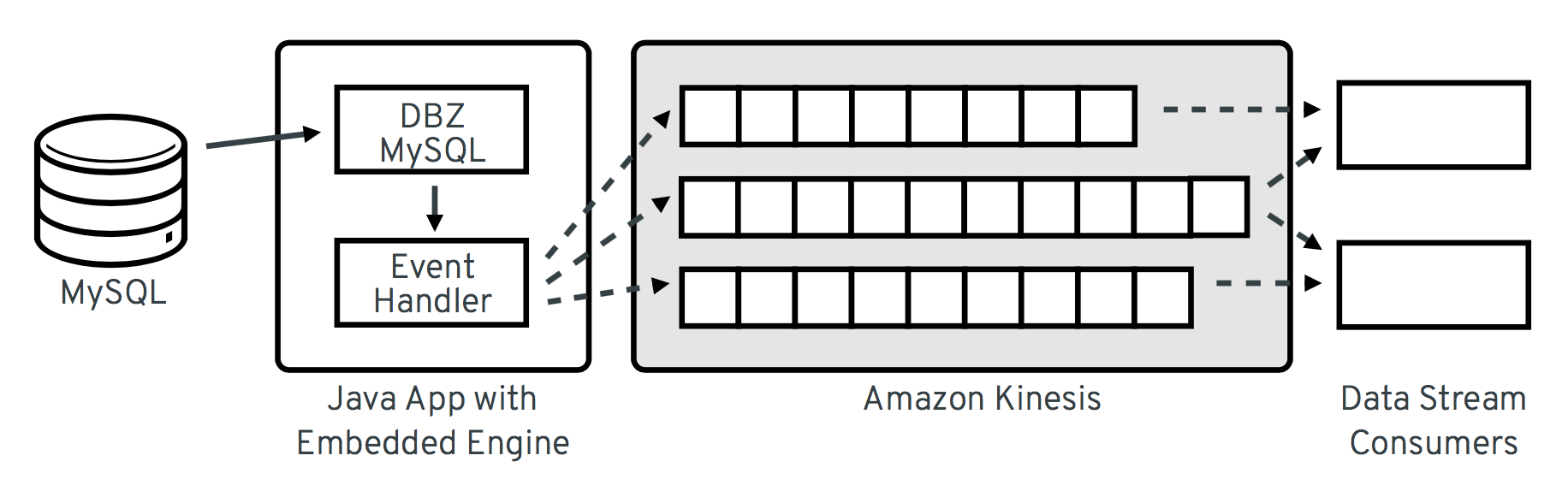
Now let’s walk through the relevant parts of the code required for that. A complete executable example can be found in the debezium-examples repo on GitHub.
Set-Up
In order to use Debezium’s embedded engine, add the debezium-embedded dependency as well as the Debezium connector of your choice to your project’s pom.xml. In the following we’re going to use the connector for MySQL. We also need to add a dependency to the Kinesis Client API, so these are the dependencies needed:
...
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-embedded</artifactId>
<version>0.8.3.Final</version>
</dependency>
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-connector-mysql</artifactId>
<version>0.8.3.Final</version>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>amazon-kinesis-client</artifactId>
<version>1.9.0</version>
</dependency>
...Configuring the Embedded Engine
The Debezium embedded engine is configured through an instance of io.debezium.config.Configuration. This class can obtain values from system properties or from a given config file, but for the sake of the example we’ll simply pass all required values via its fluent builder API:
Configuration config = Configuration.create()
.with(EmbeddedEngine.CONNECTOR_CLASS, "io.debezium.connector.mysql.MySqlConnector")
.with(EmbeddedEngine.ENGINE_NAME, "kinesis")
.with(MySqlConnectorConfig.SERVER_NAME, "kinesis")
.with(MySqlConnectorConfig.SERVER_ID, 8192)
.with(MySqlConnectorConfig.HOSTNAME, "localhost")
.with(MySqlConnectorConfig.PORT, 3306)
.with(MySqlConnectorConfig.USER, "debezium")
.with(MySqlConnectorConfig.PASSWORD, "dbz")
.with(MySqlConnectorConfig.DATABASE_WHITELIST, "inventory")
.with(MySqlConnectorConfig.TABLE_WHITELIST, "inventory.customers")
.with(EmbeddedEngine.OFFSET_STORAGE,
"org.apache.kafka.connect.storage.MemoryOffsetBackingStore")
.with(MySqlConnectorConfig.DATABASE_HISTORY,
MemoryDatabaseHistory.class.getName())
.with("schemas.enable", false)
.build();If you’ve ever set up the Debezium MySQL connector in Kafka Connect, most of the properties will look familiar to you.
But let’s talk about the OFFSET_STORAGE and DATABASE_HISTORY options in a bit more detail. They deal with how connector offsets and the database history should be persisted. When running the connector via Kafka Connect, both would typically be stored in specific Kafka topics. But that’s not an option here, so an alternative is needed. For this example we’re simply going to keep the offsets and database history in memory. I.e. if the engine is restarted, this information will be lost and the connector will start from scratch, e.g. with a new initial snapshot.
While out of scope for this blog post, it wouldn’t be too difficult to create alternative implementations of the OffsetBackingStore and DatabaseHistory contracts, respectively. For instance if you’re fully committed into the AWS cloud services, you could think of storing offsets and database history in the DynamoDB NoSQL store. Note that, different from Kafka, a Kinesis stream wouldn’t be suitable for storing the database history. The reason being, that the maximum retention period for Kinesis data streams is seven days, whereas the database history must be kept for the entire lifetime of the connector. Another alternative could be to use the existing filesystem based implementations FileOffsetBackingStore and FileDatabaseHistory, respectively.
The next step is to build an EmbeddedEngine instance from the configuration. Again this is done using a fluent API:
EmbeddedEngine engine = EmbeddedEngine.create()
.using(config)
.using(this.getClass().getClassLoader())
.using(Clock.SYSTEM)
.notifying(this::sendRecord)
.build();The most interesting part here is the notifying call. The method passed here is the one which will be invoked by the engine for each emitted data change record. So let’s take a look at the implementation of this method.
Sending Change Records to Kinesis
The sendRecord() method is where the magic happens. We’ll convert the incoming SourceRecord into an equivalent JSON representation and propagate it to a Kinesis stream.
For that, it’s important to understand some conceptual differences between Apache Kafka and Kinesis. Specifically, messages in Kafka have a key and a value (which both are arbitrary byte arrays). In case of Debezium, the key of data change events represents the primary key of the affected record and the value is a structure comprising of old and new row state as well as some additional metadata.
In Kinesis on the other hand a message contains a data blob (again an arbitrary byte sequence) and a partition key. Kinesis streams can be split up into multiple shards and the partition key is used to determine into which shard a given message should go.
Now one could think of mapping the key from Debezium’s change data events to the Kinesis partition key, but partition keys are limited to a length of 256 bytes. Depending on the length of primary key column(s) in the captured tables, this might not be enough. So a safer option is to create a hash value from the change message key and use that as the partition key. This in turn means that the change message key structure should be added next to the actual value to the Kinesis message’s data blob. While the key column values themselves are part of the value structure, too, a consumer otherwise wouldn’t know which column(s) make up the primary key.
With that in mind, let’s take a look at the sendRecord() implementation:
private void sendRecord(SourceRecord record) {
// We are interested only in data events not schema change events
if (record.topic().equals("kinesis")) {
return;
}
// create schema for container with key *and* value
Schema schema = SchemaBuilder.struct()
.field("key", record.keySchema())
.field("value", record.valueSchema())
.build();
Struct message = new Struct(schema);
message.put("key", record.key());
message.put("value", record.value());
// create partition key by hashing the record's key
String partitionKey = String.valueOf(
record.key() != null ? record.key().hashCode() : -1);
// create data blob representing the container by using Kafka Connect's
// JSON converter
final byte[] payload = valueConverter.fromConnectData(
"dummy", schema, message);
// Assemble the put-record request ...
PutRecordRequest putRecord = new PutRecordRequest();
putRecord.setStreamName(record.topic());
putRecord.setPartitionKey(partitionKey);
putRecord.setData(ByteBuffer.wrap(payload));
// ... and execute it
kinesisClient.putRecord(putRecord);
}The code is quite straight-forward; as discussed above it’s first creating a container structure containing key and value of the incoming source record. This structure then is converted into a binary representation using the JSON converter provided by Kafka Connect (an instance of JsonConverter). Then a PutRecordRequest is assembled from that blob, the partition key and the change record’s topic name, which finally is sent to Kinesis.
The Kinesis client object can be re-used and is set up once like so:
// Uses the credentials from the local "default" AWS profile
AWSCredentialsProvider credentialsProvider =
new ProfileCredentialsProvider("default");
this.kinesisClient = AmazonKinesisClientBuilder.standard()
.withCredentials(credentialsProvider)
.withRegion("eu-central-1") // use your AWS region here
.build();With that, we’ve set up an instance of Debezium’s EmbeddedEngine which runs the configured MySQL connector and passes each emitted change event to Amazon Kinesis. The last missing step is to actually run the engine. This is done on a separate thread using an Executor, e.g. like so:
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);Note you also should make sure to properly shut down the engine eventually. How that can be done is shown in the accompanying example in the debezium-examples repo.
Running the Example
Finally let’s take a look at running the complete example and consuming the Debezium CDC events from the Kinesis stream. Start by cloning the examples repository and go to the kinesis directory:
git clone https://github.com/debezium/debezium-examples.git
cd debezium-examples/kinesisMake sure you’ve met the prerequisites described in the example’s README.md; most notably you should have a local Docker installation and you’ll need to have set up an AWS account as well as have the AWS client tools installed. Note that Kinesis isn’t part of the free tier when registering with AWS, i.e. you’ll pay a (small) amount of money when executing the example. Don’t forget to delete the streams you’ve set up once done, we won’t pay your AWS bills :)
Now run Debezium’s MySQL example database to have some data to play with:
docker run -it --rm --name mysql -p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=debezium \
-e MYSQL_USER=mysqluser \
-e MYSQL_PASSWORD=mysqlpw \
debezium/example-mysql:0.8Create a Kinesis stream for change events from the customers table:
aws kinesis create-stream --stream-name kinesis.inventory.customers \
--shard-count 1Execute the Java application that runs the Debezium embedded engine (if needed, adjust the value of the kinesis.region property in pom.xml to your own region first):
mvn exec:javaThis will start up the engine and the MySQL connector, which takes an initial snapshot of the captured database.
In order to take a look at the CDC events in the Kinesis stream, the AWS CLI can be used (usually, you’d implement a Kinesis Streams application for consuming the events). To do so, set up a shard iterator first:
ITERATOR=$(aws kinesis get-shard-iterator --stream-name kinesis.inventory.customers --shard-id 0 --shard-iterator-type TRIM_HORIZON | jq '.ShardIterator')Note how the jq utility is used to obtain the generated id of the iterator from the JSON structure returned by the Kinesis API. Next that iterator can be used to examine the stream:
aws kinesis get-records --shard-iterator $ITERATORYou should receive an array of records like this:
{
"Records": [
{
"SequenceNumber":
"49587760482547027816046765529422807492446419903410339842",
"ApproximateArrivalTimestamp": 1535551896.475,
"Data": "eyJiZWZvcm...4OTI3MzN9",
"PartitionKey": "eyJpZCI6MTAwMX0="
},
...
]
}The Data element is a Base64-encoded representation of the message’s data blob. Again jq comes in handy: we can use it to just extract the Data part of each record and decode the Base64 representation (make sure to use jq 1.6 or newer):
aws kinesis get-records --shard-iterator $ITERATOR | \
jq -r '.Records[].Data | @base64d' | jq .Now you should see the change events as JSON, each one with key and value:
{
"key": {
"id": 1001
},
"value": {
"before": null,
"after": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"source": {
"version": "0.8.1.Final",
"name": "kinesis",
"server_id": 0,
"ts_sec": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"snapshot": true,
"thread": null,
"db": "inventory",
"table": "customers",
"query": null
},
"op": "c",
"ts_ms": 1535555325628
}
}
...Next let’s try and update a record in MySQL:
# Start MySQL CLI client
docker run -it --rm --name mysqlterm --link mysql --rm mysql:5.7 \
sh -c 'exec mysql -h"$MYSQL_PORT_3306_TCP_ADDR" \
-P"$MYSQL_PORT_3306_TCP_PORT" -uroot -p"$MYSQL_ENV_MYSQL_ROOT_PASSWORD"'
# In the MySQL client
use inventory;
update customers set first_name = 'Trudy' where id = 1001;If you now fetch the iterator again, you should see one more data change event representing that update:
...
{
"key": {
"id": 1001
},
"value": {
"before": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"after": {
"id": 1001,
"first_name": "Trudy",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"source": {
"version": "0.8.1.Final",
"name": "kinesis",
"server_id": 223344,
"ts_sec": 1535627629,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 364,
"row": 0,
"snapshot": false,
"thread": 10,
"db": "inventory",
"table": "customers",
"query": null
},
"op": "u",
"ts_ms": 1535627622546
}
}Once you’re done, stop the embedded engine application by hitting Ctrl + C, stop the MySQL server by running docker stop mysql and delete the kinesis.inventory.customers stream in Kinesis.
Summary and Outlook
In this blog post we’ve demonstrated that Debezium cannot only be used to stream data changes into Apache Kafka, but also into other streaming platforms such as Amazon Kinesis. Leveraging its embedded engine and by implementing a bit of glue code, you can benefit from all the CDC connectors provided by Debezium and their capabilities and connect them to the streaming solution of your choice.
And we’re thinking about even further simplifying this usage of Debezium. Instead of requiring you to implement your own application that invokes the embedded engine API, we’re considering to provide a small self-contained Debezium runtime which you can simply execute. It’d be configured with the source connector to run and make use of an outbound plug-in SPI with ready-to-use implementations for Kinesis, Apache Pulsar and others. Of course such runtime would also provide suitable implementations for safely persisting offsets and database history, and it’d offer means of monitoring, health checks etc. Meaning you could connect the Debezium source connectors with your preferred streaming platform in a robust and reliable way, without any manual coding required!
If you like this idea, then please check out JIRA issue DBZ-651 and let us know about your thoughts, e.g. by leaving a comment on the issue, in the comment section below or on our mailing list.
Gunnar Morling
Gunnar is a software engineer and open-source enthusiast by heart, currently working as a Technologist at Confluent. Previously, he helped to build a realtime stream processing platform based on Apache Flink and led the Debezium project, a distributed platform for change data capture. He is a Java Champion and has founded multiple open source projects such as JfrUnit, kcctl, and MapStruct. Gunnar is an avid blogger (morling.dev) and has spoken at various conferences like QCon, Java One, and Devoxx. He lives in Hamburg, Germany.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.