
Change events streamed from a database by Debezium are (in developer parlance) strongly typed. This means that event consumers should be aware of the types of data conveyed in the events. This problem of passing along message type data can be solved in multiple ways:
-
the message structure is passed out-of-band to the consumer, which is able to process the data stored in it
-
the message contains metadata (the schema) that is embedded within the message
-
the message contains a reference to a registry which contains the associated metadata
An example of the first case is Apache Kafka’s well known JsonConverter. It can operate in two modes - with and without schemas. When configured to work without schemas, it generates a plain JSON message where the consumer either needs to know the types of each field beforehand, or it needs to execute heuristic rules to "guess" and map values to datatypes. While this approach is quite flexible it can fail for more advanced cases, e.g. temporal or other semantic types encoded as strings. Also, constraints associated with the types are usually lost.
Here’s an example of such a message:
{
"before": null,
"after": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"source": {
"version": "1.1.0.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 0,
"snapshot": "true",
"db": "inventory",
"table": "customers",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"thread": null,
"query": null
},
"op": "c",
"ts_ms": 1586331101491,
"transaction": null
}Note how no type information beyond JSON’s basic type system is present. E.g. a consumer cannot conclude from the event itself, which length the numeric id field has.
An example of the second case is again JsonConverter. By means of its schemas.enable option, the JSON message will consist of two parts - schema and payload. The payload part is exactly the same as in the previous case; the schema part contains a description of the message, its fields, field types and associated type constraints. This enables the consumer to process the message in a type-safe way. The drawback of this approach is that the message size has increased significantly, as the schema is quite a large object. As schemas tend to be changed rarely (how often do you change the definitions of the columns of your database tables?), adding the schema to each and every event poses a signficant overhead.
The following example of a message with a schema clearly shows that the schema itself can be significantly larger than the payload and is not very economical to use:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "dbserver1.inventory.customers.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "dbserver1.inventory.customers.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Enum",
"version": 1,
"parameters": {
"allowed": "true,last,false"
},
"default": "false",
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": true,
"field": "table"
},
{
"type": "int64",
"optional": false,
"field": "server_id"
},
{
"type": "string",
"optional": true,
"field": "gtid"
},
{
"type": "string",
"optional": false,
"field": "file"
},
{
"type": "int64",
"optional": false,
"field": "pos"
},
{
"type": "int32",
"optional": false,
"field": "row"
},
{
"type": "int64",
"optional": true,
"field": "thread"
},
{
"type": "string",
"optional": true,
"field": "query"
}
],
"optional": false,
"name": "io.debezium.connector.mysql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "id"
},
{
"type": "int64",
"optional": false,
"field": "total_order"
},
{
"type": "int64",
"optional": false,
"field": "data_collection_order"
}
],
"optional": true,
"field": "transaction"
}
],
"optional": false,
"name": "dbserver1.inventory.customers.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"source": {
"version": "1.1.0.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 0,
"snapshot": "true",
"db": "inventory",
"table": "customers",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"thread": null,
"query": null
},
"op": "c",
"ts_ms": 1586331101491,
"transaction": null
}
}Registry
Then there is the third approach that combines strong points of the first two, while it removes their drawbacks at the cost of introducing a new component - a registry - that stores and versions message schemas.
There are multiple schema registry implementations available; in the following we’re going to focus on the Apicurio Registry, which is an open-source (Apache license 2.0) API and schema registry. The project provides not only the registry itself, but also client libraries and tight integration with Apache Kafka and Kafka Connect in form of serializers and converters.
Apicurio enables Debezium and consumers to exchange messages whose schema is stored in the registry and pass only a reference to the schema in the messages themselves. A the structure of captured source tables and thus message schemas evolve, the registry creates new versions of the schemas, too, so not only current but also historical schemas are available.
Apicurio provides multiple serialization formats out-of-the-box:
-
JSON with externalized schema support
Every serializer and deserializer knows how to automatically interact with the Apicurio API so the consumer is isolated from it as an implementation detail. The only information necessary is the location of the registry.
Apicurio also provides API compatibility layers for schema registries from IBM and Confluent. This is a very useful feature, as it enables the use of 3rd-party tools like kafkacat, even if they are not aware of Apicurio’s native API.
JSON Converter
In the Debezium examples repository, there is a Docker Compose based example, that deploys the Apicurio registry side-by-side with the standard Debezium tutorial example setup.
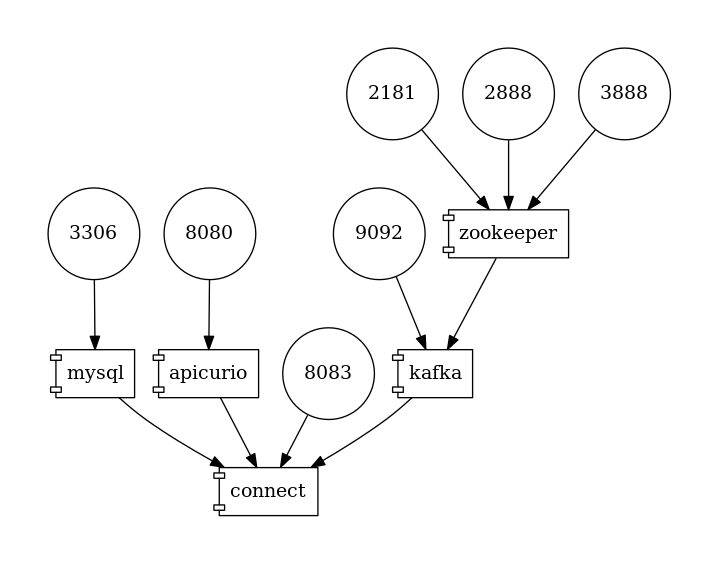
Figure 1. The Deployment Topology
To follow the example you need to clone the Debezium example repository.
| Since Debezium 1.2 the Debezium container images are shipped with Apicurio converter support. You can enable Apicurio converters by using a |
$ cd tutorial
$ export DEBZIUM_VERSION=1.1
# Start the deployment
$ docker-compose -f docker-compose-mysql-apicurio.yaml up -d --build
# Start the connector
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" \
http://localhost:8083/connectors/ -d @register-mysql-apicurio-converter-json.json
# Read content of the first message
$ docker run --rm --tty \
--network tutorial_default debezium/tooling bash \
-c 'kafkacat -b kafka:9092 -C -o beginning -q -t dbserver1.inventory.customers -c 1 | jq .'The resulting message should look like:
{
"schemaId": 48,
"payload": {
"before": null,
"after": {
"id": 1001,
"first_name": "Sally",
"last_name": "Thomas",
"email": "sally.thomas@acme.com"
},
"source": {
"version": "1.1.0.Final",
"connector": "mysql",
"name": "dbserver1",
"ts_ms": 0,
"snapshot": "true",
"db": "inventory",
"table": "customers",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"thread": null,
"query": null
},
"op": "c",
"ts_ms": 1586334283147,
"transaction": null
}
}The JSON message contains the full payload and at the same time a reference to a schema with id 48. It is possible to query the schema from the registry either using id or using a schema symbolic name as defined by Debezium documentation. In this case both commands
$ docker run --rm --tty \
--network tutorial_default \
debezium/tooling bash -c 'http http://apicurio:8080/ids/64 | jq .'
$ docker run --rm --tty \
--network tutorial_default \
debezium/tooling bash -c 'http http://apicurio:8080/artifacts/dbserver1.inventory.customers-value | jq .'result in the same schema description:
{
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "dbserver1.inventory.customers.Value",
"field": "before"
},
...
],
"optional": false,
"name": "dbserver1.inventory.customers.Envelope"
}Which is the same as we have seen in the "JSON with schema" example before.
The connector registration request differs in a few lines from the previous one:
...
"key.converter": "io.apicurio.registry.utils.converter.ExtJsonConverter", (1)
"key.converter.apicurio.registry.url": "http://apicurio:8080", (2)
"key.converter.apicurio.registry.global-id":
"io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategy", (3)
"value.converter": "io.apicurio.registry.utils.converter.ExtJsonConverter", (1)
"value.converter.apicurio.registry.url": "http://apicurio:8080", (2)
"value.converter.apicurio.registry.global-id":
"io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategy" (3)
...| 1 | The Apicurio JSON converter is used as both key and value converter |
| 2 | The Apicurio registry endpoint |
| 3 | This setting ensures that it is posible to automatically register the schema id which is the typical setting in Debezium deployment |
Avro Converter
So far we have demonstrated serialization of messages into the JSON format only. While using the JSON format with the registry has a lot of advantages, like easy human readability, it’s still not very space-efficient.
To transfer really only the data without any significant overhead, it is useful to use binary format serialization like Avro format. In this case, we would pack the data only without any field names and other ceremony, and again the message will contain a reference to a schema stored in the registry.
Let’s look at how easily the Avro serialization can be used with Apicurio’s Avro converter.
# Tear down the previous deployment
$ docker-compose -f docker-compose-mysql-apicurio.yaml down
# Start the deployment
$ docker-compose -f docker-compose-mysql-apicurio.yaml up -d --build
# Start the connector
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" \
http://localhost:8083/connectors/ \
-d @register-mysql-apicurio-converter-avro.jsonWe can query the registry using schema name:
$ docker run --rm --tty \
--network tutorial_default \
debezium/tooling \
bash -c 'http http://apicurio:8080/artifacts/dbserver1.inventory.customers-value | jq .'The resulting schema description is slightly different for the previous ones as it has an Avro flavour:
{
"type": "record",
"name": "Envelope",
"namespace": "dbserver1.inventory.customers",
"fields": [
{
"name": "before",
"type": [
"null",
{
"type": "record",
"name": "Value",
"fields": [
{
"name": "id",
"type": "int"
},
{
"name": "first_name",
"type": "string"
},
{
"name": "last_name",
"type": "string"
},
{
"name": "email",
"type": "string"
}
],
"connect.name": "dbserver1.inventory.customers.Value"
}
],
"default": null
},
{
"name": "after",
"type": [
"null",
"Value"
],
"default": null
},
...
],
"connect.name": "dbserver1.inventory.customers.Envelope"
}The connector registration request also differs from the standard one in a handful of lines:
...
"key.converter": "io.apicurio.registry.utils.converter.AvroConverter", (1)
"key.converter.apicurio.registry.url": "http://apicurio:8080", (2)
"key.converter.apicurio.registry.converter.serializer":
"io.apicurio.registry.utils.serde.AvroKafkaSerializer", (3)
"key.converter.apicurio.registry.converter.deserializer":
"io.apicurio.registry.utils.serde.AvroKafkaDeserializer", (3)
"key.converter.apicurio.registry.global-id":
"io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategy", (4)
"value.converter": "io.apicurio.registry.utils.converter.AvroConverter", (1)
"value.converter.apicurio.registry.url": "http://apicurio:8080", (2)
"value.converter.apicurio.registry.converter.serializer":
"io.apicurio.registry.utils.serde.AvroKafkaSerializer", (3)
"value.converter.apicurio.registry.converter.deserializer":
"io.apicurio.registry.utils.serde.AvroKafkaDeserializer", (3)
"value.converter.apicurio.registry.global-id":
"io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategy", (4)
...| 1 | The Apicurio Avro converter is used as both key and value converter |
| 2 | The Apicurio registry endpoint |
| 3 | Prescribes which serializer and deserializer should be used by the converter |
| 4 | This setting ensures that it is posible to automatically register the schema id which is the typical setting in Debezium deployment |
To demonstrate consumption of the messages on the sink side we can, for example, use the Kafka Connect Elasticsearch connector. The sink configuration will be again extended only with converter configuration, and the sink connector can consume Avro-enabled topics, without any other changes needed.
{
"name": "elastic-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "customers",
"connection.url": "http://elastic:9200",
"transforms": "unwrap,key",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.key.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.key.field": "id",
"key.ignore": "false",
"type.name": "customer",
"behavior.on.null.values": "delete",
"key.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"key.converter.apicurio.registry.url": "http://apicurio:8080",
"key.converter.apicurio.registry.converter.serializer":
"io.apicurio.registry.utils.serde.AvroKafkaSerializer",
"key.converter.apicurio.registry.converter.deserializer":
"io.apicurio.registry.utils.serde.AvroKafkaDeserializer",
"key.converter.apicurio.registry.global-id":
"io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategy",
"value.converter": "io.apicurio.registry.utils.converter.AvroConverter",
"value.converter.apicurio.registry.url": "http://apicurio:8080",
"value.converter.apicurio.registry.converter.serializer":
"io.apicurio.registry.utils.serde.AvroKafkaSerializer",
"value.converter.apicurio.registry.converter.deserializer":
"io.apicurio.registry.utils.serde.AvroKafkaDeserializer",
"value.converter.apicurio.registry.global-id":
"io.apicurio.registry.utils.serde.strategy.GetOrCreateIdStrategy",
}
}Conclusion
In this article we discussed multiple approaches to message/schema association. The Apicurio registry was presented as a solution for schema sotrage and versioning and we have demonstrated how Apicurio can be integrated with Debezium connectors to efficiently deliver messages with schema to the consumer.
You can find a complete example for using the Debezium connectors together with the Apicurio registry in the tutorial project of the Debezium examples repository on GitHub.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.