
Debezium provides a way to run the connectors directly within Debezium from the very beginning of the project. The way how it was provided has changed over the time and it still evolves. This article will describe another evolution step in this regard - new implementation of Debezium engine.
A bit of history
The capability to run the connector directly within Debezium was not present from the first Debezium commit, but was added really very early in the Debezium development as part of DBZ-1. This EmbeddedEngine was used mostly for testing. However, over the time it has evolved into a full-fledged runtime platform for the connectors, with the support for storing offsets, schema history etc. Later on, a public API for DebeziumEngine was defined ( DBZ-234). The interface decoupled the user-facing API from the implementation and provided the ability to replace the implementation by a different one. Shortly after introducing the Debezium engine API, a new Debezium server was created as part of DBZ-651. While EmbeddedEngine had to be wrapped into another application which would consume the records, the Debezium server provided a way to run Debezium outside the Kafka Connect cluster without such a wrapper. The Debezium server provided several sinks, so the users could use the server out-of-the-box without any further coding, but the Debezium server is still powered by the Debezium engine. As the popularity of the Debezium server increased, more and more sinks were added. This resulted in the separating Debezium server into separate GitHub project. The separation of the Debezium server repository happened relatively recently (DBZ-6049). The latest addition to the Debezium server evolution was implementation of Debezium operator. It allows seamless deployment and management of the Debezium server on the Kubernetes clusters. You can check this blog post for more details.
To sum-up, currently, if the user wants to run Debezium connectors outside the Kafka Connect cluster, there are three options. Users can embed the Debezium engine directly into their application or users can use a standalone Debezium server or, when run on the Kubernetes cluster, users can deploy the Debezium server via Debezium operator. However, no matter which deployment method the users use, all the hard work is done by DebeziumEngine implementation after all.
EmbeddedEngine limitations
As described in the previous section, if you decide to run Debezium outside the Kafka Connect cluster, the most important part (in terms of performance, sustainability etc.) is DebeziumEngine implementation. Up until recently, the only available implementation of DebeziumEngine was EmbeddedEngine. As also mentioned, EmbeddedEngine was originally implemented as a testing framework to make testing of the connectors easy, without the need to start the whole Kafka cluster. As such, EmbeddedEngine was not designed for the best performance or even production use. During the time, various improvements were done, but some original designs and code structure remained more or less the same.
The main limitation of the EmbeddedEngine is that it can run only one task. Therefore, if you have a connector which supports execution of multiple tasks (SQL server connector), you cannot use multiple tasks in EmbeddedEngine and still have to run everything in one task. Moreover, all the records are processed in a single thread. This means that the chain of single message transforms (SMTs), serialization as well as processing by the user handler is happening in a synchronous manner, as depicted on the figure below.
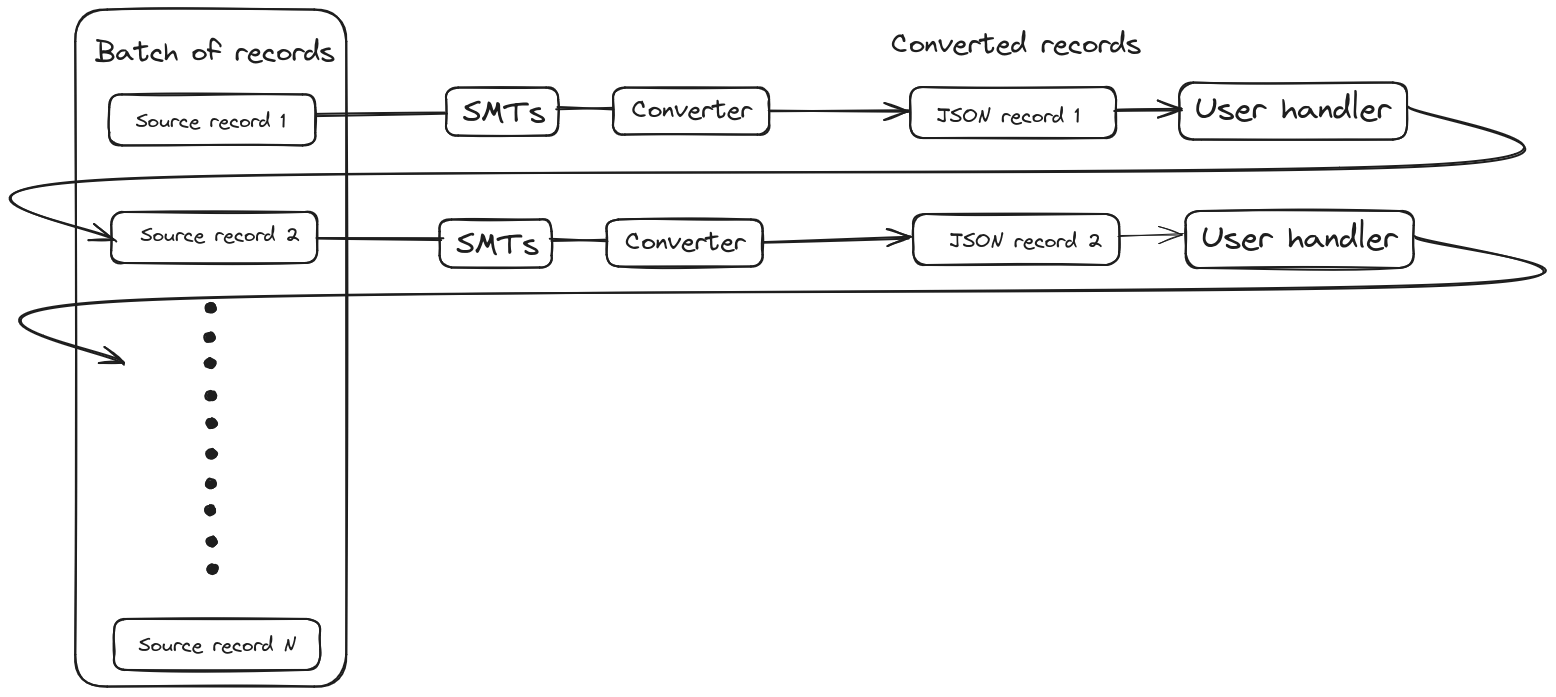
Once the whole pipeline is finished for the one record in the batch, only after that another record is processed. This mimics the behavior of Kafka Connect, which also does the source record processing in a serial manner.
From our performance tests as well as from the users reports on the Zulip chat, it seems that especially serialization is often a performance bottleneck. Naturally, one can immediately suggest running at least parts of the workloads, like serialization, in parallel. This would however require substantial changes in EmbeddedEngine. Current code structure of EmbeddedEngine was also far from perfect. Doing any changes e.g. in the retry mechanism was quite challenging and error prone. This led us to a decision to implement the DebeziumEngine API from scratch and create a new implementation of Debezium engine. Besides starting on a green field, it also gave us the comfort of testing the new engine only with a smaller part of the test suite and switching to new engine implementation gradually, always having an option to switch back to EmbeddedEngine as a backup. As a result AsyncEmbeddedEngine was created.
Asynchronous embedded engine
AsyncEmbeddedEngine is a new implementation of the DebeziumEngine interface. It addresses the main shortcomings of EmbeddedEngine as outlined in the previous section. Asynchronous engine allows connectors to execute multiple tasks. Most importantly, as the name suggests, aims to run record processing in parallel.
Architecture
From the high-level perspective there are two thread pools, a smaller one for managing tasks and bigger one for processing records. The size of the task thread pool corresponds to the number of configured tasks - each task has its own dedicated thread. The size of the record processing thread pool is also configurable, however, threads from this thread pool are shared across all the running tasks.
Records in an asynchronous engine are processed in parallel. To which extent the processing is parallelized depends on configuration. DebeziumEngine API offers two possibilities how to consume the changes: either via ChangeConsumer or via java.util.function.Consumer function. In the first case ChangeConsumer expects the whole batch of records as we can run in parallel only SMT chain and serialization. Once all the records in the batch are processed, the whole batch is passed to the user-defined ChangeConsumer.
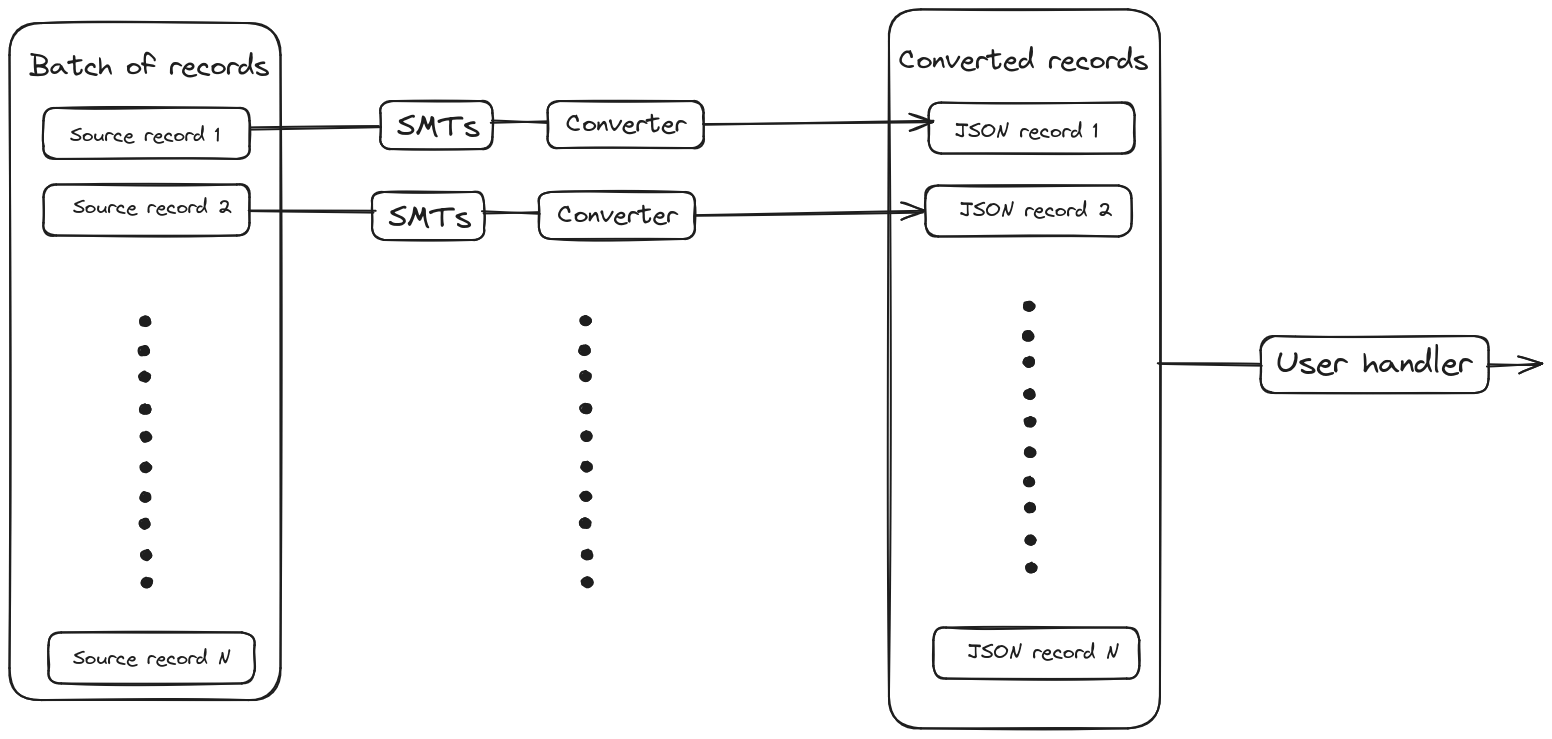
In the later case, when user provides only consumer function which processes just one record, we can run in parallel the whole record processing pipeline:
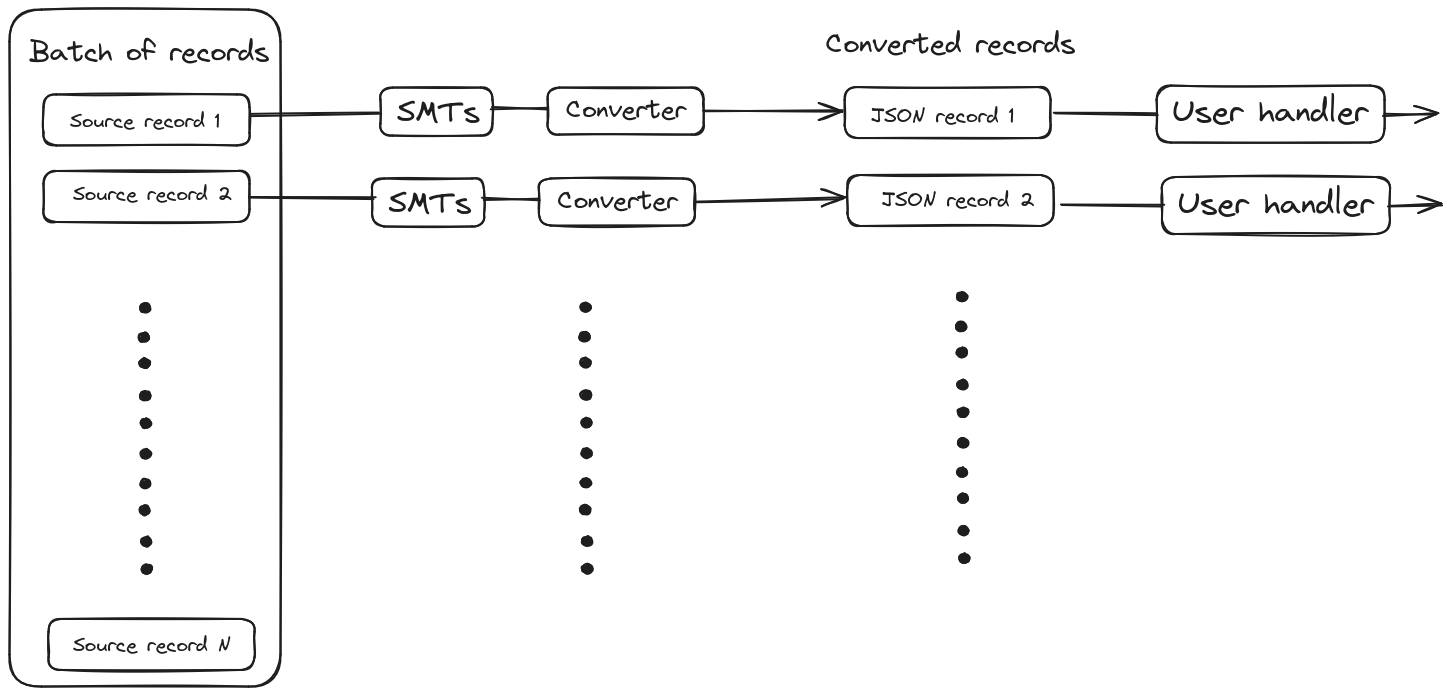
Pipelines can be processed in the same order as the original batch of the source records provided by the connector task or they can be processed completely asynchronously. Asynchronous processing of the whole pipeline means that the records could be sent to the sink in a different order than the changes were done in the source database. However, in some cases the order doesn’t matter (e.g. bulk inserts of distinct data) and what matters is speed of processing. Such use cases should be addressed by this setup.
This was a very high level overview of the asynchronous engine, which is required to fully understand configuration options described in the next section. If you are interested in more details, please see Design document for asynchronous engine. And of course the most precise and up-to-date source of information is the source code.
Usage
As AsyncEmbeddedEngine implements the same interface as EmbeddedEngine, the usage is also the same:
DebeziumEngine<ChangeEvent<String, String>> engine = DebeziumEngine
.create(KeyValueHeaderChangeEventFormat.of(Json.class, Json.class, Json.class), "io.debezium.embedded.async.ConvertingAsyncEngineBuilderFactory")
.using(props)
.notifying(record -> {
System.out.println("Key = '" + record.key() + "' value = '" + record.value() + "'");
}).build();
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(engine);If you want to use AsyncEmbeddedEngine, for now you have to use create(KeyValueHeaderChangeEventFormat<K, V, H> format, String builderFactory) method with io.debezium.embedded.async.ConvertingAsyncEngineBuilderFactory as the builder factory. Other shortcut builder methods still point to EmbeddedEngine.
Once you are done and want to terminate the engine, you call engine.close() as in the case of EmbeddedEngine. The main difference here is that once the AsyncEmbeddedEngine is closed, it cannot be started again and has to be re-created. The reason for this is to prevent possible resource leaks when the engine is being stopped and started from different threads in parallel (you can find more details in the design document and DBZ-2534).
Configuration options
Compared to EmbeddedEngine, AsyncEmbeddedEngine provides only a few additional configuration options, mostly related to thread management:
-
record.processing.threads- The size of the thread pool for record processing. -
record.processing.order- Determines how the records should be produced, eitherORDEREDorUNORDERED. -
record.processing.with.serial.consumer- Specifies whether the defaultChangeConsumershould be created from the providedConsumer. -
record.processing.shutdown.timeout.ms- Maximum time in milliseconds to wait for processing submitted records after a task shutdown is called. -
task.management.timeout.ms- Time limit engine waits for a task’s lifecycle management operations (starting and stopping) to complete.
record.processing.threads is quite clear, it’s the size of the shared thread pool used for processing records. You can use the AVAILABLE_CORES placeholder to use all available cores on the given machine.
record.processing.order - as described above, the records can be processed in the same order as the changes happened in the database or in a completely asynchronous manner which results in out-of-order delivery of the records to the sink. Which method is used is determined by this option. Please note that this option has any effect only in the case when user handler is provided as a Consumer function. As explained in the previous section, ChangeConsumer expects the whole batch of records and therefore the Debezium engine cannot ensure processing of individual records in parallel and setting it to UNORDERED processing has no sense in this case.
record.processing.with.serial.consumer determines, if the default ChangeConsumer should be created from user provided Consumer function. This is basically an option for backward compatibility with the EmbeddedEngine. In case of EmbeddedEngine is always used ChangeConsumer and if the user provides the Consumer function interested, EmbeddedEngine creates default ChangeConsumer. When you enable this option, AsyncEmbeddedEngine does the same and creates the same ChangeConsumer as EmbeddedEngine, so you can get completely the same behavior as in case of EmbeddedEngine.
record.processing.shutdown.timeout.ms specifies for how long the engine should wait for processing of submitted records. Once shutdown is called, no other records are submitted for processing, but you may want to wait for records already being processed. As processing of the records in general should be fast, this can be some smaller value (from dozen milliseconds to units of seconds).
task.management.timeout.ms determines the timeout for the task to start or stop. If the timeout is exceeded, the thread running the task is forcefully killed. When this timeout is exceeded during the startup and task is killed, all other tasks are killed as well. Either all the tasks have to start or none of them. Compared to record.processing.shutdown.timeout.ms, starting of the tasks can be quite time consuming (creating connections to the database etc.), so in this case the timeout should be substantially higher than timeout for record processing (possibly in terms of minutes).
Debezium server usage
Starting Debezium 2.6.0.Alpha2, Debezium server was switched to use AsyncEmbeddedEngine. Thus, if you use Debezium server 2.6.0.Alpha2 or later, you already use the asynchronous engine. As the Debezium engine currently uses only ChangeConsumer for processing CDC records, all constraints related to usage of ChangeConsumer mentioned above (impossibility to process records out of order) applies to the Debezium server as well. This can change in the future, but at the moment we don’t see any demand for it.
Deprecation of EmbeddedEngine
As of Debezium 2.7.0.Final, EmbeddedEngine was deprecated (DBZ-7976). We will keep it for about next 6 months. During this time we are going to migrate rest of our test suite to asynchronous engine (DBZ-7977) and then remove EmbeddedEngine in Debezium 3.1.0.Final (DBZ-8029). If you use the DebeziumEngine API, the migration should be very straightforward. The only thing you need to do if you use the converting wrapper is to switch from ConvertingEngineBuilderFactory to ConvertingAsyncEngineBuilderFactory, as described in the previous chapter. However, we would strongly recommend switching to the asynchronous engine sooner rather than later and eventually let us know if you spot any issue, so that we have sufficient time to fix any such issue before final removal of EmbeddedEngine.
Future steps and outlook
Besides the aforementioned removal of EmbeddedEngine, are we done with the changes or do we plan any further changes? Sure we plan to continue with the improvements! So what can you look for?
With Debezium 3.0 we will switch to Java 21 for building Debezium and in the future releases Java 21 will become Debezium base line. With this, we would like to switch to Java virtual threads. This may bring even more speedup and eventually also simplify the code a little bit. We will evaluate this option based on the results of our internal performance tests.
Speaking about performance tests, one may ask why at least some performance comparison is not mentioned in this blog post. We of course did some performance tests, we do have a some JMH benchmarks (PRs with improvements are welcome!) and also did some end-to-end performance tests. You can find some JMH results e.g. under this pull request, which also compares the results with EmbeddedEngine. On the other hand, we are fully aware of complexity and trickiness of performance testing and we believe having some solid results requires still some more work. It would deserve its own blog post anyway. After all, even with very solid performance results, the reality of your deployment may still be different, so what really matters is your performance tests, done on your hardware, your production network setup etc. If you do so, we would be more than happy to hear the results.
As for other things, we may add more implementations of RecordProcessors, e.g. one suggested by Jeremy Ford in the discussion under the asynchronous engine DDD.
In the longer term, we would like to add support for gRPC and Protocol Buffers. It should give us a two-fold advantage: Debezium engine should be able to coordinate execution of multiple tasks across different machines and also would be able to receive CDC records from them in the unified format. Ability to run multiple tasks (for connectors which allow it) on separate machines/containers is crucial especially in environments like Kubernetes, where you ideally want to run each task in a separate container. Defining Protocol Buffers format would allow Debezium to work with all kinds of connectors, written even in different languages and running on a large variety of devices, even on the edge, allowing the Debezium engine to become the heart of any CDC solution.
These are plans for which you can look forward to in the short and long term future. What we are looking for in the near future is your feedback on the new asynchronous engine. If you have any, please share it via common means on either Debezium Zulip chat or mailing list.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.