
Hello everyone, I’m René, data engineer at a Swiss insurance company. For round about four years now I have been using Debezium in several projects. Since I am not a Java developer I haven’t had the opportunity to contribute any code lines for Debezium in all these years. Nevertheless, or precisely because of that, I thought I could at least contribute a few written lines about a subject that is quite important probably not only for our company: the snapshot performance.
The duration of initial snapshot processes is crucial for us. Our pipelines (real-time ETL) stream data from various Oracle databases into the landing zone of the enterprise data warehouse. Looking at the biggest database we’re talking about a volume of 1.5 TB data that has to be pumped into the data warehouse. This is a huge amount of data. But not enough with that: due to the fact that the database we ingest data from is subject to frequent structural changes we are forced to do snapshots also fairly frequently (4 to 5 times a year). These snapshots are unavoidable unfortunately because - among other things - we also process LOB fields.
We like challenges. Our goal was to reach a similar snapshot time as we had with the old batch processes which we replaced by the new real-time pipelines. In other words, the bar was set high enough.
Our environment in a few points
Before we dive directly into the test results I want to illuminate some relevant facts about our environment:
Source database:
-
Oracle 19c, on prem, CDB
-
DB host has I/O bandwidth of 6 GB/s, shared by all the databases running on this host
-
Temp tablespace consists of 42 files each with 32 GB, shared by all the processes running on the database.
Note: The space available could reach its limit if there are too many parallel threads with high volumes (i.e. if you use order by clauses on big tables in override statements)
Kafka Connect:
-
3 nodes, RHEL VMs on prem, each with 12 CPUs, 62 GB RAM, 40 GB JVM
-
Kafka CP 7.7.1
-
Debezium 3.0, deployed on KC
Monitoring:
-
Prometheus and Grafana
Results from the tests
In my tests I primarily focused on the performance related properties. These are
on Debezium side:
snapshot.max.threads
snapshot.fetch.size
max.batch.size
max.queue.size
poll.interval.ms
on Kafka Connect side:
batch.size
linger.ms
compression.type
I experimented with these properties during my tests and got interesting insights. At this point I already reveal the settings that proved to be most effective in our case:
producer.override.batch.size: 1000000,
producer.override.linger.ms: 500,
producer.override.compression.type: lz4,
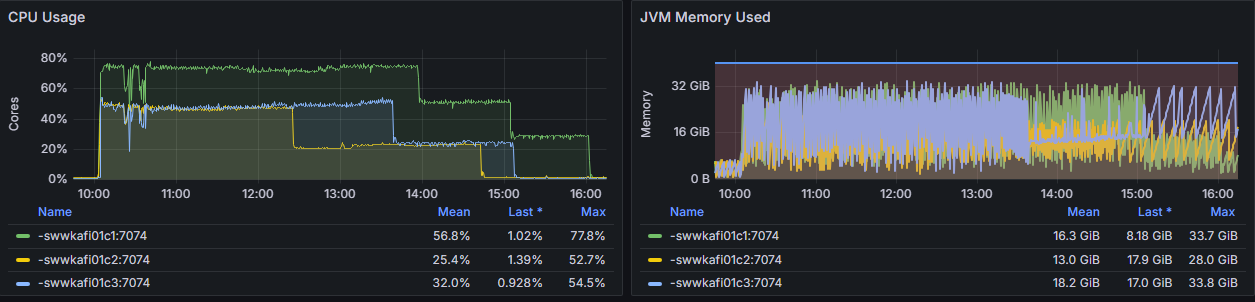
By using these settings we were able to achieve an optimization of 25%: from initially 8 hours we reduced the time for a complete snapshot to 6 hours (see figure 1). The CPU consumption as well as the JVM memory used never exceeded 80% throughout the whole snapshotting process.
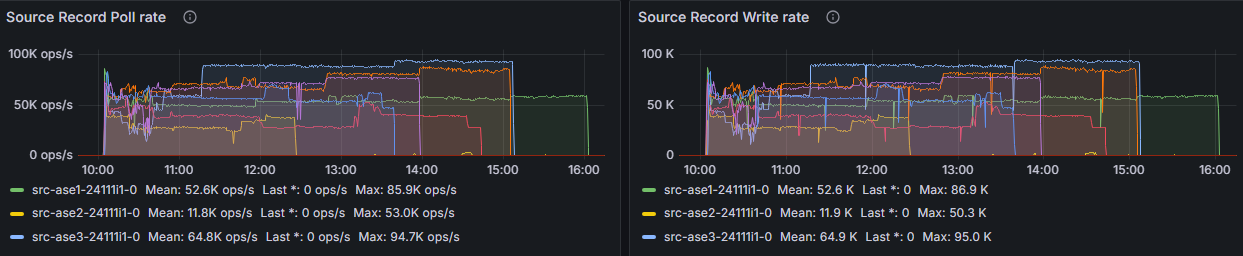
One metric I observed particularly was the source record poll rate. During my test this metric served as a helpful first indicator whether the performance was good or bad. As figure 2 illustrates a rate of up to 90k ops/s turned out to be the maximum. In any case I haven’t been able to reach a higher rate. Just as important was to have a look at its neighbor metric source record write rate which should show virtually the same diagram:
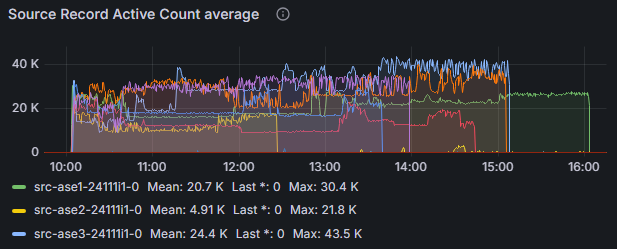
If polling is ok but pushing to Kafka wouldn’t be fast enough then the metric source record active count could be an identifier for that. Figure 3 shows that in our case we didn’t have to worry about any blocking:
As a matter of course we tried to be even faster and tested some more settings and combinations of them. Here are the results:
-
Changing
snapshot.fetch.sizeto 5000, 50000 or 200000: no improvement -
Changing
batch.sizeto 800000 or 2000000: no improvement -
Changing
linger.msto 10 or 100: no improvement -
Increasing
linger.msto 750 or 1000: led to more time spent in GC -
Changing
max.batch.sizeto 4000 or 8000: no improvement -
Changing
max.batch.sizeto 8000,max.queue.sizeto 16000,snapshot.fetch.sizeandquery.fetch.sizeto 50000: no improvement, more time spent in GC, higher CPU consumption -
Changing
poll.interval.msto 100: no improvement
As you see none of these attempts really brought any improvement, most of them were slower. Setting the value of snapshot.max.threads to the total number of tables we extract data from didn’t accelerate the process either and furthermore was delicate because of the massive load on the shared database resources. With too many parallel threads we even encountered that the connector crashed owing to “ORA-12801: error signaled in parallel query server”.
Conclusion
Although we didn’t manage to reach our goal completely (we are still 2 hours above the targeted snapshot time) the performance optimization we accomplished is good enough for us at the moment. It is clear to us that performance optimization is an iterative process and we need to continuously monitor, analyze, and tune our whole system for optimal performance.
Performance optimization is definitely not an easy thing and requires perseverance. To obtain an optimal performance it is necessary to find the right parameters respectively properties and to get the ideal balance between them. If you consider changing the compression type don’t forget to think about the impact this change can have to all the downstream processes. For better end to end performance we decided to define the same compression type in ksqlDB’s default value configuration.
Finally I want to emphasize an interesting fact: in our tests we didn’t have to change any default value of Debezium’s performance related properties, which is kind of soothing. All the improvements we achieved was by modifying Kafka Connect producer properties.
If you have any questions or advice please don’t hesitate to contact me on zulipchat.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.