
The Debezium project is starting off 2025 with a tremendously fun filled release of Debezium 3.1.0.Final. This release includes a myriad of features across multiple connectors, transformation support with WebAssembly and Go, our first official release of the Debezium Management Platform, two brand-new Debezium Server sinks for vector databases and large language models, a new AI module, and that’s not the half of it!
In this post, we’re going to take a deep dive into all the changes in Debezium 3.1, discussing new features, and explaining all the possible changes that could have any impact to your upgrade process. As always, we recommend you read the release notes to learn about all the bugs that were fixed, update procedures, and more.
Breaking changes
With any new release of software, there is often several breaking changes. This release is no exception, so let’s discuss the major changes you should be aware of before upgrading to Debezium 3.1.0.Final.
Debezium Core
This section describes all breaking changes related to core Debezium. These breaking changes generally affect all connectors and modules, and should be reviewed carefully.
Event source block is now versioned
A Debezium change event contains a source information block that depicts attributes about the origin of the change event. The source information block is a Kafka Struct data type, and can be versioned; however, in older versions of Debezium the version attribute was left empty.
The source information block is now versioned, and will be set to a version of 1 (DBZ-8499). As future changes are implemented, the version will be incremented accordingly.
| For those using schema registry, this change may likely introduce schema compatibility issues. |
Sparse vector logical type renamed
The PostgreSQL extension vector (aka pgvector) provides an implementation of a variety of vector data types, including one called sparsevec. A sparse vector stores only populated key/value entries within the vector, excluding pairs that are empty set to minimize the data set’s storage requirements.
Debezium 3.0 introduced the SparseVector logical type named io.debezium.data.SparseVector. After evaluating implementations for other relational databases, we determined that the logical name was insufficient to implement other sparse vector types (DBZ-8585).
To address this concern, we have repackaged the io.debezium.data.SparseVector class from the PostgreSQL connector into Debezium’s core package. We’ve also renamed the class to SparseDoubleVector, and changed the logical name to io.debezium.data.SparseDoubleVector to align with the class name changes.
| For those who may have been working with |
Changes to schema history configuration defaults
The documentation for schema.history.internal.store.only.captured.databases.ddl used an incorrect default value. While this is not a code-specific breaking change, you should take a moment and reevaluate whether your deployment’s configuration depends on the different default value or not (DBZ-8558).
Debezium Storage module
JDBC storage configuration naming convention changed
The JDBC storage configuration used configuration property names that were not consistent with conventions used by other storage modules. In Debezium 3.1, we have aligned the naming convention, while preserving the legacy names for a transition period (DBZ-8573). The following show the old configuration property names and the new naming you should plan to migrate toward:
| Legacy Property Name | New Property Name |
|---|---|
|
|
|
|
|
|
|
|
Debezium for Oracle
Several Oracle LogMiner JMX metrics were removed
A number of Oracle LogMiner JMX metrics were deprecated in Debezium 2.6 and replaced with new metrics. The following chart shows the JMX metrics that have either been replaced or removed.
| Removed JMX Metric | Replacement |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Removed with no replacement. |
Please be sure to review your monitoring and observability infrastructure and adjust accordingly if you were still relying on any of the deprecated metrics (DBZ-8647).
Reselect column post processor behavior changed
The ReselectColumnsPostProcessor will reselect Oracle LOB columns even when the lob.enabled configuration property’s value is not enabled. This change enables users who may not want to mine LOB columns while streaming to still populate the LOB column using the column reselection process as an alternative (DBZ-8653).
Query timeout now applies to Oracle LogMiner queries
When the Oracle connector executes its initial query to fetch data from LogMiner, database.query.timeout.ms connector configuration property will control the duration of the query before the query is cancelled (DBZ-8830). When upgrading, check the connector metric MaxDurationOfFetchQueryInMilliseconds to determine whether this new property may need adjustments. By default, the timeout is 10 minutes, but can be disabled when set to 0.
Debezium for Vitess
Potential data loss
The Debezium for Vitess connector had a rare but critical data loss bug that has existed since it was first introduced five years ago. If a primary key update is the last operation in a transaction, records may be lost. This bug affects all prior versions. It is highly recommended that users perform an immediate update to 3.1 or later to remedy this potential data loss (DBZ-8594).
New features and improvements
The following describes all noteworthy new features and improvements in Debezium 3.1.0.Final. For a complete list, be sure to read the release notes for more details.
Debezium Core
New adaptive temporal precision mode types
Debezium has long supported a variety of time.precision.mode types like adaptive and connect. Three new modes have been added to provide even more customization and choice for temporal-based columns (DBZ-6387, DBZ-8826).
| Mode | Description |
|---|---|
| Configures the connector to map temporal values as ISO-8601 formatted strings in UTC. |
| Configures the connector to map temporal values with microsecond precision, if available. |
| Configures the connector to map temporal values with nanosecond precision, if available. |
When using microseconds or nanoseconds based precision modes, the connector will use different semantic types based on whether the field is a DATE, TIME, or TIMESTAMP-based. Please review your specific connector documentation for details on how this is interpreted by a connector.
CloudEvent traceparent support
Debezium’s CloudEvents support has been updated to include support for the traceparent attribute, which provides the ability to integrate with OpenTelemetry to pass trace details as part of the event (DBZ-8669).
By setting the opentelemetry.tracing.attributes.enabled configuration property to true along with including the traceparent:header as part of the metadata.source, this information will be made available to the CloudEvents converter.
You can customize the way that the conver populates the fields by changing the defaults and specifying the fields' values in the appropriate headers. For example:
{
"value.converter.metadata.source": "value,id:header,type:header,traceparent:header,dataSchemaName:header"
}You can find other examples in Debezium’s CloudEvents documentation.
Content-based routing/filtering using WASM
The Debezium scripting module includes support for running scripts using Chicory, a native JVM runtime for web assemblies (WASM) (DBZ-8658).
Given the following Go-based program:
package main
import (
"github.com/debezium/debezium-smt-go-pdk"
)
func process(proxyPtr uint32) uint32 {
var topicNamePtr = debezium.Get(proxyPtr, "topic")
var topicName = debezium.GetString(topicNamePtr)
return debezium.SetBool(topicName == "theTopic")
}
func main() {}This Go program can be compiled into a web assembly .wasm file and then used by the ContentBasedRouter or Filter transformations. The following example shows how you would use this with the Filter transformation:
{
"transforms": "route",
"transforms.route.type": "io.debezium.transforms.Filter",
"transforms.route.condition": "<path-to-compiled-wasm-file>",
"transforms.route.language": "wasm.chicory"
}In this example, if the event’s topic matches theTopic, the event is passed, otherwise the event is dropped.
For more information, you can see the documentation on the Filter SMT and the Content-based Router SMT.
TinyGo WASM data type improvements
Debezium’s scripting transformation solution provides the ability to write scripts using Go, and compile them into WebAssembly. The ChicoryEngine runtime now includes coverage to support accessing and working with Struct, Map, and Array Kafka schema types. In addition, accessors are included for more concrete types such as Int8, Int16, Int32, Int64, Float32, Float64, Bool, and Bytes.
package main
import ( "gihub.com/debezium/debezium-smt-go-pdk" )
//export process
func process(proxyPtr uint32) uint32 {
var op = debezium.GetString(debezium.Get(proxyPtr, "value.op"))
var beforeId = debezium.GetInt8(debezium.Get(proxyPtr, "value.before.id")) // Uses new GetInt8
// value.op != 'd' || value.before.id != 2
return debezium.SetBool(op != "d" || beforeId != 2)
}
func main() {}Schema access support in WASM transformation
You can now access some schema details inside your TinyGo programs using the WASM transformation (DBZ-8737). The GetSchemaName and GetSchemaType methods are now included to support reading specific schema details.
package main
import( "githu.com/debezuim/debezium-smt-go-pdk" )
//export process
func process(proxyPtr uint32) uint32 {
var valueSchemaType = debezium.GetSchemaName(debezium.Get(proxyPtr, "valueSchema"))
var opType = debezium.GetSchemType(debezium.Get(proxyPtr, "valueSchema.op"))
// Filter where schema type or opType match
return debezium.SetBool(valueSchemaType == "dummy.Envelope" || opType == "string")
}
func main() {}| We welcome any and all feedback on how to improve the experience with the WASM transformation. Please reach out on our Zulip chat or log Jira enhancements. |
ExtractChangeRecordState transformation always adds headers
The ExtractChangeRecordState transformation is used to add user configured event headers that describe what fields were changed or what fields were left unchanged in the event’s payload. However, when this transformation is paired with other transformations that may expect the header to exist, this could lead to unexpected behavior. While users could work around this limitation using Kafka single message transformation predicates, we felt that anything we could do to help minimize configuration bloat was a net benefit.
Moving forward, the ExtractChangeRecordState will always add the changed and unchanged headers to your event, even if the event is an insert or delete, and even if those fields are left empty (DBZ-8855).
| If your pipeline has relied on |
Error handling modes for Reselect column post processor
The ReselectColumnsPostProcessor is designed to supplement the streaming process, querying the current values for specific columns that require reselection based the connector configuration. This process is meant to be seamless and will use the streamed column data as a last resort if the query fails.
The following configuration property has been added:
reselect.error.handling.mode-
Specifies how to handle errors when the reselect query fails. By setting this to
warn, a warning will be logged when the reselect query fails, passing the streamed event data as-is. By setting this tofail, the connector will throw an exception when the reselect query fails.
The default for reselect.error.handling.mode is warn to retain old expected behavior (DBZ-8336).
Centralize logging of sensitive data
We understand that databases house all sorts of information, and that some columns may contain sensitive information. We take pride in making sure that information remains safe and secure. For this reason, we generally prefer to avoid logging sensitive information at INFO, WARN, or ERROR levels.
However, there were some potential corner cases where sensitive column values may be logged at DEBUG or TRACE levels. We added the io.debezium.util.Loggings class several versions ago to centralize this, but not all instances were using this Loggings class (DBZ-8525).
By default, users will notice that the Loggings class records the sensitive information in the logs rather than it included in the original logger in the proceeding log entry. If you prefer to omit the sensitive information, logging configuration can be used to uniquely set a logging level specific to io.debezium.util.Loggings.
For example, if you need to provide your logs to someone but want the sensitive information omitted, the following configuration can achieve that goal.
log4j.logger.io.debezium=TRACE,stdout
log4j.logger.io.debezium.util.Loggings=ERROR,stdoutThis configuration will omit all sensitive information while logging all non-sensitive information at TRACE level.
Debezium Storage module
Explicitly use path-style addressing with S3 storage
The S3 SDK introduced a small behavior change in 2.18+ where the URLs are built using virtual-host style instead of path style, as discussed in the upstream S3 SDK community. While the S3 bucket supports both styles of URL, there may be cases, including test cases where the virtual-host style may not yet be supported.
We have added a new configuration option schema.history.internal.s3.forcePathStyle which defaults to false (DBZ-8569). In situations where you may need path style URLs rather than virtual-host style URLs, setting this to true will restore the old URL behavior.
Debezium for MariaDB
SSL support
We have introduced several new MariaDB-specific modes designed to allow the MariaDB connector to connect using SSL that are aligned and compatible with the MariaDB driver (DBZ-8482). The following table describes the modes and the MySQL equivalents if you’re moving from an older MySQL connector deployment to the new standalone MariaDB connector.
| Mode | Description |
|---|---|
| Disables the use of SSL/TLS connectivity. All connections are insecure. This is the equivalent to MySQL’s |
| Uses SSL/TLS for encryption, but does not perform certificate or hostname verification. This is the equivalent to MySQL’s |
| Uses SSL/TLS for encryption and performs certificate validation, but not host verification. This is the equivalent to MySQL’s |
| Uses SSL/TLS for encryption and performs certificate and host validation. This is the equivalent to MySQL’s |
For MariaDB, these properties are passed using the database.ssl.mode property.
Debezium for MySQL
Percona minimal locking
A new snapshot.locking.mode was added to Debezium for MySQL Percona users reducing the amount of locks that occurs during the snapshot. The new mode, minimal_percona_no_table_locks, provides the same semantics as minimal_percona, but additionally omits applying table-level locks (DBZ-8717). This provides an alternative for some environments where table locks are not permitted.
Improved error handling for duplicate server id/uuid
For most connectors, Debezium adopts the philosophy of retrying all SQLException or IOException related failures. This strategy has been quite useful, allowing users to utilize the runtime retry mechanism as needed.
However for MySQL, this presents a unique corner case when there are conflicts with the configured server id/uuid. MySQL uses the server id/uuid to uniquely identify an instance on the cluster topology. If more than one server uses the same id/uuid, the instance will throw a SQLException and enter a retry/backoff loop on startup.
We have adjusted the error handling so it prefers a fail-fast approach for this specific unique case (DBZ-8786). If you are a MySQL user and notice your connectors are entering a FAILED status more frequently, we recommend checking if this use case applies to you. If it does, you should guarantee that your configuration always uses a unique server id/uuid value.
Debezium for Oracle
New Oracle LogMiner JMX metrics
We have added a new Debezium Oracle connector JMX metric, MinedLogFileNames. This metric returns a string array (String[]) consisting of log file names that are being read in the current LogMiner session (DBZ-8644).
| When users report lag with the Oracle connector, one of the first things we check is how many logs are being read in the mining session. When an unusually large number of logs are added, this can create a bottleneck while Oracle LogMiner reads all these logs from disk. This metric provides visibility into the number of mined logs without adjusting the connector’s logging levels. If you observe lag, one of the first things is to check how many logs are in this metric. A high volume of logs typically indicates potentially a high burst activity window on your database. |
New source info scn and timestamp fields
Several new fields were added to the source information block for Oracle change events (DBZ-8740). These new source fields include:
commit_ts_ms-
This specifies the time in milliseconds when the event’s transaction was committed.
start_scn-
This specifies the SCN for the first event observed in the event’s transaction.
start_ts_ms-
This specifies the time in milliseconds when the first event in the event’s transaction was changed by the user.
These new fields are optional, so schema registry users should find these changes are backward compatible.
| Oracle SCN values are not unique, so it is possible for multiple events to have the same SCN value and timestamps. Care should be taken when using these values for any type of event ordering. |
Debezium for SQL Server
Streaming memory improvements
The Microsoft SQL Server driver is unable to multiplex when multiple selects are executed on the same connection. This often leads to all data buffered to memory, which can be quite inefficient or result in memory issues.
Debezium introduced a new configuration option, streaming.fetch.size, to help address this SQL Server driver limitation (DBZ-8557). This configuration option specifies the maximum number of rows that should be read in a single fetch from each table while streaming. By default, this is set to 0 so that connector behavior remains unchanged. When set to a positive value, this results in multiple data round trips to the database to fetch the data in batches based on the configured fetch size.
Always use clustered indices if available
When using data.query.mode set to direct, the query’s order by may often perform poorly because the query does not leverage the clustered index on the captured table. This typically necessitates a custom database index to achieve good performance.
We have adjusted the query to take this into account, and now include the __$command_id as part of the result set order by clause (DBZ-8858). This enables the database to use the clustered index, and reduces the cost of the query substantially, yielding overall better performance without any database index customizations.
Debezium for Vitess
Emit binary collation string data types as Kafka strings
In an older change as part of DBZ-6748, we changed the connector to serialize varchar column types that had binary collation as Kafka string types. However, other character-driven data types like text, tinytext, mediumtext, longtext, enum, and set were overlooked and these continued to be serialized as byte arrays.
The behavior is now aligned so that all variants of text, enum, and set data types are always emitted as Kafka string types, even when the column uses binary collation (DBZ-8679, DBZ-8694).
| Be aware that if you use schema registry, the change in how these column types are serialized with binary collation may introduce schema backward compatibility issues. |
Changes to Epoch/Zero date column resolution
When a date column is a zero date value, depending on the optionality of the column, the field may be emitted as null or as the unix epoch. This creates an unresolvable situation for consumers as it’s impossible for them to differentiate when the epoch value is provided, if it represents a real epoch value or the sentinel that represents the zero date in the source system.
To address this issue, we have added the override.datetime.to.nullable configuration property. When set to its default of false, such scenarios continue to use the old behavior, emitting a unix epoch when the column isn’t nullable but contains a zero date. This means that consumers will continue to be unable to differentiate between the two use cases.
When set to true, all date and datetime columns are set as optional and serialized with null if the column’s value represents a zero date. This allows consumers to easily differentiate the use cases and handle these more appropriately.
Keyspace heartbeat support
A new binlog watermarking strategy was introduced for VStream in Vitess version 21. This new feature sends a "heartbeat" -like event that represents the shard’s binlog events up to the provided timestamp have been received by the VStream client.
A new configuration option vitess.stream.keyspace.heartbeats can be set to true to include the heartbeat events written to the keyspace heartbeat tables (DBZ-8775). The table.include.list should also include the heartbeat table, using the format <keyspace>.heartbeat.
Improved enqueue speed
While performance testing the connector, several operations were identified that executed unnecessarily on each event dispatch, wasting valuable CPU cycles. This lead to situations where the internal queue was often empty, limiting the overall throughput of the connector.
These code hotspots now used cached values to minimize wasted CPU cycles. The buffer now remains full under load and yields twice the performance that was previously observed (DBZ-8757).
Queries specify workload tag
Most queries now include a SQL hint/comment of /*vt+ WORKLOAD_NAME=debezium */ to identify that the query is being executed by the Debezium connector (DBZ-8861).
Debezium JDBC sink
Supports MySQL/PostgreSQL vector data types
We introduced a variety of vector data types as part of Debezium 3.0 in late 2024, which included vector for MySQL/PostgreSQL and halfvec/sparsevec for PostgreSQL. With Debezium 3.1, we’ve extended support for these data types to the JDBC sink connector (DBZ-8571).
This new mapping includes several rules:
-
MySQL to MySQL or MySQL to PostgreSQL, the
vectordata type is mapped automatically. -
PostgreSQL
vectorto PostgreSQL or MySQL, thevectordata type is mapped automatically. -
Replication of
halfvecandsparsevecare mapped automatically if the target is PostgreSQL only.
For target databases that do not have a native mapping for vector data types or has no support for such types, the field cannot be natively written to the target system. For such use cases, you can use the io.debezium.transforms.VectorToJsonConverter transformation to alter the event payload in-flight to a JSON representation, which most databases universally support. The target column type in the database will then either be json, clob, or a text-based column type depending on the database vendor.
As more source database vector types are supported, we’ll continue to expand this in the future.
Performance improvements
We received several community reports that during peak volume, some databases were experiencing unusually high CPU utilization. After investigation, we identified that several SQL queries were performed too frequently, causing the high CPU and reducing connector write throughput (DBZ-8570). Users should now find that the JDBC sink’s write throughput is higher and the CPU utilization should be more reasonable than before.
Automatic retries on connection errors
For a Kafka Connect producer, if a connector throws a RetriableException and Kafka Connect is configured to support retries on errors, the runtime will automatically stop and restart the connector. This provides a useful way to handle the tearing down of resources and recreating those resources, such as database connections.
But for a Kafka Connect consumer (sink), the lifecycle of the connector works differently. When the connector throws an error, the lifecycle doesn’t stop and restart the connector, but instead calls the put method again. This can be problematic in the case of certain connection errors because specific resources are not automatically recreated.
Starting with Debezium 3.1, a new JDBC sink connector property connection.restart.on.errors will allow the JDBC sink to retry connection failures (DBZ-8727).
Handle BYTES as VARBINARY for SQL Server targets
A new JDBC sink mapping has been added for converting a Kafka BYTES field to VARBINARY column data types (DBZ-8790). This allows source connectors that serialize unknown or other binary data as a Kafka BYTES field to me correctly mapped to a SQL Server target with the VARBINARY column data type.
Debezium Server
New Milvus sink
Milvus is an open-source vector database designed for search and retrieval of high-dimensional data, such as embeddings from machine learning models. You can use Milvus to process vector data types that are captured from a source database, or use it with a transformation to calculate vectors from message fields, and then use them as embeddings.
The Milvus sink ingests incoming messages and upserts the after part of a Debezium change event into a collection. When a Debezium delete change event is observed, the matching record is removed from the collection (DBZ-8634).
To get started with this new sink, the following configuration can be specified:
debezium.sink.type=milvus
debezium.sink.milvus.url=http://localhost:19530
debezium.sink.milvus.database=defaultIn addition, you can also modify the behavior of the Milvus sink by applying custom logic that provides alternative implementations for specific functions. These extension points include:
io.milvus.v2.client.MilvusClientV2.MilvusClientV2-
An instance of a custom MilvusClientV2 client that is configured to access target collections.
io.debezium.server.StreamNameMapper-
Custom implementation that maps the name of the planned destination topic to a Milvus collection. By default, dots in a name are replaced with underscores.
You can find more information in the Milvus documentation or in the Debezium documentation.
New Instructlab sink
InstructLab is an open-source project that aims to democratize generative AI by providing a community-driven approach to enhancing large language models (LLMs) through skills and knowledge training. This uses a technique referred to as LAB, (Large-scale Alignment for Chatbots).
The InstructLab sink ingests incoming messages and generates a series of question and answers with optional context values based on mappings to payload fields, and then update your taxonomy skill and knowledge domains in near real-time (DBZ-8637).
To get started with this new sink, several key types of configuration must be specified.
{
"debezium.sink.type": "instructlab",
"debezium.sink.instructlab.taxonomy.base.path": "/mnt/ilab/taxonomy",
"debezium.sink.instructlab.taxonomies": "domainA,domainB",
"debezium.sink.instructlab.taxonomy.domainA.topic": ".*",
"debezium.sink.instructlab.taxonomy.domainA.question": "header:question",
"debezium.sink.instructlab.taxonomy.domainA.answer": "header:answer",
"debezium.sink.instructlab.taxonomy.domainA.domain": "a/subdir-a/subpath-a2/",
"debezium.sink.instructlab.taxonomy.domainB.topic": "my_topic",
"debezium.sink.instructlab.taxonomy.domainB.question": "value:field",
"debezium.sink.instructlab.taxonomy.domainB.answer": "value:field",
"debezium.sink.instructlab.taxonomy.domainB.context": "value:context",
"debezium.sink.instructlab.taxonomy.domainB.domain": "b/subdir-b/"
}The taxonomy mappings are all defined using the debezium.sink.instructlab.taxonomy.* namespace. These mappings used a named key, just like transforms, to define a set of configuration mappings for a given taxonomy. Each taxonomy mapping defines a question, answer, and an optional context configuration that defines where in the event the value will be sourced for that part of the taxonomy mapping.
Each taxonomy domain mapping can be applied to one or more events based on the domain’s topic configuration property. This defines a regular expression used to match against the event’s topic. The default is .*, so if you omit the topic configuration property, the mapping will always be applied to all incoming events.
Lastly, the domain configuration property specifies a / separated list of directories that will be appended to the taxonomy.base.path property, which uniquely identifies the directory where the sink will either create or update the qna.yml file with the sourced mapping values.
You can find more information in the InstructLab documentation or in the Debezium documentation.
Pulsar key-based batch support
We have added a new and improved throughput option when using Apache Pulsar’s KeyShared subscription. The configuration option, debezium.sink.pulsar.producer.batchBuilder can be set to KEY_BASED, but defaults to DEFAULT (DBZ-8563).
When set to use KEY_BASED, this subscription model delivers messages with the same key to only one consumer in order. More information about Key_Shared subscription model can be found in the Apache Pulsar documentation.
PubSub sink supports concurrency and compression
In order to improve throughput and capacity with Google PubSub, we have introduced the ability to specify several new configuration properties for PubSub to support concurrency and compression (DBZ-8715). These new configuration properties can be used in any existing PubSub configuration.
pubsub.concurrency.threads-
This specifies the number of threads to be used to publish messages to Google PubSub. This can be used to scale up or to limit the number of PubSub threads created by the Google PubSub client library. By default, the PubSink uses the default behavior of the client library.
pubsub.compression.threshold.bytes-
When set to a value of
0or greater, the PubSub sink enables the optional use of compression to transmit batches of events to the PubSub endpoint. Whether compression will be used is defined by the provided threshold value. If the batch’s total bytes is less-than the threshold, compression will not be used. If the batch’s total bytes is equal-to or greater than the threshold, compression will be used.
PubSub sink supports locational endpoints
When working with the PubSub sink, the pubsub.address is often not sufficient for production systems where you may need to interact with location-specific (aka region) endpoints. To address this concern, we have introduced a new configuration property, pubsub.region (DBZ-8735).
The new pubsub.region property allows specifying the Google Cloud region to connect, i.e. us-central1 or asia-northeast1. When specified, Debezium will use the location-specific endpoint for PubSub in the format <region>-pubsub.googleapis.com:443. This permits connecting to the location-specific endpoint instead of the global endpoint.
| The |
RabbitMQ sink supports key based routing
We have changed how you can route events using configuration. This new approach uses a strategy-based design, that retains old behaviors and introduces the new key-based routing mechanism (DBZ-8752).
First and foremost, the rabbitmq.routingKeyFromTopicName is deprecated and will be removed in a future release. This functionality has been folded into the new rabbitmq.routingKey.source configuration property, and it can be set one to one of the following values:
static-
When using the static routing source, the RabbitMQ sink will use the
rabbitmq.routingKeystatic value you have specified in the sink’s configuration. As this value is set in the configuration and read only during the sink startup, the value is static and does not change over the runtime of the sink. topic-
When using the topic routing source, the RabbitMQ sink will source the routing key based on the destination topic name. This mode replaces the old
rabbitmq.routingKeyFromTopicNameconfiguration property behavior, which is now deprecated. key-
When using the new key routing source, the RabbitMQ sink will source the routing key based on the event’s record key. This provides the flexibility to control the routing mechanism for RabbitMQ to use the raw Debezium change event’s key or by using a custom transformation to change the event’s key in-flight before sending the event to RabbitMQ.
Debezium Platform
What is Debezium Platform?
A year ago we began this incredible journey to create a new, modern user interface for Debezium Server that aimed to ease the deployment of Debezium on Kubernetes. We are excited that Debezium 3.1 is the first official release of this years-long effort.
The new Debezium Platform provides a modern pipeline-based approach to designing source and sink configurations, transformation chains, and more within seconds. You can install the Debezium Platform using helm as follows:
helm install debezium-platform --set domain.url=<your-domain> --version 3.1.0-final oci://quay.io/debezium-charts/debezium-platformFor more details on how to deploy using helm, see the README.md.
In addition, this release specifically adds some finishing touches to the user interface, which includes new search/list-view toggles, display applying transforms and editing of connector pipelines, and lastly experienced-user smart editors during configuration of a pipeline.
The following videos show how to use these new features:
Predicate support in Transformation UI
The team has been hard at work improving the new and upcoming Debezium Management Platform, a modern management interface for Debezium deployments on Kubernetes.
In this release, we’re pleased to share that we’ve added support for defining predicates as part of the single message transformation interface. Below is a quick glimpse at this new interface (DBZ-8590).
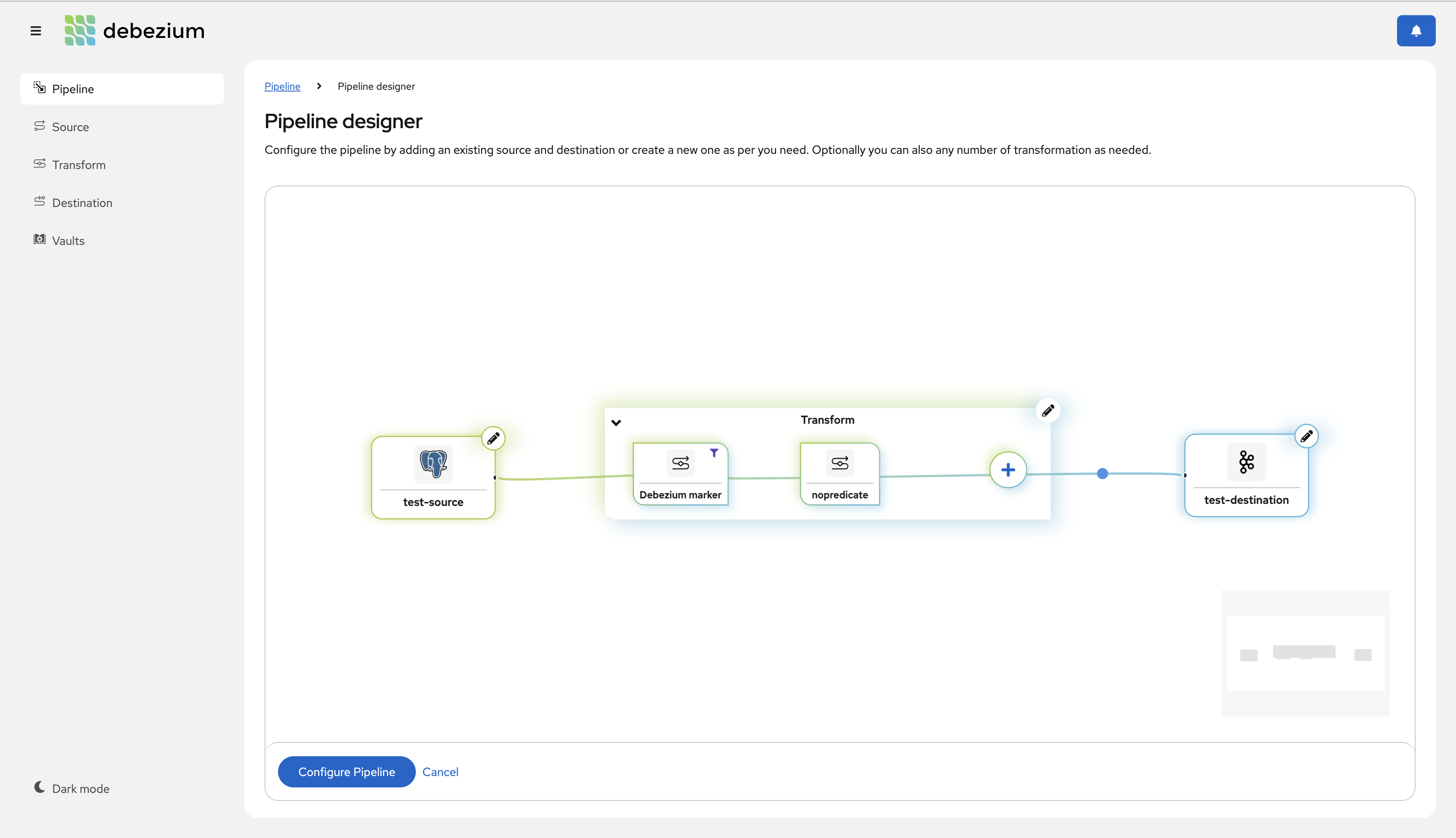
Night container images
We have begun publishing nightly images of the Debezium Management Platform, a modern management interface for Debezium deployments on Kubernetes (DBZ-8603).
quay.io/debezium/platform-conductor:nightly-
The backend service that provides administrative APIs to orchestrate and control Debezium deployments on Kubernetes. The image can be fetched using
docker pull quay.io/debezium/platform-conductor:nightly. quay.io/debezium/platform-stage:nightly-
The front-end that provides the user interface to interact with the conductor-based backend. The image can be fetched using
docker pull quay.io/debezium/platform-stage:nightly.
For more information, please see the README.md.
| While these containers are not intended for production, they’re a great way to explore the Debezium Management Platform. We’re really excited about this new component, and would love to hear your feedback. |
Debezium AI
Introduction
The Debezium AI module is a brand-new component in Debezium 3.1. The goal for this module is to include all AI-centric behavior, utilities, and more in the Debezium portfolio.
If you are interested in including the Debezium AI module in your own project using Debezium Embedded, the module is available by importing the following POM into your project:
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-ai</artifactId>
<version>3.1.0.Final</version>
<type>pom</type>
</dependency>LangChain4j based Embeddings Transformation
As one of the first features of the Debezium AI module is the Langchain4j based Embeddings transformation. This SMT uses a configuration-driven approach to define an input value that is supplied to a large language model (LLM) of your choice, and appends a generates embeddings field to the event’s payload (DBZ-8702).
Debezium provides support for MiniLM and Ollama, but can be extended through code to work with a wide range of models using the LangChain4j library. Let’s take a few moments to talk about the Debezium built-in implementations.
- MiniLM
-
The
all-MiniLM-L6-v2model is a sentence-transformer that maps sentences and paragraphs into a 384-dimension dense vector. Such vectors can be used for tasks like clustering, semantic searches, or comparisons.
To add the embeddings transformation for MiniLM to your transformation chain, simply add the following:{ ..., "transforms": "minilm", "transforms.minilm.type": "io.debezium.ai.embeddings.FieldToEmbedding", "transforms.minilm.field.source": "after.documentation", "transforms.minilm.field.embedding": "after.embedded_documentation" }In this example, the
after.documentationfield will be supplied to the MiniLM model, and the vector result will be added to the event in theafter.embedded_documentationfield. The embeddings field will use the Debezium semantic typeio.debezium.data.vector.FloatVector, which contains a series of 32-bit float values. - Ollama
-
Ollama is an open-source solution that permits running, creating, and sharing large language models (LLMs) locally, providing a cost-effective alternative to cloud-based AI services.
To add the embeddings transformation for Ollama to your transformation chain, simply add the following:{ .... "transforms": "ollama", "transforms.ollama.type": "io.debezium.ai.embeddings.FieldToEmbedding", "transforms.ollama.embeddings.ollama.url": "<url-to-ollama>", "transforms.ollama.embeddings.ollama.model.name": "<model-name>", "transforms.ollama.embeddings.field.source": "after.documentation", "transforms.ollama.embeddings.field.embedding": "after.embedded_documentation" }In this example, the
after.documentationfield will be supplied to the Ollama model, and the vector result will be added to the event in theafter.embedded_documentationfield. The embeddings field will use the Debezium semantic typeio.debezium.data.vector.FloatVector, which contains a series of 32-bit float values.
| The Debezium AI Embeddings implementation uses the Java ServiceLoader to load the specific implementation from the classpath. You should ensure that only one Embeddings dependency is on the classpath to guarantee the transformation uses the correct implementation. |
Container images
Conditional inclusion of components in connect-base image
Debezium’s kafka and connect images are all derived from a single common image called connect-base. By default, this base image installs Apicurio, Jolkia, and OpenTelemetry dependencies. This is great for testing purposes, but if you wish to use Debezium’s images as a basis for your own, you may prefer to omit these dependencies if they’re not necessary for your environment.
The connect-base image can now be conditioned to omit any one of these dependencies (DBZ-8709). The OTL_ENABLED, APICURIO_ENABLED, and JOLOKIA_ENABLED environment variables can be set to no to omit those dependencies when building your images, creating a smaller image footprint.
| The |
Debezium Examples
Debezium optimized for GraalVM
Change Data Capture (CDC) is widely used in various contexts, such as microservices communication, legacy system modernization, and cache invalidation. The core idea of this pattern is to detect and track changes in a data source (e.g., a database) and propagate them to other systems in real-time or near real-time. Debezium is a CDC platform that provides a wide range of connectors for most data sources. Beyond capturing changes, it also offers transformation capabilities through an intuitive UI for defining debezium instances.
Check out our recent blog Superfast Debezium which walks you through the latest example of using Debezium with GraalVM!
Summary
In total, 168 issues were resolved in Debezium 3.1. The list of changes can also be found in our release notes.
A big thank you to all the contributors from the community who worked diligently on this release:
Yevhenii Lopatenko, Alvar Viana, Andrea Peruffo, Andrei Leibovski, Anisha Mohanty, Bhagyashree Goyal, Kunal Bhatnagar, Chris Cranford, Christian Seki, Dongwook Chan, Enzo Cappa, Eric Xiao, Fan Yang, Franz Emberger, Gaurav Miglani, Giovanni Panice, Guangnan Shi, Gunnar Morling, Gustavo Lira, Henk van Dyk, Hossein Torabi, Indra Shukla, Jakub Cechacek, James Johnston, Jean Vintache, Jiri Pechanec, Jon Bruno, Jonas Thelemann, Jose Carvajal Hilario, Juanma Barea, Julien Roy, Katerina Galieva, Katsumi Miyajima, Kavya Ramaiah, Krzysztof Grzechnik, Lars M. Johansson, Mario Fiore Vitale, Markus Kull, Martin Vlk, Martin Walsh, Michael Cambria, Minjae Lee, Minjae Lee, Naresh Gandi, Nathan Smit, Ole-Martin Bratteng, Ondrej Babec, P. Aum, Philippe Labat, Rajendra Dangwal, René Kerner, Robert Roldan, Rodolphe Quiedeville, Roman Kudryashov, Sergey Seroshtan, Stanislav Deviatov, Stefan Miklosovic, Thomas Thornton, Timo Schmidt, Vadzim Ramanenka, Victor Castaño, Vojtěch Juránek, Yannick Eisenschmidt, Yuriy Vikulov, Zakariae Ben Allal, Zhongqiang Gong, dario, ismail simsek, kesompochy, and حمود سمبول!
Chris Cranford
Chris is a software engineer at IBM and formerly Red Hat where he works on Debezium and deepens his expertise in all things Oracle and Change Data Capture on a daily basis. He previously worked on Hibernate, the leading open-source JPA persistence framework, and continues to contribute to Quarkus. Chris is based in North Carolina, United States.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.