
One question that we encountered recently is how to effectively integrate change data capture (CDC) with AI workloads — particularly for scenarios in which critical organizational knowledge is not publicly available. To help you to take advantage of your internal data, Debezium 3.1 introduces AI-focused features such as the Embeddings SMT and the Milvus sink, which you can combine to supply inputs to an LLM. You can read more about these enhancements in the Debezium 3.1 release notes.
Introduction
In this post, we’ll show how Debezium, Milvus, and Ollama can work together to form a Retrieval-Augmented Generation (RAG) pipeline. By capturing changes from a relational database, enriching them with vector embeddings, and enabling similarity search across these vectors, you can build AI-driven applications that are powered by up-to-date, domain-specific knowledge.
Let’s look at an example that illustrates how you can use Debezium to enrich your AI applications with knowledge captured from experts within your organization.
Suppose that our organization introduces a new AI-driven application that is backed by an LLM. To enrich and extend the language model, we want to take advantage of internal organizational knowledge that is stored in text documents in a PostgreSQL database. Whenever users within the organization interact with the AI application, we want to make sure that its responses are informed by the most current local knowledge. Because the local knowledge that is stored in the PostgreSQL database is in constant flux, with documents being added, updated, or withdrawn to comply with regulatory requirements, we need a solution that has the agility to keep up with these changes.
The common solution to address this problem is to implement Retrieval-Augmented Generation (RAG). This post demonstrates how to use Debezium to build a CDC-fed RAG system that uses the following components:
-
A PostgreSQL database for data storage
-
Milvus vector database
-
Debezium Server to feed Milvus from PostgreSQL
-
A local Ollama hosted LLM
-
A Java application that interacts with the LLM and uses RAG to provide prompt context
What is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) is an AI technique that combines information retrieval with generative models to produce more accurate and contextually relevant responses. Instead of relying solely on a model’s internal knowledge, RAG pipelines retrieve relevant documents or data from an external source (like a vector database) and use that information to enrich the model’s responses. In our scenario, Debezium, Milvus, and Ollama work together to form a RAG workflow: data changes are captured and vectorized, stored in Milvus, and then retrieved to augment LLM outputs with up-to-date, domain-specific information.
What is Debezium Server?
Debezium Server is a Debezium implementation that you can use to stream change events from databases to various sinks without the need to deploy a Kafka cluster. It provides a lightweight way to consume CDC events and forward them to destinations from which they can be consumed by other applications. Debezium Server also supports the use of Kafka Connect single message transformations within its processing pipeline.
What is Milvus?
Milvus is a specialized vector database designed for similarity search and AI-heavy workloads. Whether it’s product recommendations, image search, or any other use case that relies on fast vector retrieval, Milvus is built for that. A vector database and fast vector retrieval is the heart of any RAG solution. The vector database stores so called embeddings - vector representations of the data that can be used for tasks like similarity search or clustering. Based on similarities between a prompt and the stored data, the AI application extends the context of the prompt.
Why Milvus as a Sink?
For applications where you need up-to-date vector representations of your data, pushing changes from a transactional database into Milvus makes a lot of sense. By using Milvus, not only can you keep your AI models in sync with operational data, you can also offload similarity search to a system that is built for it.
How Debezium Milvus Sink Works
A typical deployment of Milvus sink uses the following workflow:
-
The Debezium connector captures changes from a source database.
-
If the source database does not contain a field with embeddings, then the FieldToEmbedding SMT is used to enrich change events with vector embeddings.
-
Milvus sink writes the vector data into Milvus.
-
Milvus stores and indexes the vectors for fast similarity search.
Example application
This blogpost is based on the Debezium ai-rag example application. Let’s go step-by-step through the details and internals of the application so you can easily build your own.
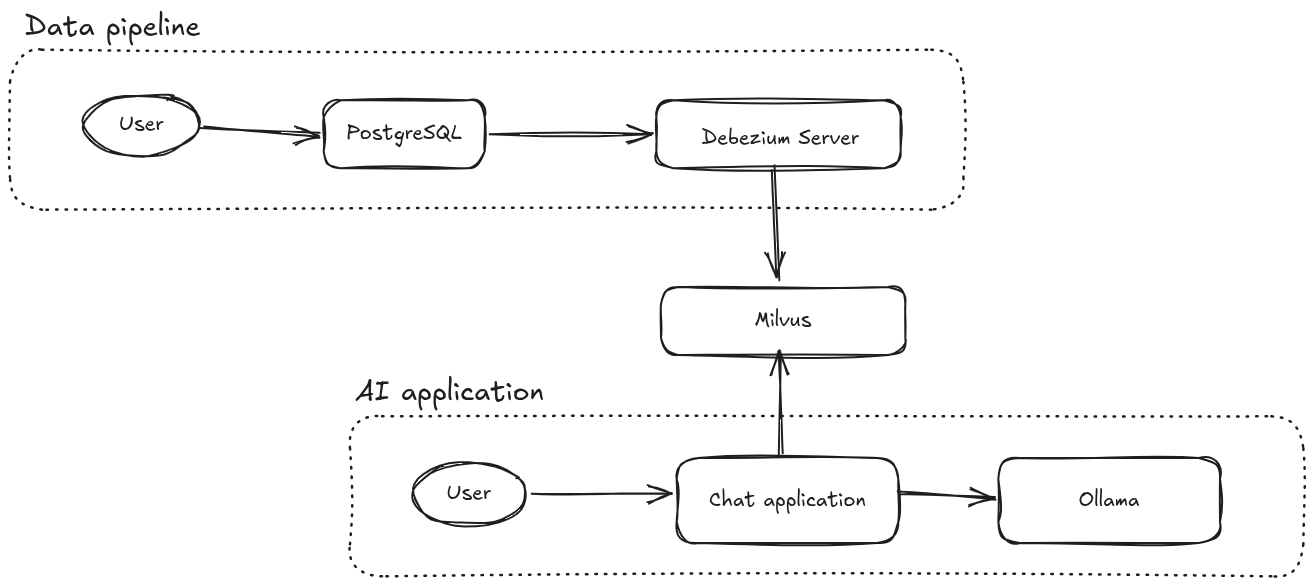
The application architecture consists of the following two flows, which share a common Milvus instance:
-
Data pipeline
-
AI application
The data pipeline ingests data into Milvus, while the AI application queries Milvus to find similarities in the data.
Data pipeline
Our organization sources documents in an arXiv service that provides scholarly articles for download in different formats. The test application downloads a requested article based on its identifier and stores it in a PostgreSQL table.
The PostgreSQL table is created with the following DDL:
CREATE TABLE documents (
id VARCHAR(64) PRIMARY KEY,
metadata JSON,
text TEXT
);
ALTER TABLE documents REPLICA IDENTITY FULL;The replica identity of the table is set to FULL, so Debezium preserves the original state of a row in update and delete messages. Our demo doesn’t require preservation of the original row state, but being able to refer back to the original state is useful for some implementations.
Upon user request, the application downloads documents in text form and stores them in the table. Debezium stores the document identifier in the id field of the event; the textual representation of the article in the text field; and JSON metadata {"id:" "<document id>"} in metadata. The table does not provide a column with embeddings, so Debezium must use its FieldToEmbedding SMT (described later) to calculate them.
In our environment, we run a local LLM that is based on the Ollama LLM framework. For the model, we selected granite3.1-dense:2b, a text-only model that is optimized for RAG. Our model is one of large family of open-source IBM Granite models, but the application is not limited to it and can use an arbitrary model.
Debezium Server provides an interface between the PostgreSQL store and the Milvus sink. Because embeddings are not provided, we can use the Debezium FieldToEmbedding SMT to calculate them and store them a field named vector.
Internally, our application uses the Milvus embedding store for LangChain4j, so we retain the following default Milvus collection structure:
-
id-VarChar -
metadata-JSON -
text-VarChar -
vector-FloatVector
There is a known issue in the module that causes an application failure when the store is empty. To work around the issue, we store a dummy document in the database (and thus in Milvus).
AI Application
The AI application interacts with the LLM and extends the prompt based on similarities in the embeddings in the prompt and in the data that it loads from the Milvus store.
The demo application is command-line driven, and is written using the Quarkus framework. For AI features, the application uses the Quarkus LangChain4j extension, specifically the open-source Ollama LLM and the Milvus Store for RAG.
The AI service is registered via the Debezium Chat class.
package io.debezium.examples.airag;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
@RegisterAiService(retrievalAugmentor = MilvusRetrievalAugmentor.class)
public interface Chat {
@SystemMessage("You are an expert that provides short summaries.")
String chat(@UserMessage String message);
}You use application.properties to configure the module.
quarkus.langchain4j.ollama.base-url=http://localhost:11434 quarkus.langchain4j.ollama.chat-model.model-id=granite3.1-dense:2b quarkus.langchain4j.ollama.embedding-model.model-id=granite3.1-dense:2b quarkus.langchain4j.ollama.timeout=120s
RAG is enabled using the retrievalAugmentor parameter on the @RegisterAiService annotation and is implemented in the MilvusRetrievalAugmentor bean.
@ApplicationScoped
public class MilvusRetrievalAugmentor implements Supplier<RetrievalAugmentor> {
private final RetrievalAugmentor augmentor;
MilvusRetrievalAugmentor(MilvusEmbeddingStore store, EmbeddingModel model) {
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(model)
.embeddingStore(store)
.maxResults(3)
.build();
augmentor = new RetrievalAugmentorDecorator(DefaultRetrievalAugmentor
.builder()
.contentRetriever(contentRetriever)
.build());
}
@Override
public RetrievalAugmentor get() {
return augmentor;
}
private class RetrievalAugmentorDecorator implements RetrievalAugmentor {
private final RetrievalAugmentor delegate;
public RetrievalAugmentorDecorator(RetrievalAugmentor delegate) {
this.delegate = delegate;
}
@Override
public AugmentationResult augment(AugmentationRequest augmentationRequest) {
Log.infof("Requested augmentation of %s", augmentationRequest.chatMessage());
final var result = delegate.augment(augmentationRequest);
Log.infof("Result of augmentation is %s", result.contents());
return result;
}
}
}The EmbeddingStoreContentRetriever class queries the Milvus vector database and enhances the prompt context with the three most similar documents. The class also provides the RetrievalAugmentorDecorator, which logs details of the augmentation operation.
You also use application.properties to configure the Milvus embedding store, as shown in the following example:
quarkus.langchain4j.milvus.host=localhost quarkus.langchain4j.milvus.port=19530 quarkus.langchain4j.milvus.create-collection=false quarkus.langchain4j.milvus.collection-name=demo_ai_documents # The following two settings are not supported by the current version of Quarkus Langchain4j extension # Also field with text cannot be overriden and is default text quarkus.langchain4j.milvus.primary-field=id quarkus.langchain4j.milvus.vector-field=vector
Demo
The demo is composed of the following two components:
-
A Docker Compose configuration file that starts all of the services.
-
A Java CLI application in the client directory that emulates both the data pipeline and the AI application.
Starting the deployment
In Terminal 1, enter the following command and wait for the containers to start.
$ docker-compose up --build
The preceding command extends the standard Debezium Server image with the debezium-ai-embeddings-ollama module (the AI embeddings modules are not included by default). The command also starts the PostgreSQL (postgres), Milvus (milvus), Debezium Server (debezium-server) and Ollama (ollama) containers.
In Terminal 2, enter the following command to start the Granite LLM model:
$ docker exec -it ollama ollama run granite3.1-dense:2b
We need to make sure that we are testing the application with facts that the model is unaware of. First, we will check the model’s cut-off date (what’s the latest data the model has seen).
>>> What is your cut off date? My knowledge cut off date is April 2024. I can provide information and answer questions based on data up to that point. For more recent events or discoveries, I'm unable to include those details in my responses as they weren't available at the time of my training data. If you have any questions within this timeframe, feel free to ask!
Based on that fact, we selected the paper 2504.05309v1 (IterQR: An Iterative Framework for LLM-based Query Rewrite in e-Commercial Search System) to represent knowledge that is new to the application. This paper was published in February 2025, after cut-off date, and it contains the very specific keyword, IterQR. We will test the model by asking about the framework.
>>> Describe IterQR framework in 20 words. Iterative Quantized Ridge Regression (IterQR), a scalable method for large-scale regression, iteratively refines coefficients via quantization and ridge regression techniques to minimize computational complexity while maintaining accuracy.
The answer is completely unrelated to the framework and exhibits traits of hallucination. The model does not know about the fact so it invents its own without any connection to reality. When we ask the model this question multiple times it provides different and unrelated responses.
Data pipeline
We’ll run the remaining portions of the demo in Terminal 3, using a Java application. The application is built with Maven, so we begin by running the following commands:
$ cd client $ ./mvnw clean install
To start the application, run java -jar target/quarkus-app/quarkus-run.jar.
Now, we initialize the Milvus store with the collection and a dummy record (as per the known issue mentioned earlier). The record is not inserted directly. Instead, a new row is written into the PostgreSQL source table, and that row is then ingested into Milvus via Debezium. Enter the following command:
$ java -jar target/quarkus-app/quarkus-run.jar init
The command returns the following output (portions of the log are removed for improved readability and clarity):
... 2025-05-20 06:05:10,712 INFO [io.deb.exa.air.MilvusStore] (main) Created collection 'demo_ai_documents' with schema: CreateCollectionReq.CollectionSchema(fieldSchemaList=[CreateCollectionReq.FieldSchema(name=id, description=, dataType=VarChar, maxLength=64, dimension=null, isPrimaryKey=true, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=false, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null), CreateCollectionReq.FieldSchema(name=metadata, description=, dataType=JSON, maxLength=65535, dimension=null, isPrimaryKey=false, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=true, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null), CreateCollectionReq.FieldSchema(name=text, description=, dataType=VarChar, maxLength=65535, dimension=null, isPrimaryKey=false, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=false, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null), CreateCollectionReq.FieldSchema(name=vector, description=, dataType=FloatVector, maxLength=65535, dimension=2048, isPrimaryKey=false, isPartitionKey=false, isClusteringKey=false, autoID=false, elementType=null, maxCapacity=null, isNullable=false, defaultValue=null, enableAnalyzer=null, analyzerParams=null, enableMatch=null)], enableDynamicField=false, functionList=[]) ...
Next, enter the following command to verify that the Milvus store contains only single (dummy) document.
$ java -jar target/quarkus-app/quarkus-run.jar list-milvus
...
2025-05-20 06:08:08,213 INFO [io.deb.exa.air.MilvusStore] (main) Milvus list results size: 1
2025-05-20 06:08:08,217 INFO [io.deb.exa.air.MilvusStore] (main) Document: {metadata={"id":"permanent"}, vector=[...], text=permanent, id=permanent}
... Application pipeline
The data pipeline is established but there is no domain specific knowledge available yet. We can enter the following command to check whether the model is still hallucinating:
$ java -jar target/quarkus-app/quarkus-run.jar query-chat Describe IterQR framework in 20 words
The model responds with the following output:
2025-05-20 06:15:13,140 INFO [io.deb.exa.air.RagCommand] (main) Sending query: Describe IterQR framework in 20 words
2025-05-20 06:15:13,465 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Requested augmentation of UserMessage { name = null contents = [TextContent { text = "Describe IterQR framework in 20 words" }] }
2025-05-20 06:15:21,521 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Result of augmentation is [DefaultContent { textSegment = TextSegment { text = "permanent" metadata = {id=permanent} }, metadata = {SCORE=0.5046951323747635, EMBEDDING_ID=permanent} }]
2025-05-20 06:15:30,117 INFO [io.deb.exa.air.RagCommand] (main) Chat reply: Iterative QR factorization, a permanent matrix method, breaks down data into orthogonal matrices for efficient computations. The model’s reply is clearly unrelated to the real framework. The log of RetrievalAugmentorDecorator shows the impact of augmentation on the message sent to the chat. Document permanent was added to the message. It is the dummy record from the store and as such it will be always added if it is among the top three matching documents.
The data pipeline now processes a new domain fact (arXiv document). Document is downloaded from the server in textual form and inserted into a PostgreSQL table. Debezium Server should propagate the document into the Milvus store.
$ java -jar target/quarkus-app/quarkus-run.jar insert-document 2504.05309v1
$ java -jar target/quarkus-app/quarkus-run.jar list-milvus
...
2025-05-20 06:25:00,203 INFO [io.deb.exa.air.MilvusStore] (main) Milvus list results size: 2
2025-05-20 06:25:00,206 INFO [io.deb.exa.air.MilvusStore] (main) Document: {metadata={"id":"2504.05309v1"}, vector=[...], id=2504.05309v1, text=# Title
IterQR: An Iterative Framework for LLM-based Query Rewrite in
e-Commercial Search System
# Authors
Shangyu Chen, Xinyu Jia, Yingfei Zhang, Shuai Zhang, Xiang Li, Wei Lin
# Abstract
The essence of modern e-Commercial search system lies in matching user's
intent and available candidates depending on user's query, providing
personalized and precise service. However, user's query may be incorrect due to
ambiguous input and typo, leading to inaccurate search. These cases may be
released by query rewr}
2025-05-20 06:25:00,240 INFO [io.deb.exa.air.MilvusStore] (main) Document: {metadata={"id":"permanent"}, vector=[...], id=permanent, text=permanent}... The Milvus store now contains the document about the IterQR framework. Note that, by default, we truncate the document to 512 characters so that the demo can be used on computers that do not have a GPU. This behavior is controlled by the DocumentDatabase class and configuration property debezium.rag.demo.document.truncate.
Now, if you repeat the query, the answer should be relevant to the real description.
$ java -jar target/quarkus-app/quarkus-run.jar query-chat Describe IterQR framework in 20 words
2025-05-20 06:30:36,703 INFO [io.deb.exa.air.RagCommand] (main) Sending query: Describe IterQR framework in 20 words
2025-05-20 06:30:37,014 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Requested augmentation of UserMessage { name = null contents = [TextContent { text = "Describe IterQR framework in 20 words" }] }
2025-05-20 06:30:44,775 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Result of augmentation is [DefaultContent { textSegment = TextSegment { text = "# Title
IterQR: An Iterative Framework for LLM-based Query Rewrite in
e-Commercial Search System
# Authors
Shangyu Chen, Xinyu Jia, Yingfei Zhang, Shuai Zhang, Xiang Li, Wei Lin
# Abstract
The essence of modern e-Commercial search system lies in matching user's
intent and available candidates depending on user's query, providing
personalized and precise service. However, user's query may be incorrect due to
ambiguous input and typo, leading to inaccurate search. These cases may be
released by query rewr" metadata = {id=2504.05309v1} }, metadata = {SCORE=0.5339204333722591, EMBEDDING_ID=2504.05309v1} }, DefaultContent { textSegment = TextSegment { text = "permanent" metadata = {id=permanent} }, metadata = {SCORE=0.5046951323747635, EMBEDDING_ID=permanent} }]
2025-05-20 06:31:08,067 INFO [io.deb.exa.air.RagCommand] (main) Chat reply: IterQR is an iterative framework for enhancing e-Commercial search system precision, addressing user query errors via continuous iterations of candidate selection based on language model outputs. The preceding log shows the following changes:
-
The response is augmented with the arXiv document.
-
The answer corresponds to the new fact.
But if you query the model in Terminal 2 again, you receive the hallucinated answer, because it does not have access to augmenting facts.
>>> Describe IterQR framework in 20 words. Iterative Quantized Ridge Regression (IterQR) is an efficient, iterative algorithm for large-scale linear regression that leverages quantization and ridge regression to reduce computational complexity while maintaining accuracy, offering a scalable approach for managing extensive datasets.
As a final step, let’s test whether the knowledge can be forgotten. The data pipeline deletes the document from the PostgreSQL database.
$ java -jar target/quarkus-app/quarkus-run.jar delete-document 2504.05309v1
$ java -jar target/quarkus-app/quarkus-run.jar list-milvus
...
2025-05-20 06:40:02,797 INFO [io.deb.exa.air.MilvusStore] (main) Milvus list results size: 1
...
$ java -jar target/quarkus-app/quarkus-run.jar query-chat Describe IterQR framework in 20 words
...
2025-05-20 06:40:44,373 INFO [io.deb.exa.air.RagCommand] (main) Sending query: Describe IterQR framework in 20 words
2025-05-20 06:40:44,665 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Requested augmentation of UserMessage { name = null contents = [TextContent { text = "Describe IterQR framework in 20 words" }] }
2025-05-20 06:40:51,957 INFO [io.deb.exa.air.MilvusRetrievalAugmentor$RetrievalAugmentorDecorator] (main) Result of augmentation is [DefaultContent { textSegment = TextSegment { text = "permanent" metadata = {id=permanent} }, metadata = {SCORE=0.5046951323747635, EMBEDDING_ID=permanent} }]
2025-05-20 06:41:01,424 INFO [io.deb.exa.air.RagCommand] (main) Chat reply: Iterative QR (iterQR) is an algorithm for approximate singular value decomposition, efficiently computing sparse solutions to linear systems through iterative updates of the matrix representation.
... After we remove the document, we observe the following results:
-
Debezium Server captures the delete operation and removes the document from the Milvus store.
-
The chat query is not augmented.
-
The reply is again hallucinated.
Stopping the demo
To end the demo deployment, enter the following command:
$ docker-compose down
The preceding command terminates the containers in all terminals.
Conclusion
Debezium enables organizations to plug their existing databases directly into modern Retrieval-Augmented Generation (RAG) pipelines — with zero modifications to source applications. That means all the innovation, experimentation, and AI development can happen in parallel, without interfering with established processes, compliance controls, or legacy architecture.
This blogpost describes how Debezium 3.1 can be integrated into AI workflows, particularly those using Retrieval-Augmented Generation (RAG). Debezium captures real-time changes from a database and feeds them into vector databases. These updates are essential for keeping AI systems current with fresh, domain-specific data. The example setup involves PostgreSQL, Debezium Server, Milvus, and Granite LLM (with embeddings). This architecture enables you to deploy intelligent applications that respond with accurate, up-to-date information.
Turn your company’s data into a competitive advantage — without rewriting a single line of production code.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.