
The modern data landscape bears little resemblance to the centralized databases and simple ETL processes of the past. Today’s organizations operate in environments characterized by diverse data sources, real-time streaming, microservices architectures, and multi-cloud deployments. What began as straightforward data flows from operational systems to reporting databases has evolved into complex networks of interconnected pipelines, transformations, and dependencies. The shift from ETL to ELT patterns, the adoption of data lakes, and the proliferation of streaming platforms like Apache Kafka have created unprecedented flexibility in data processing. However, this flexibility comes at a cost: understanding how data moves, transforms, and evolves through these systems has become increasingly challenging.
Understanding data lineage
Data lineage is the process of tracking the flow and transformations of data from its origin to its final destination. It essentially maps the "life cycle" of data, showing where it comes from, how it’s changed, and where it ends up within a data pipeline. This includes documenting all transformations, joins, splits, and other manipulations the data undergoes during its journey.
At its core, data lineage answers critical questions: Where did this data originate? What transformations has it undergone? Which downstream systems depend on it? When issues arise, where should teams focus their investigation?
Why data lineage matters
- Regulatory compliance and governance
-
Modern regulations like GDPR, SOX, and industry-specific compliance frameworks require organizations to demonstrate comprehensive understanding of how data is processed. Data lineage provides the audit trail necessary for regulatory compliance, enabling organizations to show exactly how sensitive information flows through their systems.
- Data quality and trust
-
When business users encounter unexpected values or anomalies in reports, data lineage enables rapid quality assessment. Teams can quickly trace data back through processing chains to identify where quality issues originated, building confidence in data-driven decisions.
- Operational efficiency
-
In complex data ecosystems, troubleshooting traditionally involves time-consuming manual investigation. Data lineage transforms this reactive process into systematic operations, enabling teams to quickly identify affected systems, assess impact scope, and implement targeted fixes.
OpenLineage
OpenLineage is an open standard for data lineage that provides a unified way to collect and track lineage metadata across multiple data systems. The specification defines a common model for describing datasets, jobs, and runs, making it easier to build comprehensive lineage graphs across heterogeneous data infrastructures.
At the core of OpenLineage is a standard API for capturing lineage events. Pipeline components - like schedulers, warehouses, analysis tools, and SQL engines - can use this API to send data about runs, jobs, and datasets to a compatible OpenLineage backend for further study.

OpenLineage object model
OpenLineage defines a generic model of run, job, and dataset entities identified using consistent naming strategies. The core lineage model is extensible by defining specific facets to enrich those entities.
Core Entities
- Dataset
-
A dataset is a unit of data, such as a table in a database or an object in a bucket for cloud storage. A dataset changes when a job writing to it gets completed.
- Job
-
A job is a data pipeline process that creates or consumes datasets. Jobs can evolve, and documenting these changes is crucial to understanding your pipeline’s mechanism.
- Run
-
A run is an instance of a job that has been executed. It contains information about the job, such as the start and completion (or failure) time.
How Debezium integrates with OpenLineage
To integrate with OpenLineage, Debezium uses the OpenLineage Java SDK.
OpenLineage job mapping
The Debezium connector is mapped to an OpenLineage Job, which includes the following elements:
- Name
-
Inherited from the Debezium
topic.prefix.<taskId>. - Namespace
-
Inherited from
openlineage.integration.job.namespace, if specified; otherwise defaults totopic.prefix - Debezium version information
-
The connector version
- Complete connector configuration
-
The whole configuration used by the connector
- Job metadata
-
A job description, a set of configurable tags, and owners.
Dataset Mapping for source connectors
The following dataset mappings are possible:
- Input Datasets
-
Automatically created for the database tables that Debezium is configured to capture changes from. The following characteristics affect the mapping:
-
Each monitored table becomes an input dataset.
-
Schema information for a table is captured, including column names and types.
-
Dataset schemas are updated dynamically after a DDL change.
-
- Output Datasets
-
Represent the Kafka topics that result after you apply the OpenLineage transform. Mappings are created according to the following principles:
-
Each Kafka topic that the connector produces becomes an output dataset.
-
The output dataset captures the complete CDC event structure, including metadata fields.
-
The name of the dataset is based on the connector’s topic prefix configuration.
-
| This mapping is valid for source connectors. We will add support also for sinks in next releases. |
Job status
Every time the Debezium connector start, after a graceful shutdown or a failure, a new run event is associated to the job. So the job status will change as following:
- START
-
Emitted during the connector initialization.
- RUNNING
-
Emitted periodically during normal streaming operations and during processing individual tables. These periodic events ensure continuous lineage tracking for long-running streaming CDC operations.
- COMPLETE
-
Emitted when the connector shut down gracefully.
- FAIL
-
Emitted when the connector encountered an error.
So, what can we actually do with these lineage metadata?
Well, one of the most powerful things is to visualize your lineage graph and how the different pieces of you data pipelines connects together. OpenLineage can be configured to send lineage metadata to different consumers. One such consumer is Marquez.
It is an open source metadata service for the collection, aggregation, and visualization of a data ecosystem’s metadata. It maintains the provenance of how datasets are consumed and produced, provides global visibility into job runtime and frequency of dataset access, centralization of dataset lifecycle management, and much more.
The following pictures shows the lineage graph generated by the Debezium Postgres connector with our example database, the inventory.
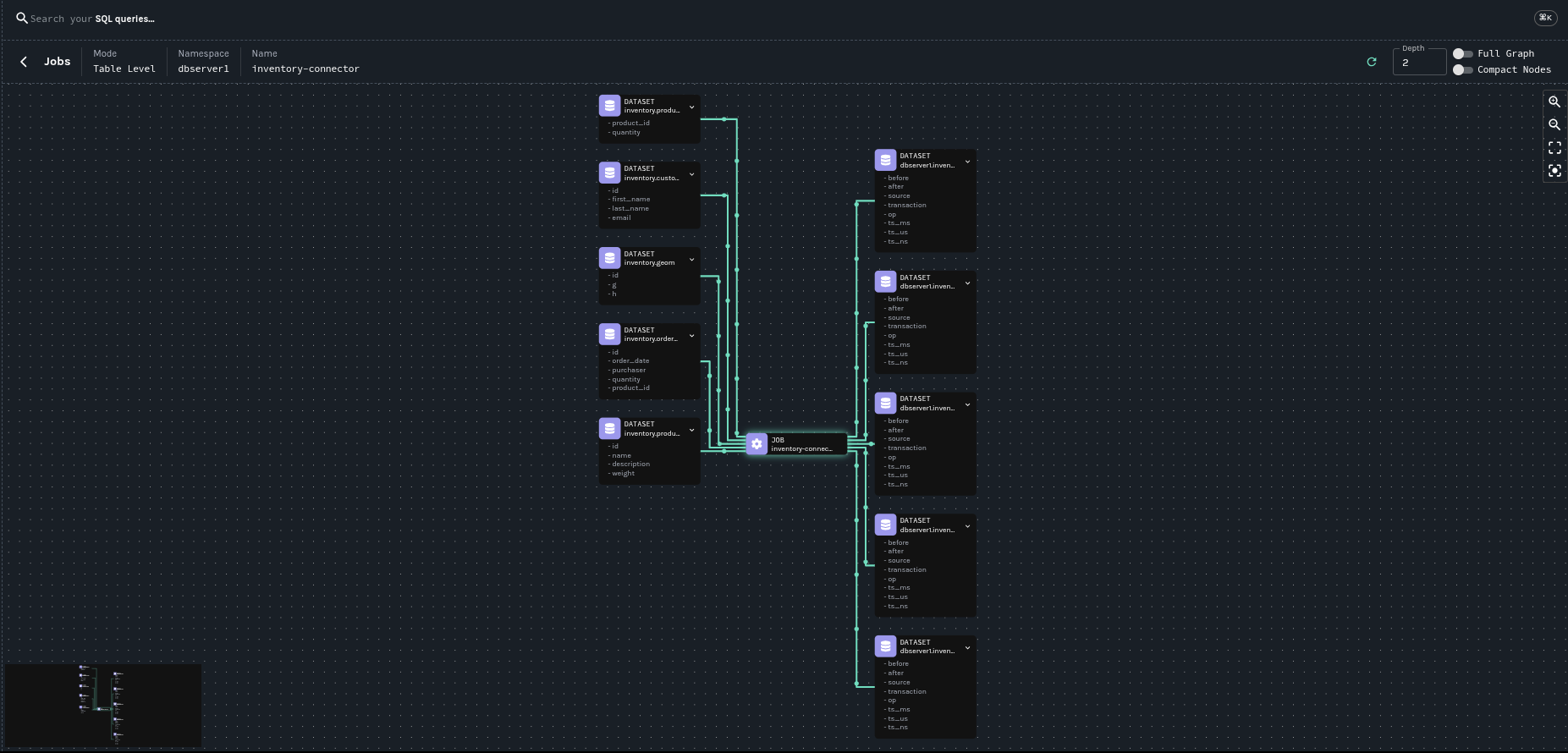
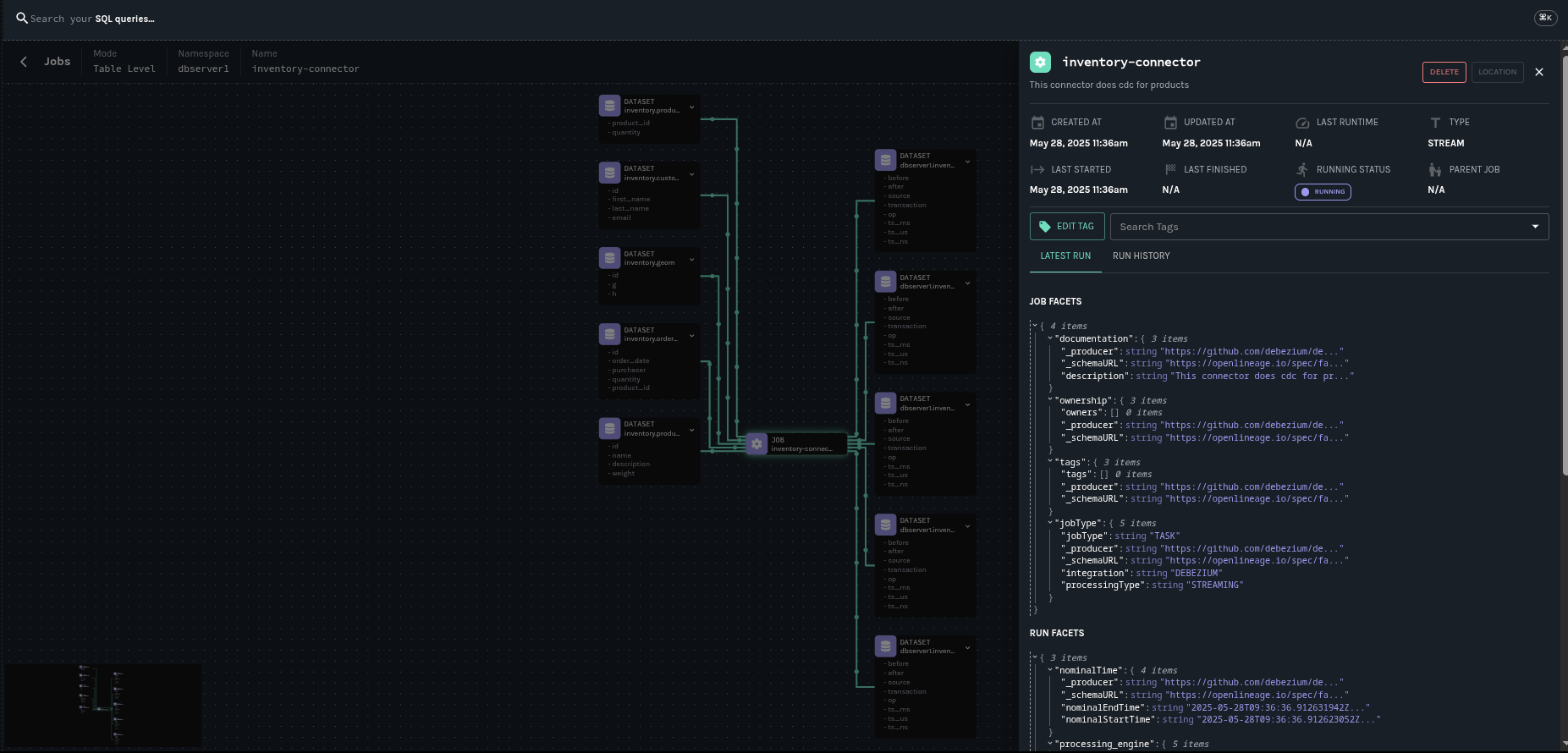
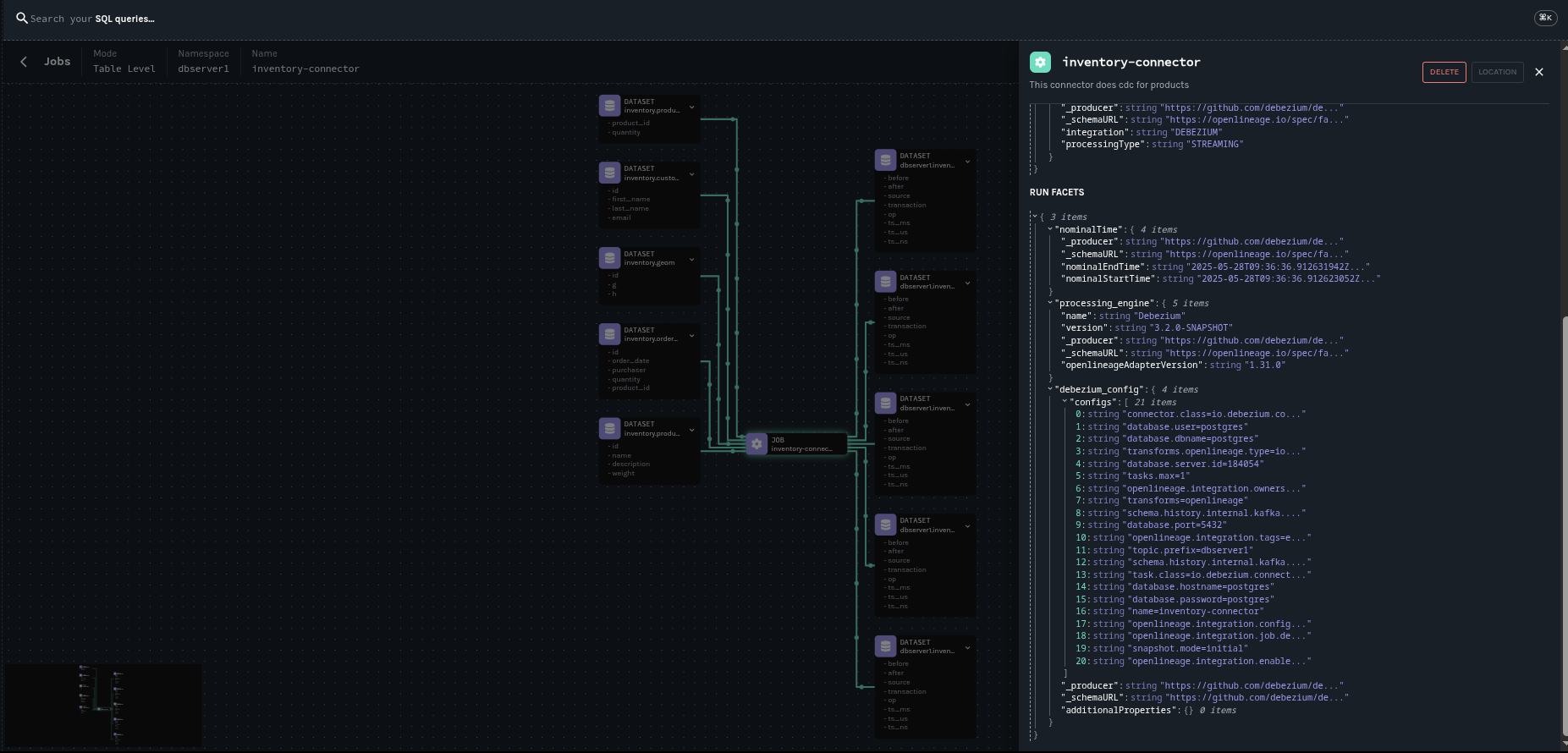

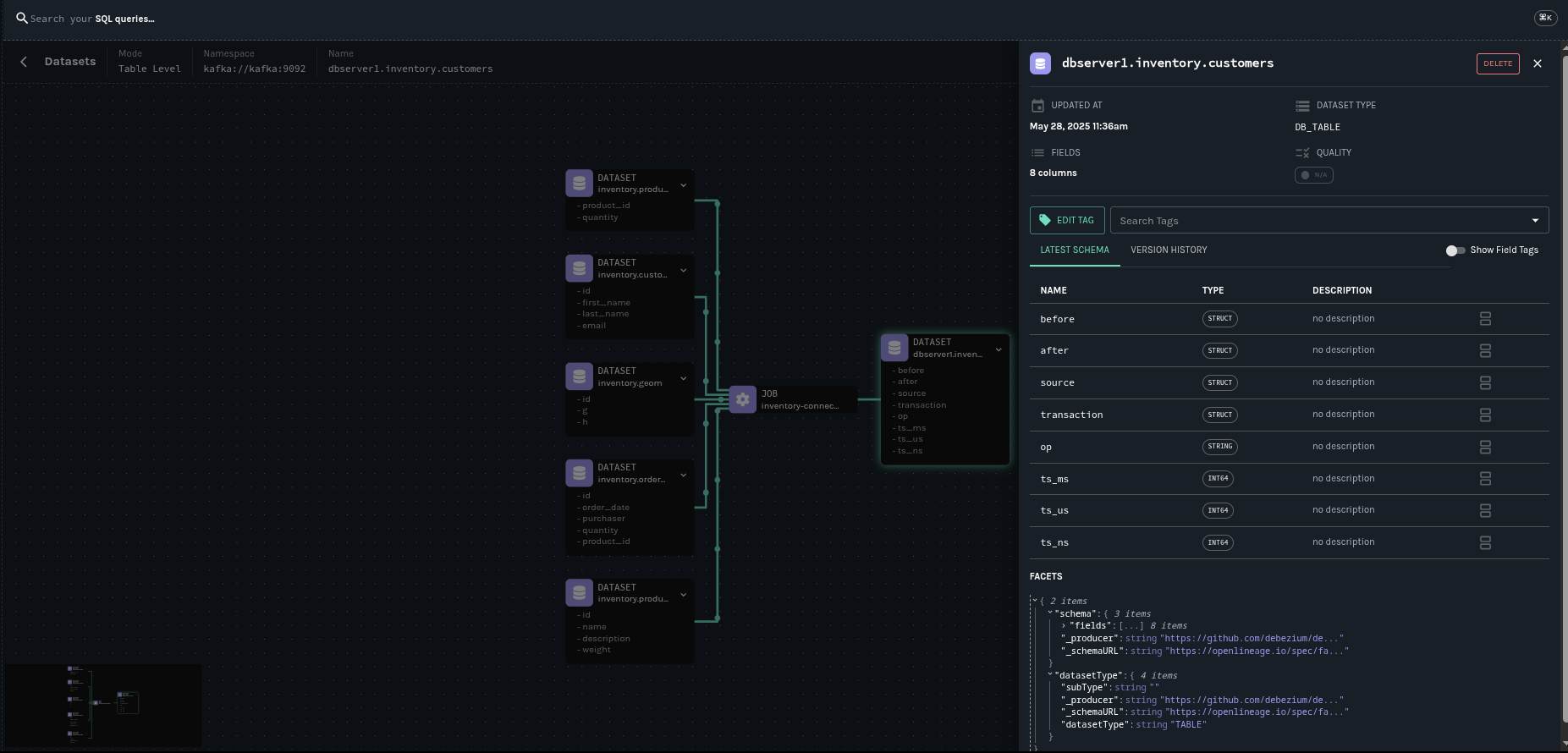
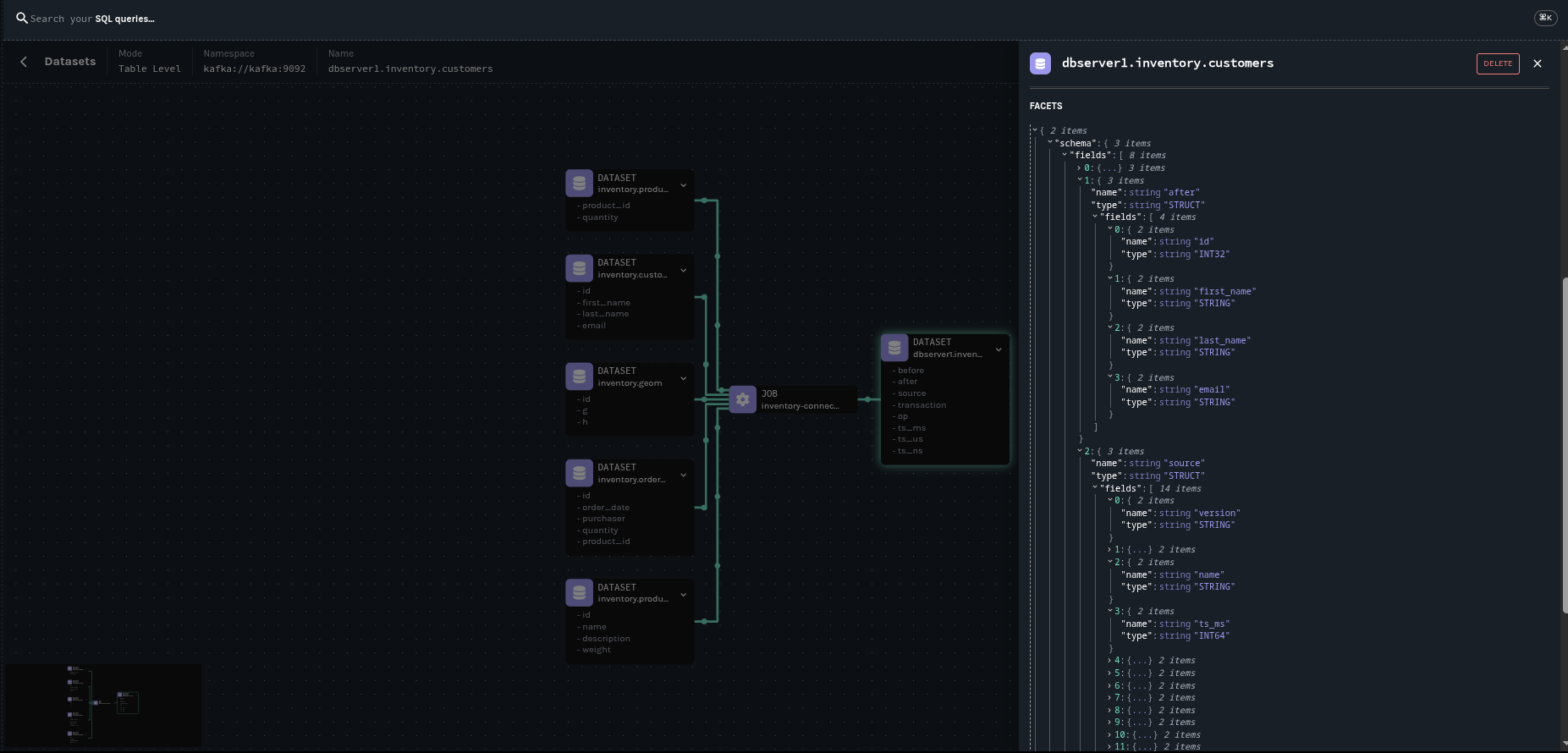
This concludes our introduction article on OpenLinage integration. Another will follow with a complete showcase. Meanwhile, you can refer to our documentation to start playing with it.
We also suggest to have a read to Exploring Lineage History via the Marquez API
Fiore Mario Vitale
Active in the open-source community with contributions to various projects, Mario is deeply involved in developing Debezium, the distributed platform for change data capture. During his career he developed extensive experience in event-driven architectures heavily influenced by data. Throughout his career, Mario has predominantly focused on data-intensive software and product development, which has heightened his sensitivity to developer experience and data-driven applications. Beyond his professional pursuits, Mario finds his sweet spot where tech and his personal interests come together. He loves taking photos, especially when he manages to freeze a beautiful moment. He's also passionate about motorsports and racing. When he's not coding, you can often find him exploring the great outdoors on his mountain bike, fueling his passion for adventure.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.