
Remember when debugging streaming data pipelines felt like playing detective in a crime scene where the evidence kept moving? Well, grab your magnifying glass because we’re about to turn you into Sherlock Holmes of the streaming world. After our introduction to OpenLineage integration with Debezium, it’s time to roll up our sleeves and get our hands dirty with some real detective work. We’ll build a complete order processing pipeline that captures database changes with Debezium, processes them through Apache Flink, and tracks every breadcrumb of data lineage using OpenLineage and Marquez – because losing track of your data is like losing your keys, except infinitely more embarrassing in production.
Case definition
In this showcase, we demonstrate how to leverage lineage metadata to troubleshoot issues in data pipelines. Our e-commerce order processing pipeline, despite its simplicity, effectively illustrates the benefits of lineage metadata for operational monitoring and debugging. We will simulate a configuration change in the Debezium connectors that causes the order processing job to skip records. Using the lineage graph, we’ll navigate through the pipeline components to identify the root cause of the problem and understand how metadata tracking enables faster issue resolution.
Components
The pipeline consists of two interconnected components:
Debezium connector: captures real-time changes from three PostgreSQL tables containing our core business entities - orders, customers, and products. Each table represents a critical piece of our order fulfillment process.
Apache Flink job: order processing job that enriches the captured data streams, performing joins and transformations to create comprehensive shipping orders with calculated metrics like total weight and shipping status.
This two components shares a common layer for tracking the lineage metadata through OpenLineage.
Debezium connector
Debezium connectors will stream data changes from the following order processing domain tables:
-
inventory.orders- Contains order transactions with essential fields like order ID, date, purchaser reference, quantity, and product reference
ID=10100, Date=2025-07-18, Purchaser=1002, Quantity=10, Product=103
-
inventory.customers- Stores customer profiles including ID, name, and email contact information
ID=1002, Name="John Doe", Email="john@example.com"
-
inventory.products- Maintains product catalog data with ID, name, description, and weight specifications
ID=103, Name="Widget", Description="Blue Widget", Weight=1.5
Each stream carries Debezium’s standard CDC format, providing rich metadata about the nature of changes including operation type, timestamps, and source information.
Order processing job
The core of our demonstration lies in the OrderShippingProcessor job, which enriches the orders in real-time.
The job filters CDC events to process only insert, update, and read operations, discarding delete events that aren’t relevant for shipping order generation. It then extracts the relevant business data from Debezium’s CDC envelope format. Orders are then time-windowed and joined with customer and product streams, creating a complete shipping order that includes total weight calculations (product weight × quantity), shipping status assignment, and processing timestamps.
The enriched shipping order will be:
{
"orderId": 10100,
"orderDate": "2025-07-18",
"quantity": 10,
"productName": "Widget",
"productDescription": "Blue Widget",
"productWeight": 1.5,
"totalWeight": 15.0,
"customerName": "John Doe",
"customerEmail": "john@example.com",
"shippingStatus": "READY_TO_SHIP",
"processedAt": 1721559123456
}Prerequisites and setup
Before starting with the example, ensure your environment has the necessary tools and sufficient resources.
System Requirements
-
Docker and Docker Compose for containerized services
-
Maven for building the Flink job
-
kcctl (Kafka Connect CLI) for connector management
-
jq for JSON processing and output formatting
Starting Marquez server
OpenLineage events can be sent to different destinations, for this example we will use Marquez as metadata storage and visualization. First, clone the Marquez repository:
git clone https://github.com/MarquezProject/marquez && cd marquezStart the server:
./docker/up.shThis launches all Marquez’s required components.
Repository Setup
Clone the example repository and navigate to the appropriate directory:
git clone https://github.com/debezium/debezium-examples
cd debezium-examples/openlineage/debezium-flinkStep-by-step deployment
Building the Flink Job
First of all we need to package our order processing job. Build it executing the following command:
mvn clean package -f flink-job/pom.xmlLaunching the demo components
Start all required services:
docker compose -f docker-compose-flink.yaml upThis command orchestrates the startup of:
-
Kafka: Message broker where CDC event are sent
-
PostgreSQL: Source database pre-populated with sample inventory data
-
Debezium Connector: CDC connector with OpenLineage integration
-
Flink Cluster: JobManager and TaskManager for stream processing
Network Configuration
Connect the Marquez API to the demo network for proper communication:
docker network connect debezium-flink_default marquez-apiTopic Preparation
Verify Kafka topics are properly created:
docker compose -f docker-compose-flink.yaml exec kafka /kafka/bin/kafka-topics.sh --list --bootstrap-server kafka:9092Create the output topic for processed shipping orders:
docker compose -f docker-compose-flink.yaml exec kafka /kafka/bin/kafka-topics.sh --create --bootstrap-server kafka:9092 --replication-factor 1 --partitions 1 --topic shipping-ordersConfiguring Debezium with OpenLineage
Apply the PostgreSQL connector configuration that includes OpenLineage integration:
kcctl apply -f postgres-connector-openlineage.jsonThis configuration enables CDC capture from the PostgreSQL database while automatically sending lineage metadata to Marquez.
For details on how to configure Debezium with OpenLineage please see our documentation
Deploying the Flink Job
Submit the order processing job to the Flink cluster:
docker compose -f docker-compose-flink.yaml exec jobmanager bin/flink run -c io.debezium.examples.openlineage.OrderShippingProcessor flink-order-processor-1.0-SNAPSHOT.jarThe job begins consuming CDC events and producing enriched shipping orders immediately.
Verifying the Pipeline
Confirm that enriched orders are being generated and published:
docker compose -f docker-compose-flink.yaml exec kafka ./bin/kafka-console-consumer.sh --bootstrap-server=kafka:9092 --topic shipping-orders --from-beginning --max-messages 1 | jqYou should see output similar to:
{
"orderId": 10001,
"orderDate": "16816",
"quantity": 1,
"productName": "car battery",
"productDescription": "12V car battery",
"productWeight": 8.1,
"totalWeight": 8.1,
"customerName": "Sally Thomas",
"customerEmail": "sally.thomas@acme.com",
"shippingStatus": "READY_TO_SHIP",
"processedAt": 1752139246887
}Monitoring and Visualization
Flink Web UI
Access the Flink Web UI at http://localhost:8081 to monitor job execution, view metrics, and investigate any processing issues.
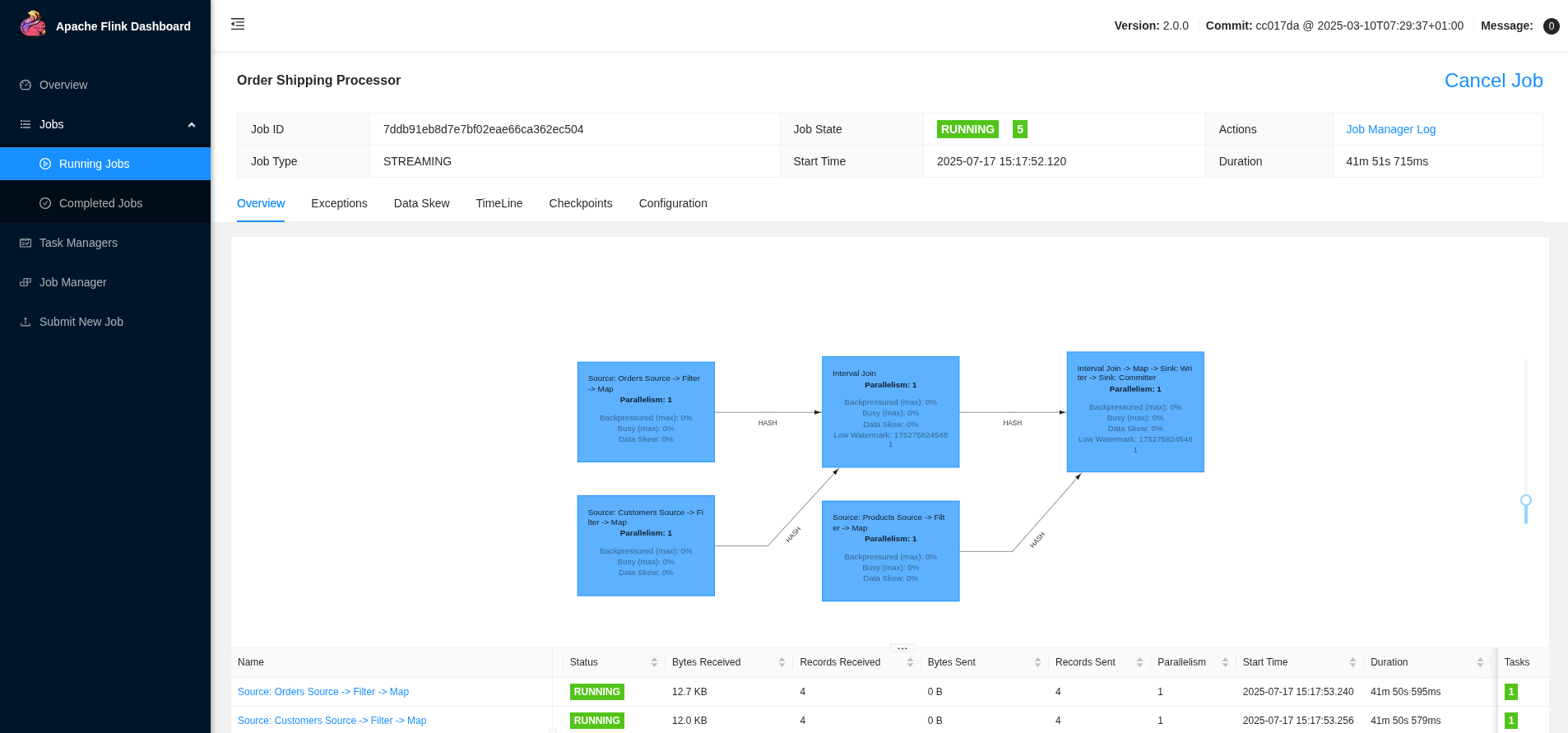
The dashboard provides insights into:
-
Job execution status and runtime metrics
-
Throughput and latency measurements
-
Resource utilization across TaskManagers
-
Checkpoint and savepoint information
Marquez lineage visualization
The Marquez UI at http://localhost:3000 offers comprehensive lineage visualization and exploration capabilities.
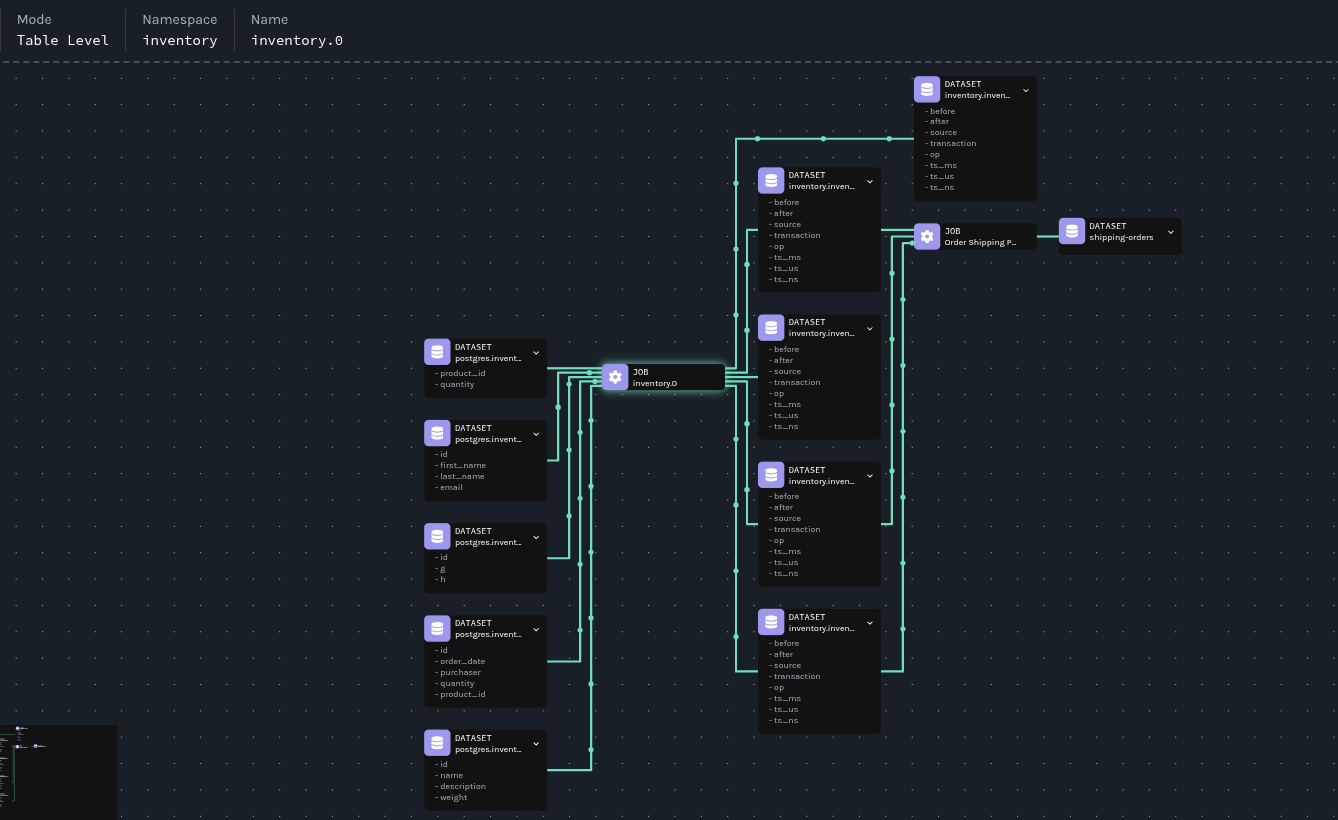
The lineage graph reveals:
-
Data Sources: PostgreSQL tables as the origin of all data
-
Transformations: Flink jobs as processing nodes with input/output relationships
-
Data Flow: Arrows indicating data movement and transformation paths
-
Schemas: Detailed schema information for each dataset version
Simulating a disruptive change
We are now going to simulate a change in Debezium that will cause the output dataset schema to change. We will go through lineage metadata to identify and troubleshoot issues caused by the schema change.
Applying the change
We’ll modify the Debezium connector to use the ExtractNewRecordState transformation, which changes the message format from Debezium’s standard CDC envelope to a flattened structure:
kcctl apply -f postgres-connector-openlineage-update.jsonInsert a new order to emit the data change event with the new format:
docker compose -f docker-compose-flink.yaml exec postgres psql -Upostgres -c "insert into inventory.orders values(10100, '2025-07-18', 1002, 10, 103);"Observing the impact
Monitor the shipping orders topic to see the effect:
docker compose -f docker-compose-flink.yaml exec kafka ./bin/kafka-console-consumer.sh --bootstrap-server=kafka:9092 --topic shipping-orders --from-beginning | jqNotice that the new order (10100) doesn’t appear in the output, indicating that our oder processing job haven’t processed the new order.
Investigating with lineage metadata support
The lineage graph makes it easy for anyone to see component relationships and dependencies, regardless of their pipeline knowledge. The order processing job depends on three datasets (inventory.inventory.orders, inventory.inventory.customers, and inventory.inventory.products) that come from the inventory.0 job, so that’s where we should begin our investigation.
Analyzing job runs
A first step is to list recent job runs to identify changes:
curl "http://localhost:5000/api/v1/namespaces/inventory/jobs/inventory.0/runs" | jq '.runs | map({"id": .id, "state": .state})'The output reveals multiple runs, indicating job restarts:
[
{
"id": "0197f3a3-6f97-787a-bd19-43313c9fef0a",
"state": "RUNNING"
},
{
"id": "0197f3a3-0a6a-7145-8c8b-e6040636c504",
"state": "COMPLETED"
}
]The question now is: what caused the job to restart?
Comparing job versions
Let’s extract and store run IDs for comparison:
CURRENT_RUN_ID=$(curl "http://localhost:5000/api/v1/namespaces/inventory/jobs/inventory.0/runs" | jq -r '.runs[0].id')
PREVIOUS_RUN_ID=$(curl "http://localhost:5000/api/v1/namespaces/inventory/jobs/inventory.0/runs" | jq -r '.runs[1].id')so we can now use them to compare job versions between runs:
diff <(curl -s "http://localhost:5000/api/v1/jobs/runs/$CURRENT_RUN_ID" | jq -r '.jobVersion.version') \
<(curl -s "http://localhost:5000/api/v1/jobs/runs/$PREVIOUS_RUN_ID" | jq -r '.jobVersion.version')1c1
< 9f65dbeb-3949-3ca0-8b15-1fc733d51c1d
---
> bd448c97-fbbe-3398-be31-f6f19b137a56We can immediately see there’s a difference. In Marquez, several factors determine job versioning:
-
Source code location
-
Job context
-
Input datasets
-
Output datasets
Marquez creates job versions using a deterministic function based on these four inputs. If any of them changes, a new version is generated.
Let’s compare the two job versions to see what changed. First, we’ll exclude fields that we expect to be different: version, createdAt, updatedAt, and latestRun. We’ll also skip the id field since it contains the version number.
Let’s store job version identifiers:
CURRENT_JOB_VERSION=$(curl -s "http://localhost:5000/api/v1/jobs/runs/$CURRENT_RUN_ID" | jq -r '.jobVersion.version')
PREVIOUS_JOB_VERSION=$(curl -s "http://localhost:5000/api/v1/jobs/runs/$PREVIOUS_RUN_ID" | jq -r '.jobVersion.version')so we can use them to compare job configurations to identify what changed:
diff <(curl -s "http://localhost:5000/api/v1/namespaces/inventory/jobs/inventory.0/versions/$CURRENT_JOB_VERSION" | \
jq 'del(.["id", "version", "createdAt", "updatedAt", "latestRun"])') \
<(curl -s "http://localhost:5000/api/v1/namespaces/inventory/jobs/inventory.0/versions/$PREVIOUS_JOB_VERSION" | \
jq 'del(.["id", "version", "createdAt", "updatedAt", "latestRun"])')12,15d11
< "name": "inventory.orders"
< },
< {
< "namespace": "postgres://postgres:5432",
24a21,24
> },
> {
> "namespace": "postgres://postgres:5432",
> "name": "inventory.orders"
27a28,43
> {
> "namespace": "kafka://kafka:9092",
> "name": "inventory.inventory.geom"
> },
> {
> "namespace": "kafka://kafka:9092",
> "name": "inventory.inventory.products"
> },
> {
> "namespace": "kafka://kafka:9092",
> "name": "inventory.inventory.customers"
> },
> {
> "namespace": "kafka://kafka:9092",
> "name": "inventory.inventory.products_on_hand"
> },The comparison reveals that output datasets have changed, pointing to a possible schema change. We’re heading in the right direction - now we need to dig deeper.
Dataset comparison
Let’s now retrieve and save dataset version identifiers:
CURRENT_DATASET_VERSION=$(curl -s "http://localhost:5000/api/v1/jobs/runs/$CURRENT_RUN_ID" | jq -r '.outputDatasetVersions[0].datasetVersionId.version')
PREVIOUS_DATASET_VERSION=$(curl -s "http://localhost:5000/api/v1/jobs/runs/$PREVIOUS_RUN_ID" | jq -r '.outputDatasetVersions[2].datasetVersionId.version')so we can then compare dataset schemas to identify the exact nature of changes:
diff <(curl -s "http://localhost:5000/api/v1/namespaces/kafka%3A%2F%2Fkafka%3A9092/datasets/inventory.inventory.orders/versions" | \
jq --arg target_version "$CURRENT_DATASET_VERSION" '.versions[] | select(.createdByRun.outputDatasetVersions[]?.datasetVersionId.version == $target_version) | del(.["id", "version", "createdAt", "createdByRun"])') \
<(curl -s "http://localhost:5000/api/v1/namespaces/kafka%3A%2F%2Fkafka%3A9092/datasets/inventory.inventory.orders/versions" | \
jq --arg target_version "$PREVIOUS_DATASET_VERSION" '.versions[] | select(.createdByRun.outputDatasetVersions[]?.datasetVersionId.version == $target_version) | del(.["id", "version", "createdAt", "createdByRun"])')9,10c9,10
< "name": "id",
< "type": "INT32",
---
> "name": "before",
> "type": "STRUCT",
15,16c15,16
< "name": "order_date",
< "type": "INT32",
---
> "name": "after",
> "type": "STRUCT",
21,22c21,22
< "name": "purchaser",
< "type": "INT32",
---
> "name": "source",
> "type": "STRUCT",
27,28c27,28
< "name": "quantity",
< "type": "INT32",
---
> "name": "transaction",
> "type": "STRUCT",
33,34c33,52
< "name": "product_id",
< "type": "INT32",
---
> "name": "op",
> "type": "STRING",
> "tags": [],
> "description": null
> },
> {
> "name": "ts_ms",
> "type": "INT64",
> "tags": [],
> "description": null
> },
> {
> "name": "ts_us",
> "type": "INT64",
> "tags": [],
> "description": null
> },
> {
> "name": "ts_ns",
> "type": "INT64",
42c60
< "currentSchemaVersion": "f7874ec9-3a90-334f-8930-233a3c1bced3",
---
> "currentSchemaVersion": "5d49a53b-2116-3216-9b84-7f9850cc6f4e",
47,48c65,88
< "name": "id",
< "type": "INT32"
---
> "name": "before",
> "type": "STRUCT",
> "fields": [
> {
> "name": "id",
> "type": "INT32"
> },
> {
> "name": "order_date",
> "type": "INT32"
> },
> {
> "name": "purchaser",
> "type": "INT32"
> },
> {
> "name": "quantity",
> "type": "INT32"
> },
> {
> "name": "product_id",
> "type": "INT32"
> }
> ]
51,52c91,114
< "name": "order_date",
< "type": "INT32"
---
> "name": "after",
> "type": "STRUCT",
> "fields": [
> {
> "name": "id",
> "type": "INT32"
> },
> {
> "name": "order_date",
> "type": "INT32"
> },
> {
> "name": "purchaser",
> "type": "INT32"
> },
> {
> "name": "quantity",
> "type": "INT32"
> },
> {
> "name": "product_id",
> "type": "INT32"
> }
> ]
55,56c117,176
< "name": "purchaser",
< "type": "INT32"
---
> "name": "source",
> "type": "STRUCT",
> "fields": [
> {
> "name": "version",
> "type": "STRING"
> },
> {
> "name": "connector",
> "type": "STRING"
> },
> {
> "name": "name",
> "type": "STRING"
> },
> {
> "name": "ts_ms",
> "type": "INT64"
> },
> {
> "name": "snapshot",
> "type": "STRING"
> },
> {
> "name": "db",
> "type": "STRING"
> },
> {
> "name": "sequence",
> "type": "STRING"
> },
> {
> "name": "ts_us",
> "type": "INT64"
> },
> {
> "name": "ts_ns",
> "type": "INT64"
> },
> {
> "name": "schema",
> "type": "STRING"
> },
> {
> "name": "table",
> "type": "STRING"
> },
> {
> "name": "txId",
> "type": "INT64"
> },
> {
> "name": "lsn",
> "type": "INT64"
> },
> {
> "name": "xmin",
> "type": "INT64"
> }
> ]
59,60c179,194
< "name": "quantity",
< "type": "INT32"
---
> "name": "transaction",
> "type": "STRUCT",
> "fields": [
> {
> "name": "id",
> "type": "STRING"
> },
> {
> "name": "total_order",
> "type": "INT64"
> },
> {
> "name": "data_collection_order",
> "type": "INT64"
> }
> ]
63,64c197,210
< "name": "product_id",
< "type": "INT32"
---
> "name": "op",
> "type": "STRING"
> },
> {
> "name": "ts_ms",
> "type": "INT64"
> },
> {
> "name": "ts_us",
> "type": "INT64"
> },
> {
> "name": "ts_ns",
> "type": "INT64"
74a221,225
> },
> "symlinks": {
> "_producer": "https://github.com/OpenLineage/OpenLineage/tree/1.34.0/integration/flink",
> "_schemaURL": "https://openlineage.io/spec/facets/1-0-1/SymlinksDatasetFacet.json#/$defs/SymlinksDatasetFacet",
> "identifiers": []We’ve confirmed a schema change occurred. Now we need to determine what triggered it.
Root cause identification
The final step involves identifying the configuration change that caused the schema change. Compare the job versions that created the different dataset versions:
diff <(curl -s "http://localhost:5000/api/v1/namespaces/kafka%3A%2F%2Fkafka%3A9092/datasets/inventory.inventory.orders/versions" | \
jq --arg target_version "$CURRENT_DATASET_VERSION" '.versions[] | select(.createdByRun.outputDatasetVersions[]?.datasetVersionId.version == $target_version) | .createdByRun.jobVersion') \
<(curl -s "http://localhost:5000/api/v1/namespaces/kafka%3A%2F%2Fkafka%3A9092/datasets/inventory.inventory.orders/versions" | \
jq --arg target_version "$PREVIOUS_DATASET_VERSION" '.versions[] | select(.createdByRun.outputDatasetVersions[]?.datasetVersionId.version == $target_version) | .createdByRun.jobVersion')< "version": "9f65dbeb-3949-3ca0-8b15-1fc733d51c1d"
---
> "version": "bd448c97-fbbe-3398-be31-f6f19b137a56"
```So we take note of job version ids and use them to check what has changed
diff <(curl -s "http://localhost:5000/api/v1/namespaces/inventory/jobs/inventory.0" | \
jq --arg target_version "9f65dbeb-3949-3ca0-8b15-1fc733d51c1d" '.latestRuns[] | select(.jobVersion.version == $target_version) | del(.["id", "version", "createdAt", "updatedAt", "latestRun"])') \
<(curl -s "http://localhost:5000/api/v1/namespaces/inventory/jobs/inventory.0" | \
jq --arg target_version "bd448c97-fbbe-3398-be31-f6f19b137a56" '.latestRuns[] | select(.jobVersion.version == $target_version) | del(.["id", "version", "createdAt", "updatedAt", "latestRun"])')4,7c4,7
< "state": "RUNNING",
< "startedAt": "2025-07-10T09:21:12.985879Z",
< "endedAt": null,
< "durationMs": null,
---
> "state": "COMPLETED",
> "startedAt": "2025-07-10T09:20:39.231621Z",
> "endedAt": "2025-07-10T09:21:03.860Z",
> "durationMs": 24629,
12c12
< "version": "9f65dbeb-3949-3ca0-8b15-1fc733d51c1d"
---
> "version": "bd448c97-fbbe-3398-be31-f6f19b137a56"
59a60,75
> "name": "inventory.inventory.customers",
> "version": "46b86c1e-162d-3155-aecc-6bb6f8f35128"
> },
> "facets": {}
> },
> {
> "datasetVersionId": {
> "namespace": "kafka://kafka:9092",
> "name": "inventory.inventory.geom",
> "version": "80413cf4-dce5-3fec-8e86-322b6a35c8df"
> },
> "facets": {}
> },
> {
> "datasetVersionId": {
> "namespace": "kafka://kafka:9092",
61c77,93
< "version": "5bc1a4b7-4568-37cf-880b-507139865500"
---
> "version": "2c23ea5c-8349-3484-afe4-f70ed6c283d3"
> },
> "facets": {}
> },
> {
> "datasetVersionId": {
> "namespace": "kafka://kafka:9092",
> "name": "inventory.inventory.products",
> "version": "3a9f3ec2-5a42-3bad-a658-9351b3a45311"
> },
> "facets": {}
> },
> {
> "datasetVersionId": {
> "namespace": "kafka://kafka:9092",
> "name": "inventory.inventory.products_on_hand",
> "version": "c5a10775-a191-3e8f-a548-3aaab54defcf"
85c117
< "transforms=unwrap,openlineage",
---
> "transforms=openlineage",
95d126
< "transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState",Looking at the last part, we can see that io.debezium.transforms.ExtractNewRecordState has been added. Elementary, my dear Watson - here’s our troublemaker!
Resource cleanup
When you’re finished with the demonstration, clean up all resources:
docker compose -f docker-compose-flink.yaml down
docker rmi debezium/flink-job
cd marquez && .docker/down.sh
docker volume ls | grep marquez | awk '{print $2}' | xargs docker volume rmConclusion
This demonstration shows how data lineage becomes even more powerful now that Debezium also emits lineage events, creating a more complete picture and giving users full pipeline observability.
One of the most compelling advantages is how OpenLineage producers automatically captures comprehensive metadata about data sources, transformations, and outputs. This happens seamlessly in the background, requiring no manual instrumentation or code modifications from development teams. The system quietly builds a complete picture of data movement and transformation as operations unfold naturally.
When changes inevitably occurs, data lineage provides detailed visibility into the evolution process. Rather than scrambling to understand what changed and when, teams can quickly see the precise modifications, their timing, and which downstream systems were affected. The rich metadata collected enables rapid root cause analysis that would otherwise require significant detective work. What might have taken hours of investigation can now be resolved in minutes, as we demonstrated in our case study.
Beyond troubleshooting, this integration provides operational transparency that empowers teams to understand their complex streaming architectures fully. The complete visibility into data flow enables better decision-making around system changes and helps teams anticipate potential impacts before they occur. This capability becomes essential as data systems continue to grow in complexity, where comprehensive lineage tracking can mean the difference between rapid issue resolution and prolonged system downtime.
Ready to get started? Check out the Debezium OpenLineage documentation to enable this powerful integration in your own pipelines!
Fiore Mario Vitale
Active in the open-source community with contributions to various projects, Mario is deeply involved in developing Debezium, the distributed platform for change data capture. During his career he developed extensive experience in event-driven architectures heavily influenced by data. Throughout his career, Mario has predominantly focused on data-intensive software and product development, which has heightened his sensitivity to developer experience and data-driven applications. Beyond his professional pursuits, Mario finds his sweet spot where tech and his personal interests come together. He loves taking photos, especially when he manages to freeze a beautiful moment. He's also passionate about motorsports and racing. When he's not coding, you can often find him exploring the great outdoors on his mountain bike, fueling his passion for adventure.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.