
Although the end of summer is near, the Debezium team has a hot off the pressed preview release available with a fresh batch of improvements and enhancements. With Debezium 3.3.0.Beta1, this release brings a variety of stability fixes, performance optimizations, and user experience improvements across the connector ecosystem. Let’s take a look at what those are.
Breaking changes
With any new major release of software, there is often several breaking changes. The Debezium 3.3.0.Beta1 release is no exception, so let’s discuss the major changes you should be aware of.
Cassandra JMX metrics have changed
In previous iterations of the Debezium for Cassandra connector, each JMX metric was exposed as different MBeans in the <logical-name> domain, with an example shown below:
#domain = <logical-name>:
<logical-name>:name=commitlog-filename
<logical-name>:name=commitlog-positionThis approach significantly differs from other connectors where the metrics implementation has a single domain with multiple MBeans, i.e.:
#domain = debezium.cassandra:
debezium.cassandra:context=snapshot,server=<logical-name>,type=connector-metrics
debezium.cassandra:context=streaming,server=<logical-name>,type=connector-metricsNow any metric that pertains to snapshot will be in the snapshot MBean and those for streaming are in the streaming MBean (DBZ-9281). Using the commitlog-filename as an example, it is now in the streaming MBean as CommitLogFilename.
| Please see the Cassandra documentation for all details about the new JMX metrics names. |
Debezium Engine class loader changes
Debezium Engine did not set thread context classloader which could complicate integration with projects like SpringBoot. The thread context classloader is now set and Debezium Engine uses provided classloader to load all classes, not only the connector (DBZ-9375).
New features and improvements
The following describes all noteworthy new features and improvements in Debezium 3.3.0.Beta1. For a complete list, be sure to read the release notes for more details.
Notify Platform users of pipeline restart on changes
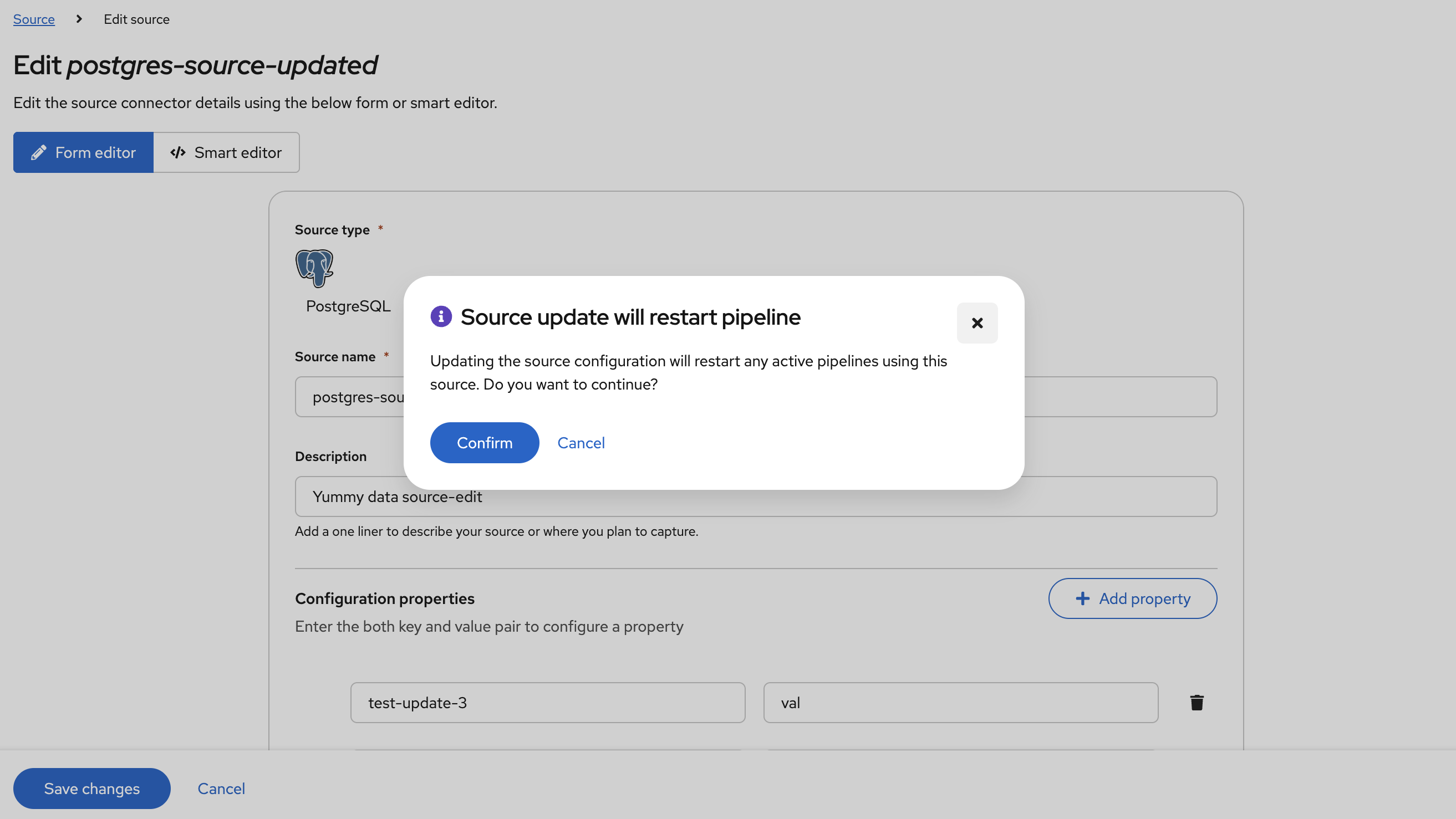
When working with the Debezium Platform, a source, destination, or other resources may be shared across two or more pipelines. When making changes to these resources, any pipeline that makes use of that resource must be restarted for those changes to take effect.
In an effort to avoid unexpected outcomes due to pipeline restarts, Debezium Platform will notify users when making changes that could lead to a pipeline being restarted so that the updated configuration can be applied (DBZ-9104).
MongoEventRouter supports custom tracing values
The MongoEventRouter now supports the ability to pass custom tracing configuration values into the router so they’re made available in the event payload (DBZ-9328). The following configuration options can be provided:
| Property | Description |
|---|---|
| THe name of the field containing |
| The operation name representing the Debezium procesing span, defaulting to |
| Set to |
Improved heartbeat processing for all connectors
The new ScheduledHeartbeat implementation is unified across the various connector implementations (DBZ-9377). This provides a common API and consistent heartbeat behavior for all connectors.
Only alter PostgreSQL publication as needed
When a Debezium PostgreSQL connector is configured with publication.autocreate.mode set to filtered, the connector issues an ALTER PUBLICATION statement on each connector restart to guarantee that the publication remains aligned with the connector configuration.
In some cases where the underlying tables may be undergoing a vacuum or are involved in a long-running DDL operation, this will force the connector wait until those tasks complete before the alter can complete. In an effort to streamline this and to only block when absolutely necessary, the connector will now check the configured table list against the publication when using filtered mode. Only if there are differences in the table list will the alter command be executed, otherwise it is skipped to avoid potential blocking calls (DBZ-9395).
Connector startup fails with cryptic error
We’ve resolved an issue where connectors would fail to start with a misleading error message, restoring smooth startup while preserving improved offset validation.
Users began encountering this confusing exception during connector startup in one corner case:
org.apache.kafka.connect.errors.DataException: Invalid value: null used for required field: "schema", schema type: STRINGThis cryptic error message provided no useful information about what was actually wrong, making troubleshooting nearly impossible.
The issue was an unintended consequence of a recent improvement we made to offset validation. We enhanced the logic to provide better error messages when offset positions are no longer available in the source database—a valuable feature that helps diagnose common operational issues.
However, the new validation logic made assumptions about certain offset attributes being available during connector startup. In reality, these attributes aren’t populated until later in the connector’s lifecycle, causing the validation to fail prematurely with an unhelpful error message.
We’ve updated the exception handling logic to:
-
Avoid assumptions about offset attribute availability during startup
-
Preserve the enhanced validation for cases where offsets are genuinely invalid
-
Provide meaningful error messages when offset positions are actually problematic
-
Allow normal startup to proceed without false positives
This fix ensures you get the benefits of enhanced error reporting without the startup disruption (DBZ-9416).
Possible data loss after failed ad-hoc blocking snapshots
We’ve resolved a critical issue that could cause data loss when ad-hoc blocking snapshots encountered problems, ensuring your streaming data remains intact even when snapshots fail.
When running ad-hoc blocking snapshots, encountering invalid data in a table would cause the snapshot to fail. Unfortunately, this failure had a serious side effect: streaming events that occurred during the snapshot period were permanently lost.
This meant that if your snapshot ran for several hours before hitting bad data, all the real-time changes that happened during those hours would be skipped entirely when the connector resumed normal streaming operations.
Blocking snapshots now handle failures gracefully by:
-
Preserving the streaming position from immediately before the snapshot began
-
Automatically resuming from the correct position when the snapshot fails
-
Ensuring zero data loss regardless of when or why the snapshot encounters issues
This improvement makes blocking snapshots much more reliable for production environments (DBZ-9337).
Oracle’s Last Batch Processing Throughput Metric Improved
We’ve enhanced the accuracy of the LastBatchProcessingThroughput JMX metric in the Oracle LogMiner adapter, giving you better visibility into your connector’s performance.
Previously, this metric calculated throughput based on the number of captured table events that were actually processed during each batch. While this seemed logical, it led to misleading results in several common scenarios:
-
Database-level filtering would reduce the count of processed events, even though the connector was still doing the work to read and evaluate those filtered records
-
Transaction markers in the event stream could skew the numbers, sometimes dramatically understating the actual processing load
-
Various configuration settings would impact the metric in ways that didn’t reflect the connector’s true performance
The metric now measures throughput based on the physical number of JDBC rows read from the LogMiner dataset, regardless of whether those rows end up being:
-
Filtered out by your configuration in the JVM
-
Transaction control records
-
Events that don’t match your table or schema filters
This gives you a much more accurate picture of the raw processing power your Debezium connector is delivering during each batch processing window (DBZ-9399).
Other changes
-
Debezium not recovering from connection errors DBZ-7872
-
JdbcSchemaHistory Fails to Handle Data Sharding When Recovering Records DBZ-8979
-
Debezium Quarkus Outbox Extension does not work with Hibernate ORM 7 DBZ-9193
-
Debezium Engine Quarkus Extension: add a quick start in the example repository DBZ-9301
-
Add a rest API to validate a connection DBZ-9315
-
Oracle connector does not support large CLOB and BLOB values DBZ-9392
-
Oracle DDL parser exception - DROP MATERIALIZED DBZ-9397
-
Debezium Platform OpenAPI spec miss returns schemas DBZ-9405
-
Oracle connector does not parse syntax : PARALLEL in DDL DBZ-9406
-
Increase max allowed json string length DBZ-9407
-
Wrong default value of task.management.timeout.ms DBZ-9408
-
LCR flushing can cause low watermark to be invalidated DBZ-9413
-
Infinispan Protostream compatibility for Java compiler > 22 DBZ-9417
-
Context headers are added two times during an incremental snapshot DBZ-9422
In total, 30 issues were resolved in Debezium 3.3.0.Beta1. The list of changes can also be found in our release notes.
A big thank you to all the contributors from the community who worked diligently on this release:
Anil Dasari, Artem Shubovych, Barbara Lócsi, Chris Cranford, Giovanni Panice, Harris Nguyen, Jiri Pechanec, Joan Gomez, Jonathan Schnabel, Luke Alexander, Mario Fiore Vitale, Olivier Chédru, Rajendra Dangwal, Robert Roldan, Stefano Linguerri, and Vojtech Juranek!
Chris Cranford
Chris is a software engineer at IBM and formerly Red Hat where he works on Debezium and deepens his expertise in all things Oracle and Change Data Capture on a daily basis. He previously worked on Hibernate, the leading open-source JPA persistence framework, and continues to contribute to Quarkus. Chris is based in North Carolina, United States.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.