
Last week’s announcement of Quarkus sparked a great amount of interest in the Java community: crafted from the best of breed Java libraries and standards, it allows to build Kubernetes-native applications based on GraalVM & OpenJDK HotSpot. In this blog post we are going to demonstrate how a Quarkus-based microservice can consume Debezium’s data change events via Apache Kafka. For that purpose, we’ll see what it takes to convert the shipment microservice from our recent post about the outbox pattern into Quarkus-based service.
Quarkus is a Java stack designed for the development of cloud-native applications based on the Java platform. It combines and tightly integrates mature libraries such Hibernate ORM, Vert.x, Netty, RESTEasy and Apache Camel as well as the APIs from the Eclipse MicroProfile initiative, such as Config or Reactive Messaging. Using Quarkus, you can develop applications using both imperative and reactive styles, also combining both approaches as needed.
It is designed for significantly reduced memory consumption and improved startup time. Last but not least, Quarkus supports both OpenJDK HotSpot and GraalVM virtual machines. With GraalVM it is possible to compile the application into a native binary and thus reduce the resource consumption and startup time even more.
To learn more about Quarkus itself, we recommend to take a look at its excellent Getting Started guide.
Consuming Kafka Messages with Quarkus
In the original example application demonstrating the outbox pattern, there was a microservice ("shipment") based on Thorntail that consumed the events produced by the Debezium connector. We’ve extended the example with a new service named "shipment-service-quarkus". It provides the same functionality as the "shipment-service" but is implemented as a microservice based on Quarkus instead of Thorntail.
This makes the overall architecture look like so:
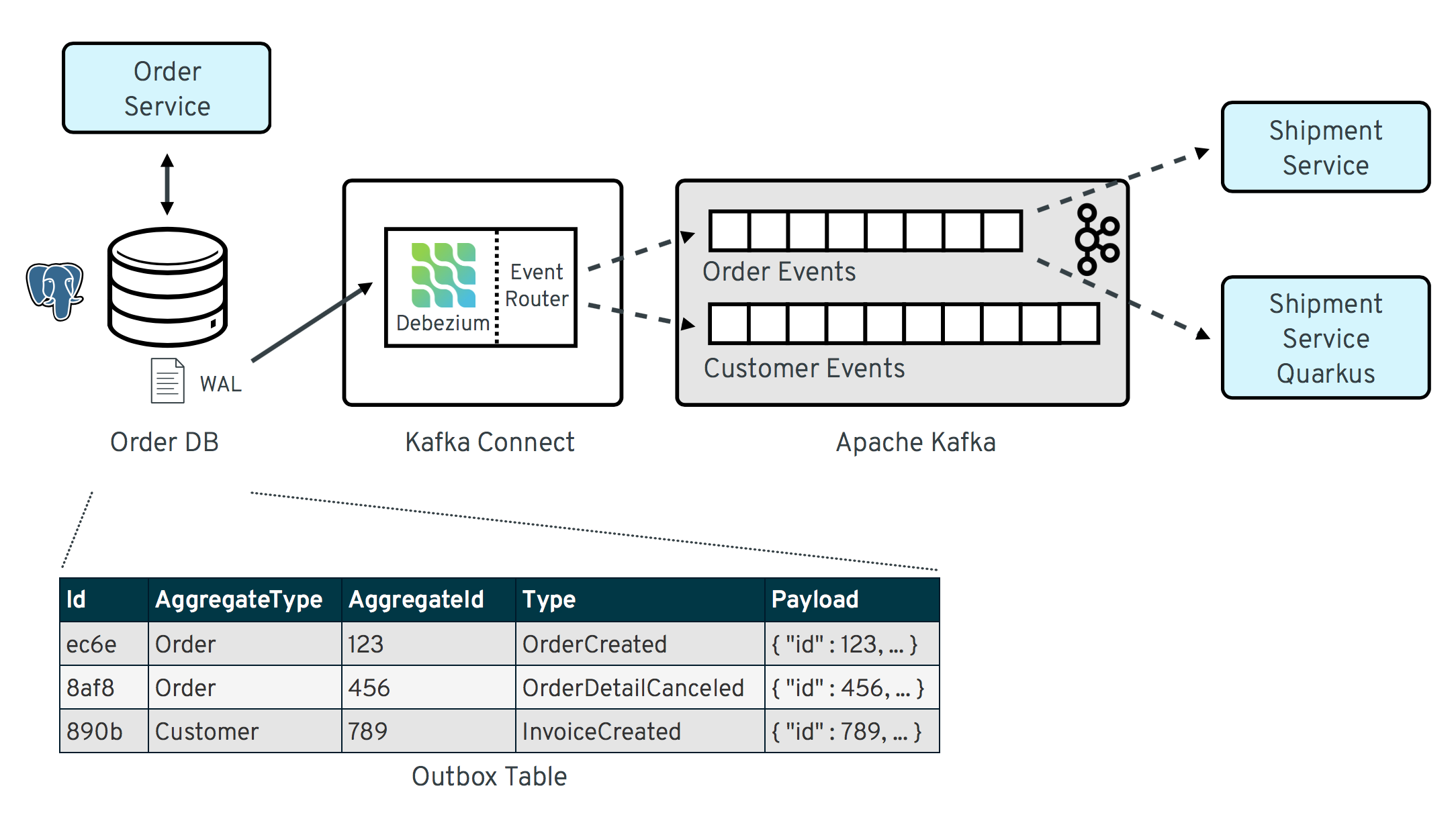
To retrofit the original service into a Quarkus-based application, only a few changes were needed:
-
Quarkus right now supports only MariaDB but not MySQL; hence we have included an instance of MariaDB to which the service is writing
-
The JSON-P API used do deserialize incoming JSON messages can currently not be used without RESTEasy (see issue #1480, which should be fixed soon); so the code has been modified to use the Jackson API instead
-
Instead of the Kafka consumer API, the Reactive Messaging API defined by MicroProfile is used to receive messages from Apache Kafka; as an implementation of that API, the one provided by the SmallRye project is used, which is bundled as a Quarkus extension
While the first two steps are mere technicalities, the Reactive Messaging API is a nice simplification over the polling loop in the original consumer. All that’s needed to consume messages from a Kafka topic is to annotate a method with @Incoming, and it will automatically be invoked when a new message arrives:
@ApplicationScoped
public class KafkaEventConsumer {
@Incoming("orders")
public CompletionStage<Void> onMessage(KafkaMessage<String, String> message)
throws IOException {
// handle message...
return message.ack();
}
}The "orders" message source is configured via the MicroProfile Config API, which resolves it to the "OrderEvents" topic already known from the original outbox example.
Build Process
The build process is mostly the same as it was before. Instead of using the Thorntail Maven plug-in, the Quarkus Maven plug-in is used now.
The following Quarkus extensions are used:
-
io.quarkus:quarkus-hibernate-orm: support for Hibernate ORM and JPA
-
io.quarkus:quarkus-jdbc-mariadb: support for accessing MariaDB through JDBC
-
io.quarkus:quarkus-smallrye-reactive-messaging-kafka: support for accessing Kafka through the MicroProfile Reactive Messaging API
They pull in some other extensions too, e.g. quarkus-arc (the Quarkus CDI runtime) and quarkus-vertx (used by the reactive messaging support).
In addition, two more changes were needed:
-
A new build profile named
nativehas been added; this is used to compile the service into a native binary image using the Quarkus Maven plug-in -
the
native-image.docker-buildsystem property is enabled when running the build; this means that the native image build is done inside of a Docker container, so that GraalVM doesn’t have to be installed on the developer’s machine
All the heavy-lifting is done by the Quarkus Maven plug-in which is configured in pom.xml like so:
<build>
<finalName>shipment</finalName>
<plugins>
...
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<version>${version.quarkus}</version>
<executions>
<execution>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
...
<profile>
<id>native</id>
<build>
<plugins>
<plugin>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<version>${version.quarkus}</version>
<executions>
<execution>
<goals>
<goal>native-image</goal>
</goals>
<configuration>
<enableHttpUrlHandler>true</enableHttpUrlHandler>
<autoServiceLoaderRegistration>false</autoServiceLoaderRegistration>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>Configuration
As any Quarkus application, the shipment service is configured via the application.properties file:
quarkus.datasource.url: jdbc:mariadb://shipment-db-quarkus:3306/shipmentdb
quarkus.datasource.driver: org.mariadb.jdbc.Driver
quarkus.datasource.username: mariadbuser
quarkus.datasource.password: mariadbpw
quarkus.hibernate-orm.database.generation=drop-and-create
quarkus.hibernate-orm.log.sql=true
smallrye.messaging.source.orders.type=io.smallrye.reactive.messaging.kafka.Kafka
smallrye.messaging.source.orders.topic=OrderEvents
smallrye.messaging.source.orders.bootstrap.servers=kafka:9092
smallrye.messaging.source.orders.key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
smallrye.messaging.source.orders.value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
smallrye.messaging.source.orders.group.id=shipment-service-quarkusIn our case it contains
-
the definition of a datasource (based on MariaDB) to which the shipment service writes its data,
-
the definition of a messaging source, which is backed by the "OrderEvents" Kafka topic, using the given bootstrap server, deserializers and Kafka consumer group id.
Execution
The Docker Compose config file has been enriched with two services, MariaDB and the new Quarkus-based shipment service. So when docker-compose up is executed, two shipment services are started side-by-side: the original Thorntail-based one and the new one using Quarkus. When the order services receives a new purchase order and exports a corresponding event to Apache Kafka via the outbox table, that message is processed by both shipment services, as they are using distinct consumer group ids.
Performance Numbers
The numbers are definitely not scientific, but provide a good indication of the order-of-magnitude difference between the native Quarkus-based application and the Thorntail service running on the JVM:
| Quarkus service | Thorntail service | |
|---|---|---|
memory [MB] | 33.8 | 1257 |
start time [ms] | 260 | 5746 |
application package size [MB] | 54 | 131 |
The memory data were obtained via htop utility. The startup time was measured till the message about application readiness was printed. As with all performance measurements, you should run your own comparisons based on your set-up and workload to gain insight into the actual differences for your specific use cases.
Summary
In this post we have successfully demonstrated that it is possible to consume Debezium-generated events in a Java application written with the Quarkus Java stack. We have also shown that it is possible to provide such application as a binary image and provided back-of-the-envelope performance numbers demonstrating significant savings in resources.
If you’d like to see the awesomeness of deploying Java microservices as native images by yourself, you can find the complete source code of the implementation in the Debezium examples repo. If you got any questions or feedback, please let us know in the comments below; looking forward to hearing from you!
Many thanks to Guillaume Smet for reviewing an earlier version of this post!
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.