
Today it’s my great pleasure to announce the availability of Debezium 1.0.0.Final!
Since the initial commit in November 2015, the Debezium community has worked tirelessly to realize the vision of building a comprehensive open-source low-latency platform for change data capture (CDC) for a variety of databases.
Within those four years, Debezium’s feature set has grown tremendously: stable, highly configurable CDC connectors for MySQL, Postgres, MongoDB and SQL Server, incubating connectors for Apache Cassandra and Oracle, facilities for transforming and routing change data events, support for design patterns such as the outbox pattern and much more. A very active and welcoming community of users, contributors and committers has formed around the project. Debezium is deployed to production at lots of organizations from all kinds of industries, some with huge installations, using hundreds of connectors to stream data changes out of thousands of databases.
The 1.0 release marks an important milestone for the project: based on all the production feedback we got from the users of the 0.x versions, we figured it’s about time to express the maturity of the four stable connectors in the version number, too.
Why Debezium?
One of the things making it so enjoyable to work on Debezium as a tool for change data capture is the variety of potential use cases. When presenting the project at conferences, it’s just great to see how people quickly get excited when they realize all the possibilities enabled by Debezium and CDC.
In a nutshell, Debezium is one big enabler for letting you react to changes in your data with a low latency. Or, as one conference attendee recently put it, it’s "like the observer pattern, but for your database".
Here’s a few things we’ve seen Debezium being used for as a ingestion component in data streaming pipelines:
-
Replicating data from production databases to other databases and data warehouses
-
Feeding data to search services like Elasticsearch or Apache Solr
-
Updating or invalidating caches
When using Debezium with Apache Kafka and its rich ecosystem of sink connectors, setting up such integrations can be done without any coding, just by means of deploying and configuring connectors in Kafka Connect:
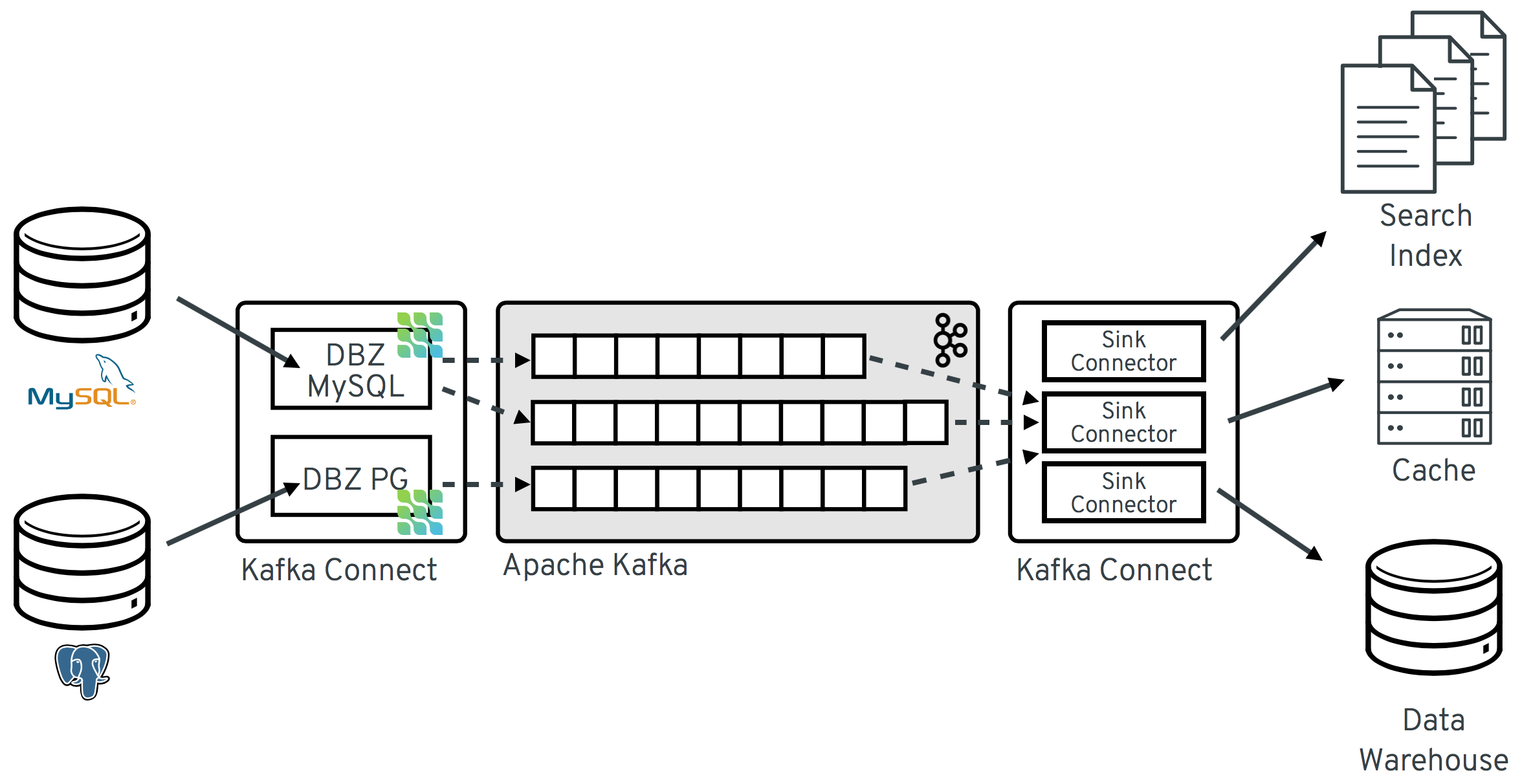
But there are many other use cases of CDC which go beyond just moving data from A to B. When adding stream processing into the picture, e.g. via Kafka Streams or Apache Flink, CDC enables you to run time-windowed streaming queries, continuously updated as your operational data changes ("what’s the aggregated order revenue per category within the last hour"). You can use CDC to build audit logs of your data, telling who changed which data items at what time. Or update denormalized views of your data, for the sake of efficient data retrieval, adhering to the CQRS pattern (Command Query Responsibility Segregation).
Finally, CDC can also play a vital role in microservices architectures; exchanging data between services and keeping local views of data owned by other services achieves a higher independence, without having to rely on synchronous API calls. One particularly interesting approach in this context is the outbox pattern, which is well supported by Debezium. In case you don’t start on the green field (who ever does?), CDC can be used to implement the strangler pattern for moving from a monolithic design to microservices.
You can learn more about change data capture use cases with Debezium and Apache Kafka in this presentation from QCon San Francisco.
But you don’t have to take our word for it: you can find lots of blog posts, conference talks and examples by folks using Debezium in production in our compilation of resources. If you’d like to get a glimpse of who else already is using Debezium, see our rapidly growing list of reference users (or send us a pull request to get your name added if your organization already is running Debezium in production).
Debezium 1.0
Now, let’s talk a little bit about the contents of the 1.0 release.
This version continues the effort we began in 0.10 to make sure the emitted event structures and configuration options of the connectors are correct and consistent. While we’ve always been very careful to ensure a smooth upgrading experience, you can expect even more stability in this regard going forward after the 1.0 release.
We’ve expanded the test coverage of databases (Postgres 12, SQL Server 2019, MongoDB 4.2), upgraded our container images to OpenJDK 11 and now build against the latest version of Apache Kafka (2.4.0; earlier versions continue to be supported, too). And last but not least, we’ve also fixed a large number of bugs. Overall, 96 issues were addressed in Debezium 1.0 and its preview releases (Beta1, Beta2, Beta3, CR1).
If you’re on 0.10 right now, the upgrade is mostly a drop-in replacement. When coming from earlier versions, please make sure to read the migration notes to learn about deprecated options, upgrading procedures and more.
The Most Important Part: The Debezium Community
Debezium couldn’t exist without its community of contributors and users. I can’t begin to express how grateful I am for having the chance to be a member of this fantastic community, interacting and working with folks from around the world towards our joint goal of building the leading open-source solution for change data capture.
At this point, about 150 people have contributed to the different Debezium code repositories (please let me know if I’ve missed anybody):
Aaron Rosenberg, Addison Higham, Adrian Kreuziger, Akshath Patkar, Alexander Kovryga, Amit Sela, Andreas Bergmeier, Andras Istvan Nagy, Andrew Garrett, Andrew Tongen, Andrey Pustovetov, Anton Martynov, Arkoprabho Chakraborti, artiship, Ashhar Hasan, Attila Szucs, Barry LaFond, Bartosz Miedlar, Ben Williams, Bin Li, Bingqin Zhou, Braden Staudacher, Brandon Brown, Brandon Maguire, Cheng Pan, Ching Tsai, Chris Cranford, Chris Riccomini, Christian Posta, Chuck Ha, Cliff Wheadon, Collin Van Dyck, Cyril Scetbon, David Chen, David Feinblum, David Leibovic, David Szabo, Deepak Barr, Denis Mikhaylov, Dennis Campagna, Dennis Persson, Duncan Sands, Echo Xu, Eero Koplimets, Emrul Islam, Eric S. Kreiseir, Ewen Cheslack-Postava, Felix Eckhardt, Gagan Agrawal, Grant Cooksey, Guillaume Rosauro, Gunnar Morling, Gurnaaz Randhawa, Grzegorz Kołakowski, Hans-Peter Grahsl, Henryk Konsek, Horia Chiorean, Ian Axelrod, Ilia Bogdanov, Ivan Kovbas, Ivan Lorenz, Ivan Luzyanin, Ivan San Jose, Ivan Vucina, Jakub Cechacek, Jaromir Hamala, Javier Holguera, Jeremy Finzel, Jiri Pechanec, Johan Venant, John Martin, Jon Casstevens, Jordan Bragg, Jork Zijlstra, Josh Arenberg, Josh Stanfield, Joy Gao, Jure Kajzer, Keith Barber, Kevin Pullin, Kewen Chao, Krizhan Mariampillai, Leo Mei, Lev Zemlyanov, Listman Gamboa, Liu Hanlin, Luis Garcés-Erice, Maciej Bryński, MaoXiang Pan, Mario Mueller, Mariusz Strzelecki, Matteo Capitanio, Mathieu Rozieres, Matthias Wessendorf, Mike Graham, Mincong Huang, Moira Tagle, Muhammad Sufyian, Navdeep Agarwal, Nikhil Benesch, Olavi Mustanoja, Oliver Weiler, Olivier Lemasle, Omar Al-Safi, Ori Popowski, Orr Ganani, Peng Lyu, Peter Goransson, Peter Larsson, Philip Sanetra, Pradeep Mamillapalli, Prannoy Mittal, Preethi Sadagopan, pushpavanthar, Raf Liwoch, Ram Satish, Ramesh Reddy, Randall Hauch, Renato Mefi, Roman Kuchar, Sagar Rao, René Kerner, Rich O’Connell, Robert Coup, Sairam Polavarapu, Sanjay Kr Singh, Sanne Grinovero, Satyajit Vegesna, Saulius Valatka, Scofield Xu, Sherafudheen PM, Shivam Sharma, Shubham Rawat, Stanley Shyiko, Stathis Souris, Stephen Powis, Steven Siahetiong, Syed Muhammad Sufyian, Tautvydas Januskevicius, Taylor Rolison, Theofanis Despoudis, Thomas Deblock, Tom Bentley, Tomaz Lemos Fernandes, Tony Rizko, Wang-Yu-Chao, Wei Wu, WenZe Hu, William Pursell, Willie Cheong, Wout Scheepers, Yang Yang, Zheng Wang
You’re amazing, and I would like to wholeheartedly thank each and everyone of you! I’m sure our community will continue to grow in the future — I’d love it if we hit the mark of 200 contributors in 2020.
Equally important are our users; interacting with you in the chat, on the mailing list or at conferences and meet-ups is what helps to drive the direction of the project: learning about your specific requirements and use cases (or bugs you’ve run into) is vital for deciding where to put the focus next. A big thank you to you, too!
Some of you even have shared their experiences with Debezium in conference talks and blog posts. Nothing beats hearing the war stories of others and being able to learn from their experiences, so you speaking about your insights around Debezium and CDC is incredibly helpful and highly appreciated!
What’s Next?
Let’s wrap up this post with a look to see what’s next in store for Debezium.
After some long over-due holidays, we’re planning to begin the work on Debezium 1.1 in January. Some of the potential features you can look forward to are:
-
Support for the CloudEvents specification as a portable event format
-
A Quarkus extension for implementing the outbox pattern
-
A stand-alone Debezium server which will let you stream data change events to messaging infrastructure such as Amazon Kinesis
-
Means of exposing transactional boundaries on a separate topic, allowing to aggregate all the events originating from one source transaction and process them at once
-
Further progression of the incubating community-led connectors for Oracle and Apache Cassandra
Of course, this roadmap is strongly influenced by the community, i.e. you. So if you would like to see any particular items here, please let us know.
We also have some exciting blog posts in the workings, e.g. on how to combine Debezium with the brand-new Kafka Connect connector for Apache Camel or how to use the recently added support for non-key joins in Kafka Streams (KIP-213) with Debezium change events.
One more thing I’m super-thrilled about is Debezium becoming a supported component of the Red Hat Integration product. Part of the current release is a Tech Preview for the change data capture connectors for MySQL, Postgres, SQL Server and MongoDB. This is great news for folks who wish to have commercial support by Red Hat for their CDC connectors.
For now, let’s celebrate the release of Debezium 1.0 and look forward to what’s coming in 2020.
Onwards and Upwards!
Gunnar Morling
Gunnar is a software engineer and open-source enthusiast by heart, currently working as a Technologist at Confluent. Previously, he helped to build a realtime stream processing platform based on Apache Flink and led the Debezium project, a distributed platform for change data capture. He is a Java Champion and has founded multiple open source projects such as JfrUnit, kcctl, and MapStruct. Gunnar is an avid blogger (morling.dev) and has spoken at various conferences like QCon, Java One, and Devoxx. He lives in Hamburg, Germany.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.