
In this blog post, we are going to discuss how Delhivery, the leading supply chain services company in India, is using Debezium to power a lot of different business use-cases ranging from driving event driven microservices, providing data integration and moving operational data to a data warehouse for real-time analytics and reporting. We will also take a look at the early mistakes we made when integrating Debezium and how we solved them so that any future users can avoid them, discuss one of the more challenging production incidents we faced and how Debezium helped ensure we could recover without any data loss. In closing, we discuss what value Debezium has provided us, areas where we believe there is a scope for improvement and how Debezium fits into our future goals.
Debezium at Delhivery
We work in the logistics landscape and hence most of the software we write is focused around state - status changes of a shipment, tracking location updates, collecting real time data and reacting to it. The most common place where you might find "state" in any software architecture is the database. We maintain all of our transactional data primarily in a document database like MongoDB and in relational database systems (specifically PostgreSQL) for different services within the organisation. There is a need to allow efficient and near-real time analysis of the transactional data across all the different data sources to allow surfacing insights and looking at the big picture of how the organisation is doing and to make data driven decisions.
To solve the above goal, we are using Debezium to perform Change Data Capture on our transactional data to make it available in Kafka, our choice of message broker. Once that data is available in Kafka we can do one or all of the following:
-
Perform streaming joins or data enrichment across change streams of different relational tables (maybe even from different databases or services altogether. eg. Enriching shipments with trip and vehicle data)
-
Creating domain events from change streams for consumption by downstream services (eg. Creating an aggregate message with order, shipment and product information from three different change streams)
-
Moving the change stream data into a data lake to allow for disaster recovery or replaying part of the data
-
Complex event processing to generate real time metrics and power dashboards (eg. Live count of items in transit, average trip time within each region etc.)
Debezium makes all of those above use-cases possible and very easy to build by providing a common platform and framework to connect our existing data sources like MongoDB, PostgreSQL or MySQL.
This article is going to share our learnings with using Debezium on AWS RDS (AWS’s managed database service) and hopefully help transfer some knowledge we’ve gained in that process and also document how to skip unparseable records from PostgreSQL’s WAL until DBZ-1760 is fixed (already implemented and scheduled for the next Debezium 1.1 preview release).
Here’s a brief architecture overview that shows a few of the use-cases that Debezium is powering and the general data platform.
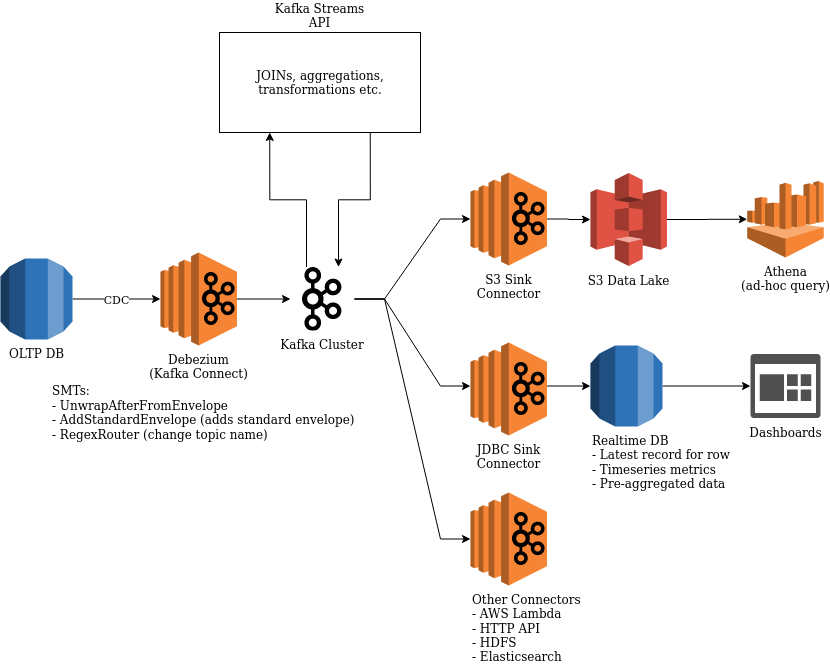
Figure 1. Current Architecture
But to get to the above was an iterative process which took a lot of experimentation and trial and error.
Debezium with PostgreSQL on AWS RDS
Now we are going to discuss some of the learnings from running Debezium with PostgreSQL on AWS RDS. We are not going to focus on how to get started with Debezium with PostgreSQL on RDS since it’s documented in detail at the documentation for the PostgreSQL connector.
Lessons Learnt
We started by creating a proof-of-concept whose goal was to listen to changes from 3 different tables within a single PostgreSQL database and create two views downstream, one as the join of the three tables and another view which includes aggregated metrics tracked as a time-series. Both the join and the aggregations were implemented using Kafka Streams since it was easier to setup and learn compared to other stream processing frameworks. Since Debezium already provides a very feature rich Docker container image we extended that slightly and decided to run the service as containers on AWS’s Elastic Container Service which is a container orchestration service.
There were a few mistakes we made when we were starting out. All of the solutions to our mistakes are now documented in the Debezium documentation but they are all listed together here to make it easier to avoid them.
-
We initially used the wal2json plugin which caused the connector to encounter OutOfMemoryError when committing large transactions (transactions whose serialized form uses more memory than available Java Heap space). Hence our recommendation is:
-
On PostgreSQL < 10, use the wal2json_streaming plugin to avoid OutOfMemoryError on large transactions.
-
On PostgreSQL >= 10, use the pgoutput plugin.
-
-
We were producing JSON messages with schemas enabled; this creates larger Kafka records than needed, in particular if schema changes are rare. Hence we decided to disable message schemas by setting
key.converter.schemas.enabledandvalue.converter.schemas.enabledtofalseto reduce the size of each payload considerably hence saving on network bandwidth and serialization/deserialization costs. The only downside is that we now need to maintain the schema of those messages in an external schema registry. -
We were observing a few data-types with base64 encoded data. As documented, that’s the default for NUMERIC columns, but can be difficult to handle for consumers. To convert to a format that’s easier to parse at the expense of some accuracy loss, we configured the data type specific properties as documented. Specifically, set
decimal.handling.modetostringto receive NUMERIC, DECIMAL and equivalent types as a string (eg. "3.14") and sethstore.handling.modetojsonto receive HSTORE columns as a JSON string. -
Always ensure basic hygiene checks like database disk usage, transaction logs disk usage and network and disk bandwidth being used for read and write operations. No alarms were set up on the transaction logs disk usage on the database. We added alarms on the RDS metric TransactionLogsDiskUsage and OldestReplicationSlotLag to alert us when the transaction logs disk usage increased above a threshold or when a replication slot started lagging - meaning that Debezium might have died.
-
We had not enabled heartbeats in Debezium. Heartbeats are needed to control the WAL disk space consumption in the following cases:
-
There are many updates in a monitored database but only a minuscule amount relates to the monitored table(s) and/or schema(s). We handled this case by enabling heartbeats by setting
heartbeat.interval.ms. -
The PostgreSQL instance contains multiple databases where the monitored database is low-traffic in comparison to the others. Since the WAL is shared by all databases in an instance it keeps accumulating data which cannot be removed until Debezium reads it. But since the high traffic databases are not monitored Debezium is not able to communicate to the database that the WAL files can be removed to reclaim disk space. To solve this scenario we triggered "heartbeat" events by periodically updating a single row in a table created in the monitored database using the below query:
CREATE TABLE IF NOT EXISTS heartbeat (id SERIAL PRIMARY KEY, ts TIMESTAMP WITH TIME ZONE); INSERT INTO heartbeat (id, ts) VALUES (1, NOW()) ON CONFLICT(id) DO UPDATE SET ts=EXCLUDED.ts;Since this is a common use-case that comes up when using Debezium with PostgreSQL, an issue has been created to track this at DBZ-1815.
-
-
We got severely reduced throughput on tables with JSONB columns. After debugging we were able to confirm the reason as frequent schema refresh by Debezium due to TOASTed columns not being present in the replication message. This was fixed by changing
schema.refresh.modetocolumns_diff_exclude_unchanged_toastand has since been documented. -
We observed frequent EOF errors on the database connection on a few RDS instance sizes. We are still not sure of the cause but initial investigations point to the issue happening only on instances that have PgBouncer attached (even if not connecting through PgBouncer) or instances with smaller sizes (AWS t2/t3 series).
-
We initially used a single Debezium connector per PostgreSQL database (instead of per host) but then moved to using a single connector for each team. The main reasons for not running a single connector per PostgreSQL instance were regarding workload isolation. Any team performing bulk data updates or deletions or unplanned schema migrations will only impact their own Debezium connector instead of the entire PostgreSQL instance since Debezium filters events at its end according to the database and/or schema whitelist and blacklist configured. We are trying to identify possible issues in this configuration but haven’t found any yet. Moving to a single connector per team setup also eased a lot of management overhead regarding configuration changes since we no longer need to co-ordinate between multiple teams when creating a release plan for any changes. Although multiple replication slots on a single database do add overhead, we are able to run fine with around 6 to 10 slots per database host without any noticeable performance impact.
Production Incidents
As is common with every software development project we did hit a few issues and here we discuss one of the more difficult ones in detail. But thanks to Debezium being focused on ensuring data consistency we were able to recover without ANY data loss.
| The issue we discuss below is already fixed in Debezium 1.0 and you should update as soon as possible. A new feature for skipping such unprocessable events in general has been merged as PR#1271 in the core Debezium framework and will be part of the next Debezium 1.1 preview release. |
Two of the common things developers often fail to do are proper date-time handling and software version upgrades. Both of these can lead to issues on their own but makes things difficult when both occur together. We recently faced such an issue and provide a way to handle it. We’ll start with some background on why this issue came up in the first place.
PostgreSQL’s date/time types documentation states that the TIMESTAMP types can range from 4713 BC to 294276 AD. Before Debezium 0.10, there were serveral issues regarding datetime overflow for dates too far into the future like DBZ-1255 and DBZ-1205.
The Bug and Dealing With It
To hit the above issue you need to have a date sufficiently far into the future. You can get one if you are not using ISO8601 or epoch time and have a bug in your custom datetime formatter.
So, the bug was triggered by the application writing a datetime value containing the year 20200 into one of the tables monitored by Debezium which caused Debezium to throw an exception since we were still running on 0.9 in production.
Unfortunately our log pattern alerts did not work that day and the error silently skipped past us until the high replication lag alarms went off. Upon inspecting the logs we did figure out where the issue was coming from and for which value. Unfortunately the log did not tell what table the issue was in (hint - can become a valuable contribution) and which column contained the offending value. Luckily only four tables were monitored and each of them had two TIMESTAMPTZ columns and it was easy to query for the offending value in those to find the actual record.
A quick read of the source code showed us that this was happening for any year > 9999 and hence we queried the database to check if any other such values existed. Thankfully no other values existed. By now we had a clear plan in mind:
-
Stop Debezium
-
Correct the data for the record
-
Somehow get Debezium to skip the unparseable record
-
Add validations to database to ensure such values don’t skip through for the time being
-
Upgrade Debezium to 1.0
But we were stuck at the 3rd step above since we could not find an equivalent option to MySQL’s event.deserialization.failure.handling.mode for the PostgreSQL connector.
How Debezium and PostgreSQL track offsets
Each change record in PostgreSQL has a position which is tracked using a value known as a log sequence number (LSN). PostgreSQL represents it as two hexadecimal numbers - logical xLog and segment. Debezium represents it as the decimal representation of that value. The actual conversion implementation can be seen in PostgreSQL’s JDBC driver here.
Periodically Debezium writes the last processed LSN and transaction id to the Kafka Connect offsets topic and advances the replication slot to match that. On startup, Debezium uses the last record from the Kafka Connect offsets topic to rewind the replication slot to the position as described before continuing streaming changes. This means that to change the position in the WAL where Debezium picks up from requires a change in both Debezium’s tracked information in the Kafka Connect offsets topic as well as server side in PostgreSQL.
Skipping Unparseable Events
We were able to use the above information to make Debezium skip the unparseable event by performing the following steps:
-
Stop Debezium to make the replication slot inactive.
-
Check Debezium has stopped listening on the replication slot by running
SELECT * FROM pg_replication_slots WHERE slot_name = '<your-slot-name>';. Theactivecolumn should bef. -
Check the last message in Debezium’s offsets topic and note down the value for the
lsnkey. eg.1516427642656. -
Convert that long representation of LSN into the hexadecimal format using PosgtreSQL’s Java driver using the below Java code:
import org.postgresql.replication.LogSequenceNumber; class Scratch { public static void main(String[] args) { LogSequenceNumber a = LogSequenceNumber.valueOf(1516427642656L); System.out.println(a.asString()); } } -
Peek changes from the WAL upto the LSN above using
SELECT pg_logical_slot_peek_changes('<your-slot-name>', '<lsn-from-above>', 1). This is the replication change that we are going to skip, so please make sure that this is the record that you want to skip. Once confirmed, proceed to next step. -
Advance the replication slot by skipping 1 change using
SELECT pg_logical_slot_get_changes('<your-slot-name>', NULL, 1). This will consume 1 change from the replication slot. -
Publish a message to Debezium’s offset topic with the next LSN and TxId. We were able to successfully get it working by adding 1 to both the
lsnand thetxId. -
Deploy Debezium again and it should have skipped the record.
Conclusion
Why Debezium?
In closing we would like to highlight the issues Debezium has solved for us.
One of the biggest concerns when handling any data is regarding data consistency and Debezium helps us avoid dual writes and maintains data consistency between our RDBMS and Kafka which makes it easier to ensure data consistency in all further layers.
Debezium enables low overhead change data capture and now we have ended up defaulting to enabling Debezium for all new data sources being created.
Debezium’s support for a wide variety of data sources, PostgreSQL, MySQL and MongoDB specifically, helps us provide a standard technology and platform to perform data integration on. No more having to write custom code to connect each data source.
Debezium being open source proved to be immensely useful in the early days to make sure we were able to send in patches for a few bugs ourselves without having to ask someone to prioritise the issue. And since it’s open source there is a growing community around it which can help you figure out your issues and provide general guidance. Check out this page on the Debezium website for a lot of awesome community contributed content.
Challenges
Having said the above Debezium is still quite a young project and has a few areas in which improvement will be welcome (and your contributions too in the form of code, design, ideas, documentation and even blog posts):
-
Zero-downtime high availability. Debezium relies on the Kafka Connect framework to provide high availability but it does not provide something similar to a hot standby instance. It takes time for an existing connector to shut down and a new instance to come up - which might be acceptable for a few use-cases but unacceptable in others. See this blog post by BlaBlaCar for a discussion and their solution around it.
-
Support for other data sinks besides Kafka. In a few scenarios you might want to directly move the events from your database to an API, a different data store or maybe a different message broker. But since Debezium is currently written on top of Kafka Connect it can only write the data into Kafka. Debezium does provide an embedded engine which you can use as a library to consume change events in your Java applications. See the documentation around embedding Debezium. In case you do end up writing a different adapter around Debezium to move data into a different destination, consider making it open source so that both you benefit by additional maintainers and the community benefits by getting new use cases solved.
-
Common framework to write any new CDC implementation. We particularly have a use case of performing CDC on top of AWS DynamoDB. Instead of writing a custom Kafka Connector from scratch, we can reuse the Debezium core framework and write only the DynamoDB specific parts. This will help prevent bugs since a lot of the existing flows and edge cases might have already been handled. There is ongoing work around this theme to refactor all existing Debezium connectors to use the common framework to make it easier to write new custom connectors. For an example of how to implement one, take a look at the Debezium incubator repository.
-
A few minor annoyances which are already tracked on the project’s issue tracker - specifically DBZ-1760 (skipping unparseable records), DBZ-1263 (update table whitelist for existing connector), DBZ-1723 (Reconnect to DB on failure), DBZ-823 (Parallel snapshots).
Future Scope
We do have a few tasks planned for the future to improve our existing workflow regarding Debezium and Kafka Connect.
-
Upgrading to Debezium v1.0. Debezium recently released the first 1.0 release with a number of new features including support for the CloudEvents format which we are looking towards to provide a unified message format for all data across the organisation.
-
Trying out the Outbox design pattern as documented at Reliable Microservices Data Exchange With the Outbox Pattern to unify application events and data change events. The outbox pattern also provides transactional guarantees across service boundaries in a microservices system - something everybody wants in an event based microservices architecture.
-
Setting up an Apache Atlas integration to automate the creation of data sources and tracking data lineage in Atlas to help with data governance and discoverability.
-
Writing and open sourcing an AWS DynamoDB CDC connector as a Debezium connector. Since we are using AWS DynamoDB too we need to provide the same capabilities that the other data sources are using in terms of CDC. For that we are writing a DynamoDB CDC connector using Debezium as a framework. The work is still in its early stages and is planned to be released as an open source connector.
So overall, we started the post by sharing our business use-case and discussed how Debezium has helped us solve them. We then detailed how we have been running Debezium in production for performing CDC on PostgreSQL on AWS RDS and talked about the mistakes we made when starting out and how to solve them. And as is common in software engineering, we did face production incidents along the way and are sharing our learnings from that incident in the hopes that they might be useful for the wider community.
Also a lot of thanks to the people who reviewed this post including Gunnar Morling, Kapil Bharati and Akash Deep Verma.
Further Reading
Debezium Documentation and Repositories
External Documentation
Blogs and Articles
Relevant Issues
Open Issues
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.