
Welcome to the first edition of "Debezium Community Stories With…", a new series of interviews with members of the Debezium and change data capture community, such as users, contributors or integrators. We’re planning to publish more parts of this series in a loose rhythm, so if you’d like to be part of it, please let us know. In today’s edition it’s my pleasure to talk to Renato Mefi, a long-time Debezium user and contributor.

Renato, could you introduce yourself? What is your job, if you’re not contributing to Debezium?
Hello all, I’m Renato and my first Debezium commit was on Nov 12, 2018, it’s been a long and fun ride so far, and I’m glad to have the opportunity to share my story here with you all!
I’m a Staff Software Engineer at SurveyMonkey in Amsterdam, The Netherlands, within the Platform team for our CX (customer experience) suite, if you’re curious about what that is, you can check it out here.
On the internet you’re going to find me talking about Docker, Debezium, Kafka, Microservices and other things that I enjoy. Although those amazing engineering pieces really excite me, at this moment I’m also really passionate about Platform Engineering teams and how they can operate in an organization, the stories I’m going to tell below represent my view of it, of how critical the role of a platform team can be when adopting new technologies and solving difficult problems for the whole, in this case powered by Debezium!
What are your use cases for Debezium and CDC in your current project?
It’s a long and enjoyable story (long in terms of the internet), we’ve been using Debezium since Q4 2018, it’s been 2 years at the moment I’m writing those answers here.
When I classify Debezium within our product, I say it is an architectural component, the idea behind this is to position it as a platform/infrastructure concern, in a way that it can reach multiple parts of the stack and services. I consider this abstraction of Debezium one of the key success factors it had in its adoption and growth within our platform, let me explain this better!
Our first use case is likely to be one of the most common ones for CDC, the strangler pattern, which for us came before Debezium; so let me tell this part of the story first: when I joined Usabilla (later acquired by SurveyMoney), there was already an effort to move our platform to a new architecture and the strangler pattern was already there. When the first couple of services started to grow, their primary way to bring data out of legacy was to poll the database, and needless to say, this could go very wrong! Our legacy database is a MongoDB cluster, and since I was pre-occupied with the polling approach, I started to dig into possibilities. I was hoping to find something like a streaming API for it, but what I ended up encountering was the database changelog (Write-ahead logging, "oplog" as it’s called in Mongo!
It came to my mind right away: "Oh, I could write something that queries the data from the oplog and sends it to Kafka". So I checked with our in-house Senior SRE and MongoDB expert Gijs Kunze who thought it could be a good idea; as a next step I went to talk to my colleague Rafael Dohms, and we decided to do some extra Googling, and like that, we found Debezium! It was the perfect match to our needs and better than what we could have written by ourselves!
Now back to our use case, what makes it an architecture component for us, is basically the approach, we abstracted and wrapped Debezium in a project called Legacy Data Syncer (LDS for us, because acronyms never get old). Although it might look simple to spin up a Kafka Connect with Debezium, running it production-ready, monitoring multiple collections within the database, exposing metrics, doing transformations and more, is not such an easy task. So how does it work? Every time an engineering team needs to capture data from our legacy system, to start strangling a feature, they only have to do two things, open a pull request which literally adds one line to LDS, and create their Kafka consumer!
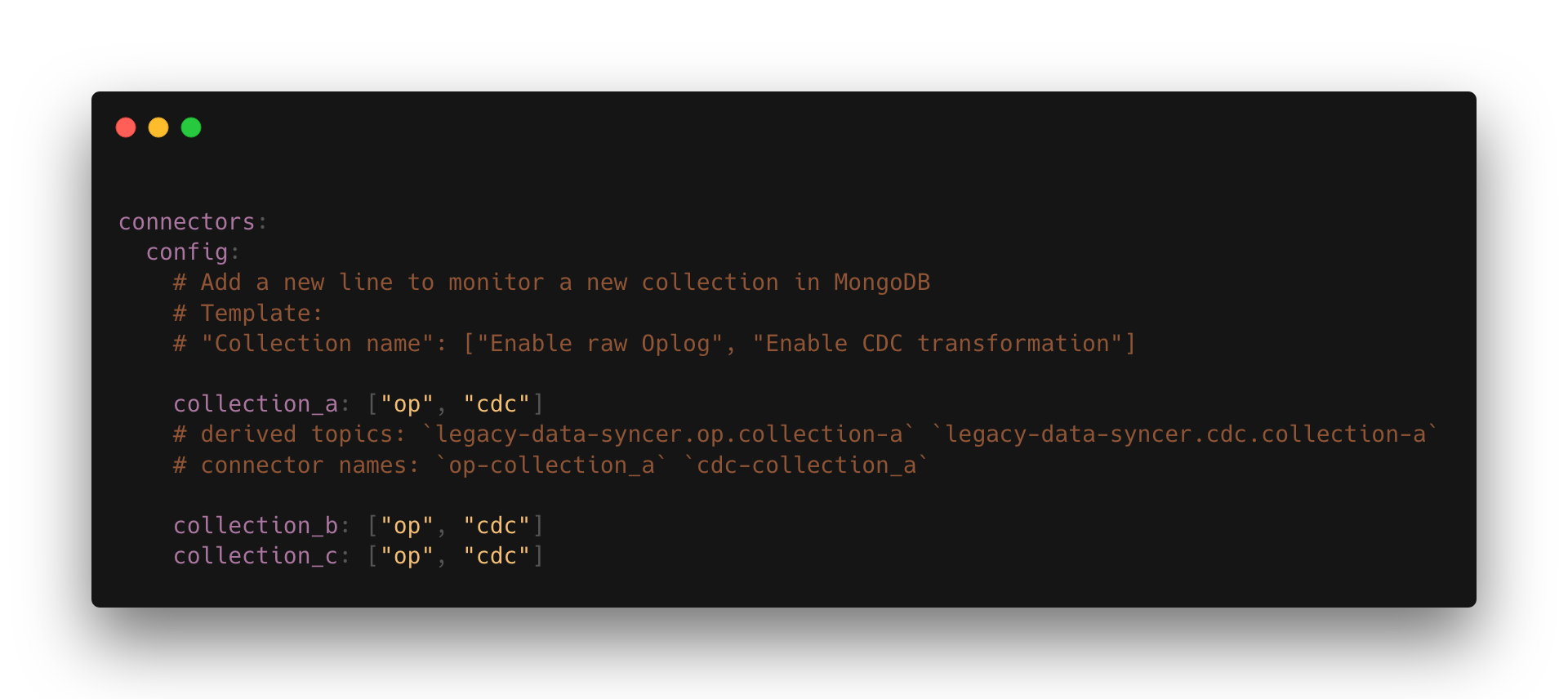
Figure 1. The configuration file in LDS; a developer will open a PR adding a new line, the rest will be taken care of.
Upon merging the PR, our project will provision the whole configuration to Kafka Connect, it ensures the snapshot is executed, metrics are present and etc; We’ve done the same thing for the outbox pattern and I talk a little bit more about it in this tweet thread.
Self-servicing the teams was a great way to remove resistance for adoption, no Jira tickets were necessary, no advanced ops knowledge or anything else to get it running. The other factors I consider to have contributed to Debezium’s success in our platform is its reliability and straight forward value perception, in those two years we never had major outages or critical problems of any kind!
You mention the outbox pattern; Could you tell more about why and how you’re using this?
Absolutely! One more time, it’s crazy how CDC and Debezium can simplify some of the most critical architectural parts of big platforms! One year after using Debezium in the core of our architecture migration, we had another problem at our hands: how to reliably write data to our new source of truth databases and propagate messages to Kafka at the same time. Although it seems to be simple to answer and find a solution, each of them comes with a major drawback.
Which solutions do we have?
-
Embrace eventual consistency to its peak by adopting event sourcing, by writing first to Kafka and reading our own writes; the drawbacks here are extra complexity and intensified eventual consistency
-
Dual writes, well, actually this is not an option, because as you know, "Friends Don’t Let Friends Do Dual Writes"!
-
Different approaches of distributed transactions like 2PC and sagas; the costs here are performance and engineering effort, now every service we have has to either become a transaction coordinator or have rollback capabilities, also the cascade effect scared us quite a bit!
Well, what’s left? We found that outbox was the right answer for us, but before we get there, let me get into the cost x benefit equation of our decision making!
Although some of the options were quite attractive technically, for instance event sourcing, the engineering effort and growth is immense. Also, it’s not the kind of thing which comes ready to use, and there’s a lot of discovery to be made along the way, so what were the constraints and desires:
-
Reliability; we want at least once semantics, exactly once isn’t necessary as we can uniquely identify each message/event;
-
Eventual consistency only between services, but not within the services themselves. Being able to interact with a service which is the source of truth of a certain model, and get an immediate answer is not just handy, but incredibly powerful (and that’s why monoliths are also so attractive);
-
Avoiding distributed transactions as much as we can, it’s scary and we should be scared about it too!
-
Manageable effort; how can we "easily" get 30+ engineers to adopt a solution for this problem? At the same time, how can you ensure the implementation guarantees among every service and team?
We realized that the outbox pattern would help us meet those requirements: applications would publish events via an outbox table, which gets written to as part of business transactions in the database.
As with the strangler pattern, we wanted to resort to an architecture component, something the teams could self-service. At first, we were exploring a home-grown solution which would look for the outbox tables among every service and publish the messages. The problem with this approach would be the polling databases problem, although in this case this is less harmful as we don’t need to look for updates or deletes.
Luckily, by that time I was closely following the work being done in Debezium and I read the blogpost about reliable data exchange between microservices using the outbox pattern, and there was my answer! Well, I mean, parts of the answer, we still needed to implement it, and that’s a story for the next question!
Fast forward a couple of months and we got a reliable way to exchange messages between services, with all the guarantees we wanted to have, and by applying some platform DevOps flavor to it, we also made it self-service and easy to plug in every service!
The user can specify which database their service is at, what’s the table name, and which column to use as event router, you can find more details about it in the official Debezium outbox event router docs.
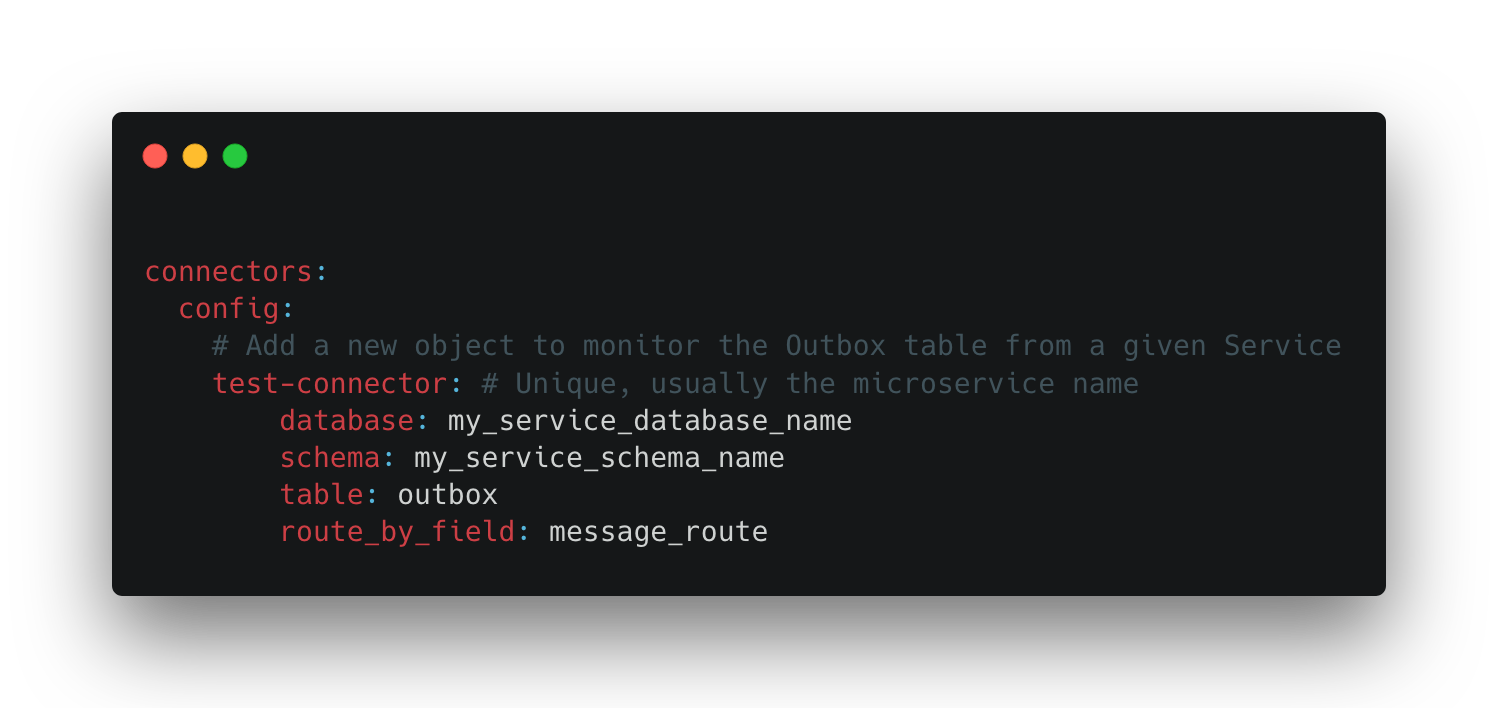
Figure 2. The configuration file for configuring outbox connectors
You’re not only using Debezium but you’ve also contributed to the project. How was your experience doing so? Are you doing other open-source work, too?
As I spoiled at the beginning, my usage and contributions to Debezium walked hand-to-hand. In both the use cases we have for Debezium in SurveyMonkey, I had great opportunities to contribute to both Debezium and Kafka (just a bug fix, but I’m happy about it!).
At first, I was fixing bugs in the Debezium MongoDB connector; as we really scaled it up to all the teams, a lot of edge cases started to show up, mostly in the transformation which takes the raw database transaction log and transforms it into a nicely readable Kafka Connect struct. Also due to our architecture choice, we split the raw log and transformed data into two different steps, which go in separate topics and are configured as separate Kafka Connect connectors.
Quick sidestep: the rationale behind this decision was to be able to survive transformation errors; MongoDB has a replication window which, if you lose it, means that you are going to have to make a new full snapshot of the collection and you might lose deletion events in this process. Because of this we opted for a safer approach, which was to split the logic of transformation from the raw logs like this: The step we call op (stands for operation), is the Debezium MongoDB source connector and outputs the raw data into the topic without any change or transformation, minimizing the chances of errors in the process. The second step called cdc, is a Salesforce Mirus source connector, which reads from the op output topic, transforms the message using the Debezium document flattening SMT and outputs to the final topic, which the services can consume from. With this approach, we now have two main abilities: Resist to errors and crashes on the native/custom transformation process like mentioned above, and we have the chance to change the transformation to our desires without having to read from the database again, giving us more flexibility. That also created some extra features and challenges to be incorporated in Debezium itself! As I kept contributing I noticed a few things that could be improved and started fixing them, including an almost full refactor of the build process of Debezium’s container images, its scripts, and other smaller things!
Let’s circle back to outbox; when the post about this appeared on the Debezium blog, it was mostly an idea and a proof-of-concept. But we really wanted it to run in production, in this case, why not partnership on it?
I want to take the opportunity here to mention how helpful the Debezium community was for getting me started with contributing. As I showed the intent to work on this, they were super welcoming and we had a call about it, so I quickly felt productive working on the code base.
Almost immediately after the conversation I started a technical draft (which you can see here) and soon thereafter, the first implementation was done. I can almost certainly say we were the first ones to run the transactional outbox pattern powered by Debezium. I was running a custom build on our platform, which then finally became the official outbox event router you see in the Debezium docs today. I was lucky to be there at the right time and with the right people, so thanks again to the Debezium team for helping me throughout the whole process of drafting and making it happen!
Will I do more open source? Yes, but I must say most of my open source activity is "selfish", I’m developing solutions to problems I face at work but I’m happy to take the extra step and make them to the OSS world, but it also makes it seasonal. One of the advantages to that is if I’m doing something for a project, be sure I’ll make it to production and likely be able to find more corner cases!
Is there anything you’re missing in Debezium or you’d like to see improved in the future?
When I think of the Kafka and Debezium ecosystem, the next steps I consider important are the ones which will make it more accessible. Although there’s a lot of content and examples online, there’s still a big gap between reading those and getting to a production ready implementation.
What I mean by that is abstracting the individual pieces away and giving them more meaning. The outbox pattern is a good example, it was not natural for people to think of CDC and know that it was such a good match to it, there are plenty of more use cases to be explored in this ecosystem.
What if you could have everything out-of-the-box? An outbox implementation in your favorite framework, which knows how to integrate with the ORM, handle the transaction part, then, how to shape the messages and events? How to adopt the schema for it and how an evolution of it looks like. After that, getting closer to the consumer implementation, how can I handle the messages idempotently, respect the semantics, do retries, and project them to a database if need be? There are already initiatives like those, for instance, the Quarkus Outbox extension, which takes care of framework and database integration. The future for me has those things, for multiple frameworks and tech stacks, going even broader and helping you design good events (maybe even powered by AsyncAPI), giving everyone a kickstart!
Those are very complex things to do in a growing architecture, the patterns will keep repeating and hopefully the community will be able to come to consensus of design and implementations, and that’s what I think the next step is, a place where the complexity of a good architecture doesn’t live in the wires and plugs anymore, making it more accessible!
Bonus question: What’s the next big thing in software engineering?
I think I handled clues for this one in many parts of my previous answers!
For me the next big thing is a methodology; I often say the evolution of DevOps is self-service, and it can go in many layers of the stack. The examples I gave about our Debezium implementation is what I call self-service between Platform/Ops and product development teams, but it can be applied in many, many places!
The idea is to facilitate the implementation of complex structures, something more end-to-end, taking care of the good practices in metrics, alerts, and diverse other guaranteed semantics for the use case! We can see there’s a convergence towards that path, for instance Kubernetes operators are a great example where you can abstract one use case which will be translated to many, if not dozens of internal resources in the infrastructure.
I believe we already have the base technology to do so, all the Infrastructure as Code, containers, frameworks, observability systems are there, we just have to give meaning to them!
Where’s the framework where I can: Handle a user request, validate, write to the source-of-truth, produce a message to my broker, consume at another end where my only concern is the payload itself? All the semantics should be taken care of, idempotency, retries, SerDes issues, dead letter queues, eventual consistency mitigations, metrics, alerts, SLOs, SLAs, etc!
And that’s where I put my energy in everyday at work, giving all the engineering teams a more fun and safe way to develop their software, which also sums up my passion for Platform Engineering!
Renato, thanks a lot for taking your time, it was a pleasure to have you here!
If you’d like to stay in touch with Renato Mefi and discuss with him, please drop a comment below or follow and reach out to him on Twitter.
Gunnar Morling
Gunnar is a software engineer and open-source enthusiast by heart, currently working as a Technologist at Confluent. Previously, he helped to build a realtime stream processing platform based on Apache Flink and led the Debezium project, a distributed platform for change data capture. He is a Java Champion and has founded multiple open source projects such as JfrUnit, kcctl, and MapStruct. Gunnar is an avid blogger (morling.dev) and has spoken at various conferences like QCon, Java One, and Devoxx. He lives in Hamburg, Germany.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.