
Kafka Streams is a library for developing stream processing applications based on Apache Kafka. Quoting its docs, "a Kafka Streams application processes record streams through a topology in real-time, processing data continuously, concurrently, and in a record-by-record manner". The Kafka Streams DSL provides a range of stream processing operations such as a map, filter, join, and aggregate.
Non-Key Joins in Kafka Streams
Debezium’s CDC source connectors make it easy to capture data changes in databases and push them towards sink systems such as Elasticsearch in near real-time. By default, this results in a 1:1 relationship between tables in the source database, the corresponding Kafka topics, and a representation of the data at the sink side, such as a search index in Elasticsearch.
In case of 1:n relationships, say between a table of customers and a table of addresses, consumers often are interested in a view of the data that is a single, nested data structure, e.g. a single Elasticsearch document representing a customer and all their addresses.
This is where KIP-213 ("Kafka Improvement Proposal") and its foreign key joining capabilities come in: it was introduced in Apache Kafka 2.4 "to close the gap between the semantics of KTables in streams and tables in relational databases". Before KIP-213, in order to join messages from two Debezium change event topics, you’d typically have to manually re-key at least one of the topics, so to make sure the same key is used on both sides of the join.
Thanks to KIP-213, this isn’t needed any longer, as it allows to join two Kafka topics on fields extracted from the Kafka message value, taking care of the required re-keying automatically, in a fully transparent way. Comparing to previous approaches, this drastically reduces the effort for creating aggregated events from Debezium’s CDC events.
Non-key joins or rather foreign-key joins are analogous to joins in SQL such as the following:
SELECT * FROM CUSTOMER JOIN ADDRESS ON CUSTOMER.ID = ADDRESS.CUSTOMER_IDIn Kafka Streams terms, the output of such join is a new KTable containing the join result.
Database Overview
Sticking to our earlier example of customers and address, let’s consider an application with the following data model:
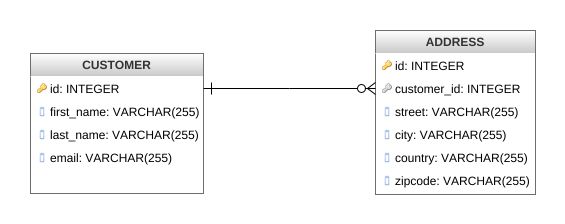
The two entities, customer and address, share a foreign key relationship from address to customer, i.e. a customer can have multiple addresses. As stated above, by default Debezium will emit events for each table on distinct topics. Using Kafka Streams, the change event topics for both tables will be loaded into two KTables, which are joined on the customer id. The Kafka Streams application is going to process data from the two Kafka topics. Whenever there’s a new CDC event on either topic — triggered by the insertion, update, or deletion of a record — the join will be re-executed.
As a runtime for the Kafka Streams application, we’re going to use Quarkus, a stack for building cloud-native microservices, which (amongst many others) also provides an extension for Kafka Streams. While it’s general possible to run a Kafka Streams topology via a plain main() method, using Quarkus and this extension as a foundation has a number of advantages:
-
Management of the topology (e.g. waiting for all input topics to be created)
-
Configurability via environment variables, system properties etc.
-
Exposing health checks
-
Exposing metrics
-
Dev Mode, a way of working on the stream topology with automatic hot code replacement after code changes
-
Support for executing the Kafka Streams pipeline as a native binary via GraalVM, resulting in a signficantly reduced memory consumption and start-up times
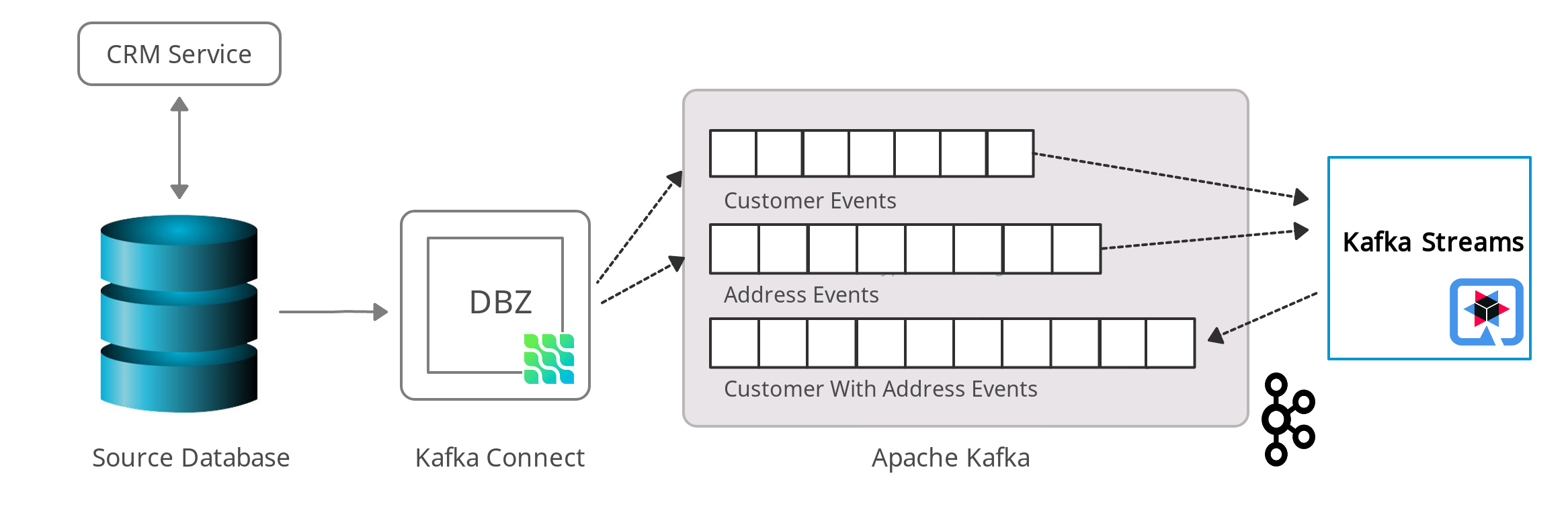
This picture shows an overview of our solution.
Creating an Application using the Quarkus Kafka Streams Extension
To create a new Quarkus project with the Kafka Streams extension, run the following:
mvn io.quarkus:quarkus-maven-plugin:1.12.2.Final:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=customer-addresses-aggregator \
-Dextensions="kafka-streams"
cd customer-addresses-aggregator Understanding the Stream Processing Topology
We have an aggregator application that will read from the two Kafka topics and process them in a streaming pipeline:
-
the two topics are joined on customer id
-
each customer is enriched with its addresses
-
this aggregated data is written out to a third topic,
customersWithAddressesTopic
When using the Quarkus extension for Kafka Streams, all we need to do for that is to declare a CDI producer method, which returns the topology of our stream processing application. This method must be annotated with @Produces, and it must return a Topology instance. The Quarkus extension is responsible for configuring, starting, and stopping the Kafka Streams engine. Now let’s take a look at the actual streaming query implementation itself.
@ApplicationScoped
public class TopologyProducer {
@ConfigProperty(name = "customers.topic") (1)
String customersTopic;
@ConfigProperty(name = "addresses.topic")
String addressesTopic;
@ConfigProperty(name = "customers.with.addresses.topic")
String customersWithAddressesTopic;
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder(); (2)
Serde<Long> adressKeySerde = DebeziumSerdes.payloadJson(Long.class);
adressKeySerde.configure(Collections.emptyMap(), true);
Serde<Address> addressSerde = DebeziumSerdes.payloadJson(Address.class);
addressSerde.configure(Collections.singletonMap("from.field", "after"), false);
Serde<Integer> customersKeySerde = DebeziumSerdes.payloadJson(Integer.class);
customersKeySerde.configure(Collections.emptyMap(), true);
Serde<Customer> customersSerde = DebeziumSerdes.payloadJson(Customer.class);
customersSerde.configure(Collections.singletonMap("from.field", "after"), false);
JsonbSerde<AddressAndCustomer> addressAndCustomerSerde =
new JsonbSerde<>(AddressAndCustomer.class); (3)
JsonbSerde<CustomerWithAddresses> customerWithAddressesSerde =
new JsonbSerde<>(CustomerWithAddresses.class);
KTable<Long, Address> addresses = builder.table( (4)
addressesTopic,
Consumed.with(adressKeySerde, addressSerde)
);
KTable<Integer, Customer> customers = builder.table(
customersTopic,
Consumed.with(customersKeySerde, customersSerde)
);
KTable<Integer, CustomerWithAddresses> customersWithAddresses = addresses.join( (5)
customers,
address -> address.customer_id,
AddressAndCustomer::new,
Materialized.with(Serdes.Long(), addressAndCustomerSerde)
)
.groupBy( (6)
(addressId, addressAndCustomer) -> KeyValue.pair(
addressAndCustomer.customer.id, addressAndCustomer),
Grouped.with(Serdes.Integer(), addressAndCustomerSerde)
)
.aggregate( (7)
CustomerWithAddresses::new,
(customerId, addressAndCustomer, aggregate) -> aggregate.addAddress(
addressAndCustomer),
(customerId, addressAndCustomer, aggregate) -> aggregate.removeAddress(
addressAndCustomer),
Materialized.with(Serdes.Integer(), customerWithAddressesSerde)
);
customersWithAddresses.toStream() (8)
.to(
customersWithAddressesTopic,
Produced.with(Serdes.Integer(), customerWithAddressesSerde)
);
return builder.build();
}
}| 1 | The topic names are injected using the MicroProfile Config API, with the values being provided in the Quarkus application.properties configuration file (they could be overridden using environment variables for instance) |
| 2 | Create an instance of StreamsBuilder, which helps us to build our topology |
| 3 | For serializing and deserializing Java types used in the streaming pipeline into/from JSON, Quarkus provides the class io.quarkus.kafka.client.serialization.JsonbSerde; The Serde implementation based is on JSON-B |
| 4 | The KTable-KTable foreign-key join functionality is used to extract the customer#id and perform the join; StreamsBuilder#table() is used to read the two Kafka topics into the KTable addresses and customers, respectively |
| 5 | The message from the addresses topic is joined with the corresponding customers topic; the join result contains the data of the customer with one of their addresses |
| 6 | groupBy() operation will have the records to be grouped by customer#id |
| 7 | To produce the nested structure of one customer and all their addresses, the aggregate() operation is applied to each group of records (customer-address tuples), updating a CustomerWithAddresses per customer |
| 8 | The results of the pipeline are written out to the customersWithAddressesTopic topic |
The CustomerWithAddresses class keeps track of the aggregated values while the events are processed in the streaming pipeline.
public class CustomerWithAddresses {
public Customer customer;
public List<Address> addresses = new ArrayList<>();
public CustomerWithAddresses addAddress(AddressAndCustomer addressAndCustomer) {
customer = addressAndCustomer.customer;
addresses.add(addressAndCustomer.address);
return this;
}
public CustomerWithAddresses removeAddress(AddressAndCustomer addressAndCustomer) {
Iterator<Address> it = addresses.iterator();
while (it.hasNext()) {
Address a = it.next();
if (a.id == addressAndCustomer.address.id) {
it.remove();
break;
}
}
return this;
}
}The Kafka Streams extension is configured via the Quarkus configuration file application.properties. Along with the topic names, this file also has the information about the Kafka bootstrap server and several streams options:
customers.topic=dbserver1.inventory.customers
addresses.topic=dbserver1.inventory.addresses
customers.with.addresses.topic=customers-with-addresses
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-id=kstreams-fkjoin-aggregator
quarkus.kafka-streams.application-server=${hostname}:8080
quarkus.kafka-streams.topics=${customers.topic},${addresses.topic}
# streams options
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUG
kafka-streams.consumer.session.timeout.ms=150
kafka-streams.consumer.heartbeat.interval.ms=100Building and Running the Application
You can now build the application like so:
mvn clean package
To run the application and all related components (Kafka, Kafka Connect with Debezium, a Postgres database), we’ve created a Docker Compose file, which you can find in the debezium-examples repo. To launch all the containers, also building the aggregator container image, run the the following:
export DEBEZIUM_VERSION=1.4 docker-compose up --build
To register the Debezium Connector with Kafka Connect, you need to specify the configuration properties like name of the connector, database hostname, user, password, port, name of the database, etc. Create a file register-postgres.json with the following contents:
{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname" : "postgres",
"database.server.name": "dbserver1",
"schema.include": "inventory",
"decimal.handling.mode" : "string",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false"
}Configure the Debezium Connector:
http PUT http://localhost:8083/connectors/inventory-connector/config < register-postgres.json
Now run an instance of the debezium/tooling container image:
docker run --tty --rm \
--network kstreams-fk-join-network \
debezium/tooling:1.1 \ This image provides several useful tools such as kafkacat. Within the tooling container, run kafkacat to examine the results of the streaming pipeline:
kafkacat -b kafka:9092 -C -o beginning -q \
-t customers-with-addresses | jq . You should see records like the following, each containing all the data of one customer and all their addresses:
{
"addresses": [
{
"city": "Hamburg",
"country": "Canada",
"customer_id": 1001,
"id": 100001,
"street": "42 Main Street",
"zipcode": "90210"
},
{
"city": "Berlin",
"country": "Canada",
"customer_id": 1001,
"id": 100002,
"street": "11 Post Dr.",
"zipcode": "90211"
}
],
"customer": {
"email": "sally.thomas@acme.com",
"first_name": "Sally",
"id": 1001,
"last_name": "Thomas"
}
}Get a shell for the database, insert, update, or delete some records, and the join will be reprocessed automatically:
$ docker run --tty --rm -i \
--network kstreams-fk-join-network \
debezium/tooling:1.1 \
bash -c 'pgcli postgresql://postgres:postgres@postgres:5432/postgres'
# in pgcli, e.g. to update a customer record:
> update inventory.customers set first_name = 'Sarah' where id = 1001;Running Natively
Kafka Streams applications can easily be scaled out i.e. the load is going to be shared amongst multiple instances of the application, each processing a sub-set of the partitions of the input topics. When the Quarkus application gets compiled into native code via GraalVM, it takes considerably less memory and has a very fast start-up time. Without any concern about the memory management, you can start multiple instances of a Kafka Streams pipeline in parallel.
If you want to run this application in native mode, set the QUARKUS_MODE as native and run the following (make sure to have the required GraalVM tooling installed):
mvn clean package -Pnative
To learn more about running Kafka Streams applications as a native binary, please refer to the reference guide.
More Insights on the Kafka Streams Extension
The Quarkus extension can also help you address some of the common requirements when building microservices for stream processing. For running your Kafka Streams application in production, you can for instance easily add health checks and metrics for the data pipeline.
Micrometer Metrics provides rich metrics about your Quarkus application, i.e. what is happening inside your application by monitoring and what are its performance characteristics. Quarkus lets you expose these metrics via HTTP using a JSON format or the OpenMetrics format. From there, they can be scraped by tools such as Prometheus and stored for analysis and visualization.
Once the application is started, the metrics will be exposed under q/metrics, returning the data in the OpenMetrics format by default:
# HELP kafka_producer_node_request_total The total number of requests sent
# TYPE kafka_producer_node_request_total counter
kafka_producer_node_request_total{client_id="kstreams-fkjoin-aggregator-b4ac1384-0e0a-4f19-8d52-8cc1ee4c6dfe-StreamThread-1-producer",kafka_version="2.5.0",node_id="node--1",status="up",} 83.0
# HELP kafka_producer_record_send_rate The average number of records sent per second.
# TYPE kafka_producer_record_send_rate gauge
kafka_producer_record_send_rate{client_id="kstreams-fkjoin-aggregator-b4ac1384-0e0a-4f19-8d52-8cc1ee4c6dfe-StreamThread-1-producer",kafka_version="2.5.0",status="up",} 0.0
# HELP jvm_gc_memory_allocated_bytes_total Incremented for an increase in the size of the (young) heap memory pool after one GC to before the next
# TYPE jvm_gc_memory_allocated_bytes_total counter
jvm_gc_memory_allocated_bytes_total 1.1534336E8
# ...
# HELP http_requests_total
# TYPE http_requests_total counter
http_requests_total{status="up",uri="/api/customers",} 0.0
# ...If you aren’t using Prometheus, you have a few options like Datadog, Stackdriver, and others. For a detailed guide check the Quarkiverse Extensions.
On the other hand, we have MicroProfile Health spec, which provides information about the liveness of the application, i.e. signalling whether your application is running or not and whether your application is able to process requests. To monitor the health status of your existing Quarkus application you can add the smallrye-health extension:
mvn quarkus:add-extension -Dextensions="smallrye-health"
Quarkus will expose all health checks via HTTP under q/health, which in our case shows the status of the pipeline and any missing topics:
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams topics health check",
"status": "DOWN",
"data": {
"missing_topics": "dbserver1.inventory.customers,dbserver1.inventory.addresses"
}
}
]
}Summary
The Quarkus extension for Kafka Streams comes with everything needed to run stream processing pipelines on the JVM as well as in native mode, along with additional bonuses of performing health checks, metrics, and more. For instance you could quite easily expose REST APIs for interactive queries using the Quarkus REST support, potentially retrieving data from other instances of scaled out Kafka Streams app using the MicroProfile REST client API.
In this article we have discussed a stream processing topology of foreign key joins in Kafka Streams, and how to use the Quarkus Kafka Streams extension for running and building your application in JVM mode. You can find the complete source code of the implementation in the Debezium examples repo. If you got any questions or feedback, please let us know in the comments below. We’re looking forward to your suggestions!
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.