
Welcome to the latest edition of "Debezium Community Stories With…", a series of interviews with members of the Debezium and change data capture community, such as users, contributors or integrators. Today it’s my pleasure to talk to Sergei Morozov.

Sergei, could you introduce yourself? What is your job, if you’re not contributing to Debezium?
Hi, my name is Sergei, I’m a Software Architect at SugarCRM. Most of my career, I’ve been building software based on the LAMP stack. A few years ago, my team and I started building a data streaming platform meant to integrate the existing SugarCRM products and the new services we wanted to build on top of them. We started prototyping the platform with Maxwell’s Daemon, AWS Kinesis and DynamoDB and later switched to Kafka, Kafka Connect and Debezium.
Interestingly, Debezium was the reason why we started experimenting with the Kafka ecosystem. The solution we had built before the pivot was only capable of streaming CDC changes but not snapshotting the initial state. During the work on snapshotting, we stumbled upon Debezium and discovered Kafka. After some experimentation and learning more about the ecosystem, we decided to switch the technology stack.
What are your use cases for Debezium and change data capture in your current project?
We capture data changes from the products based on MySQL and SQL Server and use them to enable AI and data analytics use cases. Apart from processing recent changes, we store as much historical data as possible. The data comes from thousands of customer databases hosted in the cloud environment.
We use it for AI, analytics, and enabling future use cases. For instance, SugarPredict provides scoring of opportunities and helps sales representatives to focus on those that are more likely to close. The historical data from the CRM and other sources is used to train the AI models. The data change events are used to run the scoring process and update the prediction.
From the data flow perspective, it looks very simple but there are quite some engineering challenges caused by the flexibility of the products and the cloud scale.
This sounds really interesting; can you tell us more about the challenges you encountered and how you solved them?
Absolutely. Let me dive into the details a bit. I hope our ideas and solutions will be helpful to the community.
Flexibility and Data Serialization
The products that provide data changes are extremely customizable. Customers can create new modules, fields, install extensions, etc. which from the CDC standpoint means that the customers have full control over the database schema. Combined with the scale of thousands of customers, it makes it challenging to use Apache Avro which implies that the schema is managed by the developers.
A couple of years ago, we tested the then de-facto standard Schema Registry and concluded that it wouldn’t perform well at the scale of roughly a million message schemas we’d have in the cloud, not even counting schema versions the number of which is unbounded. For comparison, the accompanying managed offering for that schema registry allows to store up to a thousand schemas. So we resorted to using JSON to serialize data.
Onboarding Challenges
SugarCloud is a multi-tenant hosting environment for SugarCRM products. It consists of a few dozens of large MySQL-compatible AWS Aurora clusters that usually host a hundred to a thousand customer databases each. The cluster storage size varies from a few hundred gigabytes to 5 terabytes.
When a Debezium connector for MySQL first starts, it performs the initial consistent snapshot, and to guarantee the consistency, it usually obtains a short-lived global read lock for capturing the schema of all relevant tables. Since AWS Aurora doesn’t allow to perform a global lock, Debezium has to lock all tables individually for the entire duration of the snapshot.
The snapshot of a database cluster would take from a few hours to a couple of days which we cannot afford because it would require downtime of all the customer instances hosted on a given cluster. Fortunately, we stumbled upon the great article Debezium MySQL Snapshot For AWS RDS Aurora From Backup Snaphot by The Data Guy that describes a workaround that allowed us to snapshot all the data without causing any application downtime. We implemented a shell script that clones the database cluster, records the position in the binlog from which the clone was made, takes a snapshot of the clone and then reconfigures the connector to stream from the position of the snapshot.
Instance Lifecycle Management
SugarCloud is a very dynamic environment. Once a customer database has been deployed to one of the clusters, there’s no guarantee that it will remain there during its entire lifetime. A database can be backed up and restored. It can be moved between clusters in the same AWS region for load-balancing purposes. It can be moved from one AWS region to another if requested by the customer.
Our source connectors are configured to capture all data changes from all databases on a given cluster but not all of them make sense from the data consumers' standpoint. For instance, when a database is restored from a backup on a different cluster, the INSERT statements generated by mysqldump don’t represent new rows. They represent the state of the database during the backup and should be ignored.
In order to enable post-processing of the raw data, there is a system database on each of the clusters where the cluster management system logs all events relevant to the instance lifecycle (see the outbox pattern).
In order to post-process the raw data according to the lifecycle events, we built a Kafka Streams application that is deployed between Debezium and the actual data consumers. Internally, it uses a state store which is effectively a projection of each customer database status (active/maintenance). Prior to restoring a database from a SQL dump, the database is marked as "in maintenance" (an event is emitted to outbox), so all corresponding INSERTs are ignored until the maintenance is over (another event emitted).
Storage
The need to store all historical data brings the challenge of having enough storage. Since the end of last year, we’ve collected more than 120TB of compressed CDC events. Currently we store historical data in S3 but plan to move it back to Kafka once S3-backed tiered storage (KIP-405) is available in AWS MSK.
Infrastructure
We run our software primarily in Kubernetes and manage all of our Kafka-related infrastructure other than brokers themselves with Strimzi. Strimzi not only allows to manage applications and Kafka resources using the same tools, it also provides a great foundation for automation.
When we started designing the data streaming platform, one of the requirements was that it should automatically adjust to certain changes in SugarCloud. For instance, when a new Aurora cluster is deployed, the data streaming pipeline should be deployed for this cluster. Another requirement was that the pipeline should be deployed in multiple AWS regions and be managed via Sugar’s single control plane, codenamed Mothership. We went one level deeper and built the Mothership Operator that serves as the API for managing the pipeline.
When a new Aurora cluster is created, Mothership creates a secret in Vault with the database credentials and a StackIngestor. The StackIngestor contains the information about the Aurora cluster: its AWS region, MySQL endpoint, the name of the Vault secret and other technical information. Mothership Operator subscribes to the changes in StackIngestors and manages the Kafka resources that implement the pipeline.
With some exceptions, each pipeline is deployed to the same AWS region where the Aurora cluster is located. There are Strimzi Topic and Cluster operators deployed in each region. The pipeline consists of a few Kafka topics, a source connector (Debezium), a sink connector (S3) and runs on a shared or a dedicated Kafka Connect cluster. For each StackIngestor created in the primary region, Mothership Operator creates the needed Strimzi resources in the regional Kubernetes cluster. The Strimzi operators subscribe to the updates in their resources and manages the corresponding resources in Kafka.
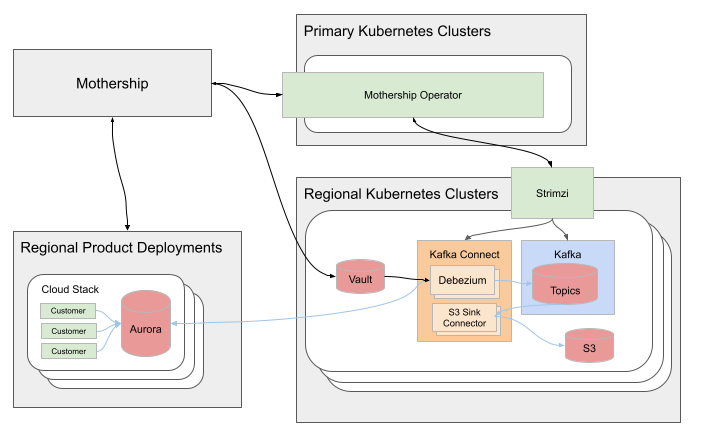
Figure 1. System Overview
We also use Strimzi to export JMX metrics from Debezium to Prometheus. The Prometheus metrics are visualized in Grafana. We started with a community dashboard (also by The Data Guy) and improved it o better fit the multi-tenant use case.
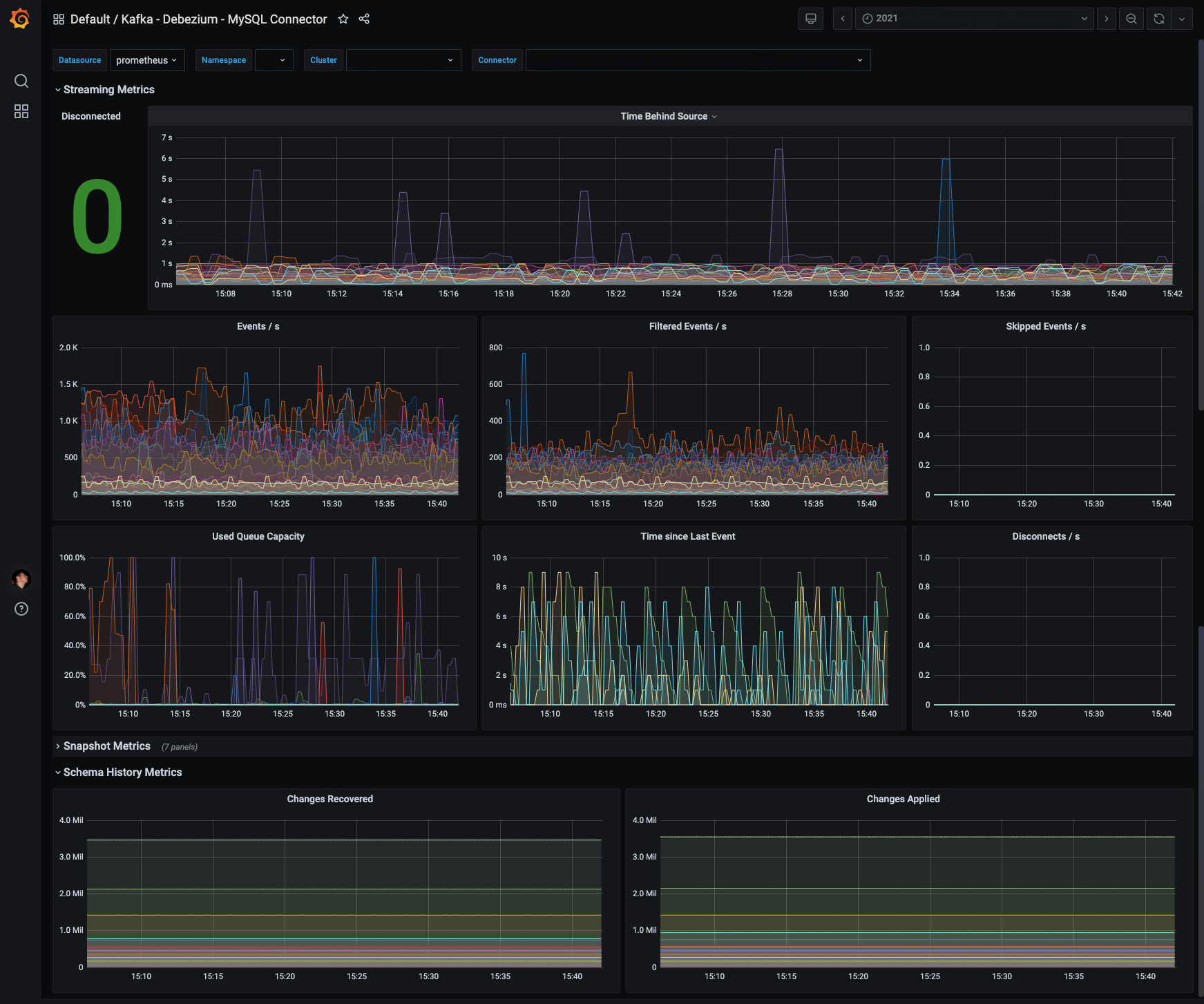
Figure 2. Multi-Tenant Debezium Dashboard
You’re not only using Debezium but you’ve also contributed to the project. How was your experience doing so?
In my experience, whatever open-source software I touch – be it at work or for fun – I always end up finding something about that software that needs to be improved to enable my use case.
I contributed one of my first patches to Debezium (or, more precisely, to its dependency mysql-binlog-connector-java) back in October 2020. We had just rolled out one of our first connectors to production and had experienced an issue where the connector was consuming all available memory and crashing at a specific position in the binlog. The issue was quite pressing since we had a very limited time before the binlog compaction would kick in and we might start losing data. At the same time, we had just a basic understanding of the Debezium and Kafka Connect architecture and no experience with the Debezium internals.
The whole team had swarmed in and figured out that the connector was misinterpreting a non-standard binlog event that AWS Aurora produced instead of ignoring it. Troubleshooting and finding the root cause was the hardest part. Getting the issue fixed and unit-tested was relatively easy. Although the change wasn’t that obvious, I’m glad it was accepted promptly with constructive feedback from the team.
Are you doing other open-source work, too?
I’m one of the maintainers of the most popular library for relational databases in PHP, Doctrine DBAL. I made my first contributions there while I was working on integrating the library into the core SugarCRM product and fixed some issues that blocked the integration. It took a few releases to get everything fixed, and at the end I got invited to the core team.
Apart from that, I’ve been an occasional contributor to some open-source projects in the PHP ecosystem: primarily those that I would use daily like PHPBrew, PHPUnit, PHP_CodeSniffer, Vimeo Psalm and PHP itself.
Is there anything which you’re missing in Debezium or which you’d like to see improved in the future?
While Debezium is a great tool that covers most of the industry-standard database platforms, one the greatest challenges for our team was and still is scaling Debezium to the size of our customer base. The SQL Server connector is currently capable of handling only one logical database per connector. We have hundreds of customer databases hosted on SQL Server, but running a dedicated connector for each of them would require expensive infrastructure and would be hard to manage.
Earlier this year, we started working with the Debezium team on improving the connector and making it capable of capturing changes from multiple databases and running multiple tasks. This way, instead of running hundreds of connectors, we could run a dozen or so. The original design is outlined in DDD-1.
With these changes implemented, one of our production connectors captures changes from over a hundred databases. At the same time, we’re working on contributing the changes back upstream.
Bonus question: What’s the next big thing in data engineering?
Nowadays, especially in multi-tenant environments, it’s really hard to predict how much time it will take from "it works on my machine" to "it works at the cloud scale". I’m looking forward to the time when container orchestration and data streaming platforms become as simple to operate as they look on PowerPoint diagrams.
Sergei, thanks a lot for taking your time, it was a pleasure to have you here!
If you’d like to stay in touch with Sergei Morozov and discuss with him, please drop a comment below or follow and reach out to him on Twitter.
Gunnar Morling
Gunnar is a software engineer and open-source enthusiast by heart, currently working as a Technologist at Confluent. Previously, he helped to build a realtime stream processing platform based on Apache Flink and led the Debezium project, a distributed platform for change data capture. He is a Java Champion and has founded multiple open source projects such as JfrUnit, kcctl, and MapStruct. Gunnar is an avid blogger (morling.dev) and has spoken at various conferences like QCon, Java One, and Devoxx. He lives in Hamburg, Germany.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.