
At ScyllaDB, we develop a high-performance NoSQL database Scylla, API-compatible with Apache Cassandra, Amazon DynamoDB and Redis. Earlier this year, we introduced support for Change Data Capture in Scylla 4.3. This new feature seemed like a perfect match for integration with the Apache Kafka ecosystem, so we developed the Scylla CDC Source Connector using the Debezium framework. In this blogpost we will cover the basic structure of Scylla’s CDC, reasons we chose the Debezium framework and design decisions we made.
CDC support in Scylla
Change Data Capture (CDC) allows users to track data modifications in their Scylla database. It can be easily enabled/disabled on any Scylla table. Upon turning it on, a log of all modifications (INSERTs, UPDATEs, DELETEs) will be created and automatically updated.
When we designed our implementation of CDC in Scylla, we wanted to make it easy to consume the CDC log. Therefore, the CDC log is stored as a regular Scylla table, accessible by any existing CQL driver. When a modification is made to a table with CDC enabled, information about that operation is saved to the CDC log table.
Here’s a quick demo of it: First, we will create a table with CDC enabled:
CREATE TABLE ks.orders(
user text,
order_id int,
order_name text,
PRIMARY KEY(user, order_id)
) WITH cdc = {'enabled': true};Next, let’s perform some operations:
INSERT INTO ks.orders(user, order_id, order_name)
VALUES ('Tim', 1, 'apple');
INSERT INTO ks.orders(user, order_id, order_name)
VALUES ('Alice', 2, 'blueberries');
UPDATE ks.orders
SET order_name = 'pineapple'
WHERE user = 'Tim' AND order_id = 1;Finally, let’s see the contents of the modified table:
SELECT * FROM ks.orders;
user | order_id | order_name
------+----------+-------------
Tim | 1 | pineapple
Alice | 2 | blueberriesLooking only at this table, you cannot reconstruct all modifications that took place, e.g. Tim’s order name before the UPDATE. Let’s look at the CDC log, easily accessible as a table (some columns truncated for clarity):
SELECT * FROM ks.orders_scylla_cdc_log;
cdc$stream_id | cdc$time | | cdc$operation | order_id | order_name | user
---------------+----------+-...-+---------------+----------+-------------+----------
0x2e46a... | 7604... | ... | 2 | 1 | apple | Tim
0x2e46a... | 8fdc... | ... | 1 | 1 | pineapple | Tim
0x41400... | 808e... | ... | 2 | 2 | blueberries | AliceAll three operations are visible in the CDC log. There are two INSERTs (cdc$operation = 2) and one UPDATE (cdc$operation = 1). For each operation, its timestamp is also preserved in cdc$time column. The timestamp is encoded as a time-based UUID value as specified by the RFC 4122 specification, which can be decoded using helper methods in Scylla drivers.
Choosing Debezium
As shown in the previous section, Scylla CDC can be easily queried as a regular table. To get the latest operations in real-time, you poll the table with appropriate time ranges. To make this easier, we developed client libraries for Java and Go.
When we thought about how our customers could access the CDC log, using it with Kafka seemed like the most accessible method. Therefore, we decided to develop a source connector for Scylla CDC.
For our first proof-of-concept, we implemented the source connector using the Kafka Connect API. This prototype was crucial for us to determine if the connector could scale horizontally (described later in this blogpost).
However, we quickly realized that by using only the Kafka Connect API, we would have to reimplement a lot of functionality already present in other connectors. We also wanted our connector to be a good citizen in the Kafka community, sticking to the best practices and conventions. That’s exactly why we choose Debezium!
Thanks to this, when you start the Scylla CDC Source Connector, the configuration parameters will be immediately familiar, as many of them are common with other Debezium connectors. The generated data change events have the same Envelope structure as generated by other Debezium connectors. This similarity allows for the use of many standard Debezium features, such as New Record State Extraction.
Event representation
After we decided to use the Debezium framework, we looked at how Scylla CDC operations should be represented in Debezium’s Envelope format.
The Envelope format consists of the following fields:
-
op- type of operation:cfor create,ufor update,dfor delete andrfor read -
before- state of row before an event occured -
after- state of row after an event occurred -
source- metadata of the event -
ts_ms- time the connector processed the event
Mapping Scylla operations to the op field was fairly easy: c for INSERT, u for UPDATE, d for DELETE.
We decided to skip DELETE events that span multiple rows, such as range DELETEs:
DELETE FROM ks.table
WHERE pk = 1 AND ck > 0 AND ck < 5Representing such operations would unnecessarily complicate the format in order to accommodate additional range information. Moreover, it would break the expectation that an Envelope represents a modification to a single row.
In Scylla CDC, range DELETEs are represented as two rows in the CDC table: the first row encodes the information about the start of the deleted range (in the example above: pk = 1, ck > 0) and the second row encodes the end of the deleted range (in the example above: pk = 1, ck < 5). An information about each of the rows present in that range is not persisted. This corresponds to a fact that DELETEs in Scylla generate a tombstone in the database.
By default, Scylla’s CDC stores the primary key and only the modified columns of an operation. For example, suppose I created a table and inserted a row:
CREATE TABLE ks.example(
pk int,
v1 int,
v2 int,
v3 int,
PRIMARY KEY(pk)) WITH cdc = {'enabled': true};
INSERT INTO ks.example(pk, v1, v2, v3)
VALUES (1, 2, 3, 4);In Scylla you can issue another INSERT statement, which will override some of the columns:
INSERT INTO ks.example(pk, v1, v3)
VALUES (1, 20, null);The v2 column is left unchanged after this query and we don’t have any information about its previous value.
We must be able to represent three possibilities: a column was not modified, a column was assigned a NULL value or a column was assigned a non-null value. The representation we chose was inspired by Debezium Connector for Cassandra, which works by wrapping the value for a column in a structure:
"v1": {"value": 1},
"v2": null,
"v3": {"value": null}A null structure value represents that a column was not modified (v2 field). If the column was assigned a NULL value (v3 field), there will be a structure with a NULL value field. A non-null column assignment (v1 field) fills the contents of the value field. Such a format allows us to correctly represent all the possibilities and differentiate between assigning NULL and non-modification.
However, most sink connectors won’t be able to correctly parse such a structure. Therefore, we decided to develop our own SMT, based on Debezium’s New Record State Extraction SMT. Our ScyllaExtractNewState SMT works by applying Debezium’s New Record State Extraction and flattening the {"value": …} structures (at the expense of not being able to distinguish NULL value and missing column value):
"v1": 1,
"v2": null,
"v3": nullScylla’s CDC also supports recording pre-images and post-images with every operation (at an additional cost). We plan to add support for them in the future versions of the Scylla CDC Source Connector.
Horizontal scaling
Even at a stage of proof-of-concept, great performance was a paramount requirement. Scylla databases can scale to hundreds of nodes and PBs of data, so it became clear that a single Kafka Connect worker node (even multithreaded) could not handle the load of a big Scylla cluster.
Thankfully, we took that into consideration while implementing CDC functionality in Scylla. Generally, you can think of Change Data Capture as a time-ordered queue of changes. To allow for horizontal scaling, Scylla maintains a set of multiple time-ordered queues of changes, called streams. When there is only a single consumer of the CDC log, it has to query all streams to properly read all changes. A benefit of this design is that you can introduce additional consumers, assigning a disjunct set of streams to each one of them. As a result, you can greatly increase the parallelism of processing the CDC log.
That’s the approach we implemented in the Scylla CDC Source Connector. When starting, the connector first reads the identifiers of all available streams. Next, it distributes them among many Kafka Connect tasks (configurable by tasks.max).
Each created Kafka Connect task (that can run on a separate Kafka Connect node) reads CDC changes from its assigned set of streams. If you double the number of tasks, each task will have to read only a half of the number of streams - half of data throughput, making it possible to handle a higher load.
Solving large stream count problem
While designing CDC functionality in Scylla, we had to carefully pick the number of streams that would be created. If we chose too few streams, a consumer could possibly not keep up with the data throughput of a single stream. That could also slow down INSERT, UPDATE, DELETE operations, because many concurrent operations would fight for access to a single stream. However, if Scylla created too many streams, the consumers would have to issue a large number of queries to Scylla (to cover each stream), causing unnecessary load.
The current implementation of CDC in Scylla creates number_of_nodes * number_of_vnodes_per_node * number_of_shards streams per cluster. The number of VNodes refers to the fact that Scylla uses a Ring architecture, which has 256 VNodes per node by default. Each Scylla node consists of several independent shards, which contain their share of the node’s total data. Typically, there is one shard per each hyperthread or physical core.
For example, if you create a 4-node i3.metal (72 vCPU per node) Scylla cluster, which is capable of roughly 600k operations per second (half INSERTs, half SELECTs), that would be: 4 * 256 * 72 = 73728 streams.
We quickly realised that this many streams could be a problem in bigger clusters:
-
Too many queries to Scylla - one query per each stream
-
Too many Kafka Connect offsets - one offset per each stream. Storing offsets means the connector can resume from the last saved position after a crash.
To mitigate those problems, we made a decision to group streams on the client side. We chose to group the streams by VNode. This reduced the count from number_of_nodes * number_of_vnodes_per_node * number_of_shards to number_of_nodes * number_of_vnodes_per_node. In the case of 4-node i3.metal that means a reduction from 73728 to 1024: only 1024 queries to Scylla and 1024 offsets stored on Kafka.
However, we were still uneasy about the number of offsets to be stored on Kafka. When we looked into other connectors, most of them stored only a single offset or at most tens of offsets per replicated table (and as an effect having a limited scalability).
To understand why storing thousands of streams on Kafka Connect could be a problem, let’s look at how it works under the hood. Each Kafka Connect record created by a source connector contains a key/value offset, for example: key - my_table; offset - 25, which could represent that the connector finished reading 25 rows in my_table. Periodically (configured by offset.flush.interval.ms), those offsets are flushed to a Kafka topic called connect-offsets, as regular Kafka messages.
Unfortunately, Kafka is not a key/value store. When a connector starts up, it must scan all messages on the connect-offsets topic to find the one it needs. When it updates a previously saved offset, it just appends the new value to this topic without deleting the previous entry. It’s not a problem with connectors that have only a single offset - when updated every minute, this topic would hold roughly 10,000 messages after a week. However, in the case of the Scylla CDC Source Connector this number could be several orders of magnitude larger!
Fortunately, this issue can be easily mitigated by setting a more aggressive compaction configuration on the connect-offsets topic. With the default configuration of retention.ms of 7 days and segment.bytes of 1GB, this topic could grow up to several hundred megabytes after just a few hours (with a Scylla cluster with tens of nodes and very small offset.flush.interval.ms). This made the connector startup time slower, as it had to scan the entire offset topic after a start/restart. By tuning the segment.bytes, segment.ms or cleanup.policy, retention.ms we were able to mitigate the problem and significantly reduce the connect-offsets topic size. The first two options specify the frequency of the log compaction process. When a segment is compacted, all messages with the same key are reduced to the latest one (the latest offset). Alternatively, setting a shorter retention time (but one that is larger than Scylla’s CDC retention time) proved to be a good option to reduce the offset topic size.
Benchmarks: near linear scaling
To verify that our connector can actually scale horizontally, we performed a benchmark to measure the maximum throughput of Scylla CDC Source Connector on increasingly larger Kafka Connect clusters.
First, we started a single-node i3.4xlarge Scylla cluster (based on the official Scylla AMI). Next, we inserted 50 million rows (total size 5.33GB) to a CDC-enabled table. Later, we started an Apache Kafka 2.6.0 cluster and Kafka Connect cluster on either 1, 3 or 5 nodes (r5n.2xlarge). We started the Scylla CDC Source Connector to consume data from the previously populated CDC-enabled table and measured the time it took to produce all 50 million Kafka messages.
Our connector was able to scale the throughput near linearly:
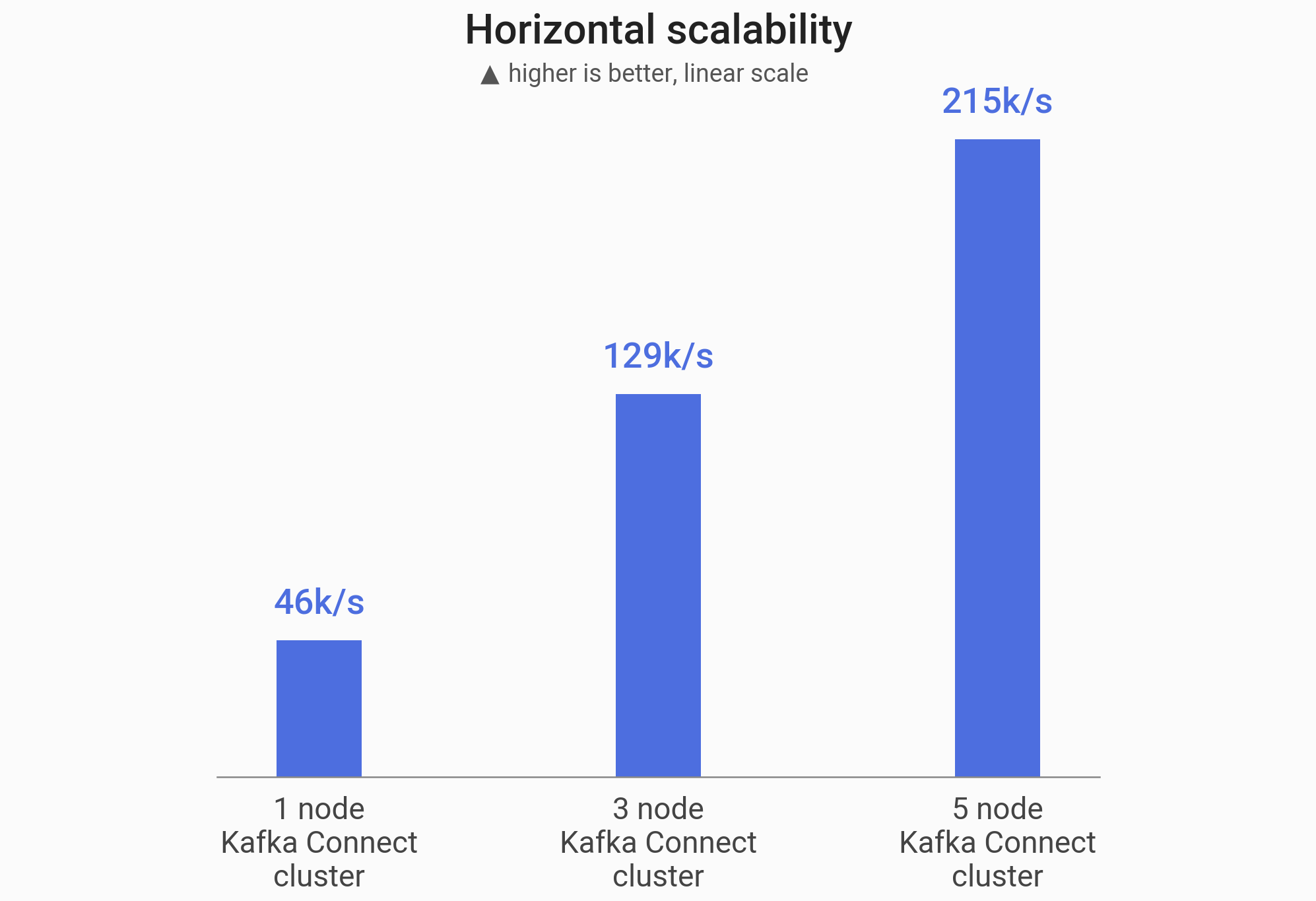
| Kafka cluster size | Throughput | Speedup |
|---|---|---|
1 node | 46k/s | 1x |
3 nodes | 129k/s | 2.8x |
5 nodes | 215k/s | 4.7x |
Conclusion
In this blog post, we took a deep dive into the development of Scylla CDC Source Connector. We started with an overview of CDC implementation in Scylla. We have discussed the reasons we chose Debezium rather than just Kafka Connect API to build our connector, in turn making it familiar to users and Kafka-idiomatic. Next, we looked at two problems we encountered: how to represent Scylla changes and make the connector scalable.
We are very excited to continue improving our connector even further with additional features and making it even more performant. We are eagerly looking forward to watching the Debezium ecosystem grow and integrating functionalities introduced in the latest versions of Debezium.
If you want to check out the connector yourself, the GitHub repository with its source code is available here: github.com/scylladb/scylla-cdc-source-connector. You can learn more about Scylla here: scylladb.com.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.