
Today, it is a common practise to build data lakes for analytics, reporting or machine learning needs.
In this blog post we will describe a simple way to build a data lake. The solution is using a realtime data pipeline based on Debezium, supporting ACID transactions, SQL updates and is highly scalable. And it’s not required to have Apache Kafka or Apache Spark applications to build the data feed, reducing complexity of the overall solution.
Let’s start with a short description of the data lake concept: A data lake is "usually a central store of data including raw copies of source system data, sensor data, social data etc". You can store your data as-is, without having to first process the data and then run different types of analytics.
Debezium Server Iceberg
As operational data typically resides in a relational database or a NoSQL data store, the question is how the data can be propagated into the data lake. This is where the Debezium Server Iceberg project comes in: Based on Debezium and Apache Iceberg, it lets you process realtime data change events from a source database and upload them to any object storage supported by Iceberg. So let’s take a closer look at these two projects.
Debezium is an open source distributed platform for change data capture. Debezium extracts change events from a database’s transaction log and delivers them to consumers via event streaming platforms, using different formats such as JSON, Apache Avro, Google Protocol Buffers and others. Most of the time, Debezium is used with Apache Kafka and Kafka Connect. But via Debezium Server, also users of other messaging infrastructure like Kinesis, Google Pub/Sub, Pulsar can benefit from Debezium’s change data capture capabilities. Here you can see the currently supported destinations.
Apache Iceberg is an "open table format for huge analytic datasets. Iceberg adds tables to compute engines including Spark, Trino, PrestoDB, Flink and Hive, using a high-performance table format which works just like a SQL table." It supports ACID inserts as well as row-level deletes and updates. It provides a Java API to manage table metadata, like schemas and partition specs, as well as data files that store table data.
Apache Iceberg has a notion of data and delete files. Data files are the files Iceberg uses behind the scene to keep actual data. Delete files are the immutable files to encode rows that are deleted in existing data files. This is how Iceberg deletes/replaces individual rows in immutable data files without rewriting the files. In the case of Debezium Server Iceberg, these are immutable Apache Parquet files, a format which is designed as an "efficient as well as performant flat columnar storage format of data compared to row based files like CSV or TSV files".
The Apache Iceberg Consumer
Debezium Server provides an SPI to implement new sink adapters, and this is the extension point used for creating the Apache Iceberg consumer.
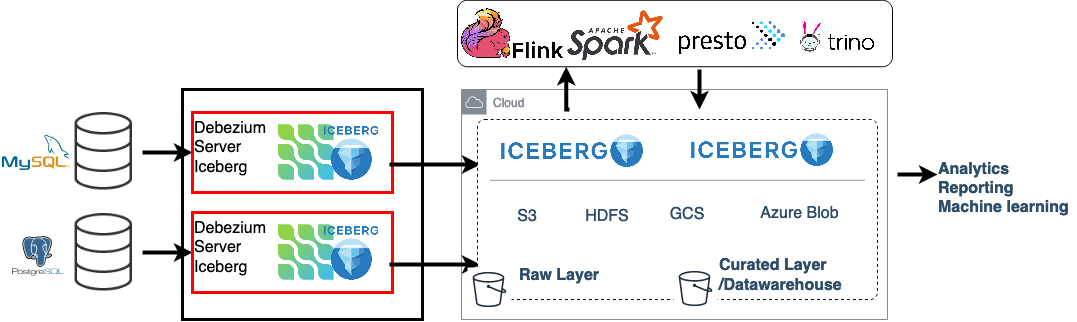
Figure 1. Architecture Overview: Debezium Server and Apache Iceberg
The Iceberg consumer converts CDC change events to Iceberg data files and commits them to a destination table using the Iceberg Java API. It maps each Debezium source topic to a destination Iceberg table.
When a given Iceberg destination table is not found, the consumer creates it using the change event schema. Additionally, the event schema is used to map the change event itself to an equivalent Iceberg record. Because of this, the debezium.format.value.schemas.enable configuration option must be set. Once the Debezium change event has been recorded into an Iceberg record, the schema is removed from the data.
On a high level, change events processed as follows. For each received batch of events:
-
The events are grouped per destination Iceberg table; each group contains list of a change events coming from a single source table, sharing the same data schema
-
For each destination, events are converted to Iceberg records
-
The Iceberg records are saved as Iceberg data and delete files (delete files are created only if the consumer is running with upsert mode)
-
The files are committed to the destination Iceberg table (i.e. uploaded to the destination storage)
-
The processed change events marked as processed with Debezium
Here is a complete example configuration for using Debezium Server with the Iceberg adaptor:
debezium.sink.type=iceberg
# run with append mode
debezium.sink.iceberg.upsert=false
debezium.sink.iceberg.upsert-keep-deletes=true
debezium.sink.iceberg.table-prefix=debeziumcdc_
debezium.sink.iceberg.table-namespace=debeziumevents
debezium.sink.iceberg.fs.defaultFS=s3a://S3_BUCKET);
debezium.sink.iceberg.warehouse=s3a://S3_BUCKET/iceberg_warehouse
debezium.sink.iceberg.type=hadoop
debezium.sink.iceberg.catalog-name=mycatalog
debezium.sink.iceberg.catalog-impl=org.apache.iceberg.hadoop.HadoopCatalog
# enable event schemas
debezium.format.value.schemas.enable=true
debezium.format.value=json
# complex nested data types are not supported, do event flattening. unwrap message!
debezium.transforms=unwrap
debezium.transforms.unwrap.type=io.debezium.transforms.ExtractNewRecordState
debezium.transforms.unwrap.add.fields=op,table,source.ts_ms,db
debezium.transforms.unwrap.delete.handling.mode=rewrite
debezium.transforms.unwrap.drop.tombstones=trueUpsert and Append Modes
By default, the Iceberg consumer is running in upsert mode (debezium.sink.iceberg.upsert set to true). This means that when a row is updated in the source table, the destination is row replaced with the new updated version. And when a row is deleted from the source, it also is deleted from the destination. When using upsert mode, data at the destination is kept identical to the source data. The upsert mode uses the Iceberg equality delete feature and creates delete files using the key of the Debezium change data events (derived from the primary key of the source table). To avoid duplicate data, deduplication is done on each batch and only the last version of the record kept. For example in a single batch of events, the same record could appear twice: once when it is inserted, and another time when it gets updated. With upsert mode, always the last extracted version of the record is stored in Iceberg.
Note that when a source table doesn’t define a primary key and there is also no key information available by other means (e.g. a unique key or a custom message key defined in Debezium), the consumer uses the append mode for this table (see below).
Keeping Deleted Records With Upsert Mode
For some use cases it is useful to keep deleted records as a soft delete. This is possible by setting the debezium.sink.iceberg.upsert-keep-deletes option to true. This setting will keep the latest version of deleted records in the destination Iceberg table. Setting it to false will remove deleted records from the destination table.
Append Mode
This is the most straightforward operation mode, enabled by setting debezium.sink.iceberg.upsert to false. When using Debezium Server Iceberg with append mode, all received records are appended to the destination table. No data deduplication or deletion of records is done. With append mode it is possible to analyze entire change history of a record.
| It also is possible to consume realtime events and do data compaction afterwards with a separate compaction job. Iceberg supports compacting data and metadata files to increase performance. |
Optimizing Batch Sizes
Debezium extracts and delivers database events in real time, and this could cause too frequent commits to the tables in Iceberg, generating too many small files. This is not optimal for batch processing, especially when a near-realtime data feed is sufficient. To avoid this problem, it is possible to increase the batch size per commit.
When enabling the MaxBatchSizeWait mode, the Iceberg consumer uses Debezium metrics to optimize the batch size. It periodically retrieves the current size of Debezium’s internal event queue and waits until it has reached max.batch.size. During the wait time, Debezium events are collected in memory (in Debezium’s internal queue). That way, each commit (set of events processed) processes more records and consistent batch size. The maximum wait and check interval are controlled via the debezium.sink.batch.batch-size-wait.max-wait-ms and debezium.sink.batch.batch-size-wait.wait-interval-ms properties. These settings should be configured together with Debezium’s debezium.source.max.queue.size and debezium.source.max.batch.size properties.
Here’s an example for all the related settings:
debezium.sink.batch.batch-size-wait=MaxBatchSizeWait
debezium.sink.batch.batch-size-wait.max-wait-ms=60000
debezium.sink.batch.batch-size-wait.wait-interval-ms=10000
debezium.sink.batch.metrics.snapshot-mbean=debezium.postgres:type=connector-metrics,context=snapshot,server=testc
debezium.sink.batch.metrics.streaming-mbean=debezium.postgres:type=connector-metrics,context=streaming,server=testc
# increase max.batch.size to receive large number of events per batch
debezium.source.max.batch.size=50000
debezium.source.max.queue.size=400000Creating Additional Data Lake Layers
At this point, the raw layer of the data lake has been loaded, including data deduplication and near realtime pipeline features. Building curated layers on top (sometimes called analytics layer or data warehouse layer) becomes very straightforward and simple. At the analytics layer, raw data is prepared to meet the analytics requirement; usually raw data is reorganized, cleaned, versioned (see example below), aggregated, and business logic may be applied. Using SQL through scalable processing engines is the most common way of doing this kind of data transformation.
For example, someone could easily use Spark SQL(or PrestoDB, Trino, Flink, etc) to load a slowly changing dimension, the most commonly used data warehouse table type:
MERGE INTO dwh.consumers t
USING (
-- new data to insert
SELECT customer_id, name, effective_date, to_date('9999-12-31', 'yyyy-MM-dd') as end_date
FROM debezium.consumers
UNION ALL
-- update exiting records. close end_date
SELECT t.customer_id, t.name, t.effective_date, s.effective_date as end_date
FROM debezium.consumers s
INNER JOIN dwh.consumers t on s.customer_id = t.customer_id AND t.current = true
) s
ON s.customer_id = t.customer_id AND s.effective_date = t.effective_date
-- close last records/versions.
WHEN MATCHED
THEN UPDATE SET t.current = false, t.end_date = s.end_date
-- insert new versions and new data
WHEN NOT MATCHED THEN
INSERT(customer_id, name, current, effective_date, end_date)
VALUES(s.customer_id, s.name, true, s.effective_date, s.end_date);Additional data lake layers may need to be updated periodically with new data. The easiest way of doing this is using SQL update or delete statements. These SQL operations are also supported by Iceberg:
INSERT INTO prod.db.table SELECT ...;
DELETE FROM prod.db.table WHERE ts >= '2020-05-01 00:00:00' and ts < '2020-06-01 00:00:00';
DELETE FROM prod.db.orders AS t1 WHERE EXISTS (SELECT order_id FROM prod.db.returned_orders WHERE t1.order_id = order_id;
UPDATE prod.db.all_events
SET session_time = 0, ignored = true
WHERE session_time < (SELECT min(session_time) FROM prod.db.good_events));Wrap-Up and Contributions
Based on Debezium and Apache Iceberg, Debezium Server Iceberg makes it very simple to set up a low-latency data ingestion pipeline for your data lake. The project completely open-source, using the Apache 2.0 license. Debezium Server Iceberg still is a young project and there are things to improve. Please feel free to test it, give feedback, open feature requests or send pull requests. You can see more examples and start experimenting with Iceberg and Spark using this project.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.