
In this post, we are going to talk about a CDC-CQRS pipeline between a normalized relational database, MySQL, as the command database and a de-normalized NoSQL database, MongoDB, as the query database resulting in the creation of DDD Aggregates via Debezium & Kafka-Streams.
You can find the complete source code of the example here. Refer to the README.md for details on building and running the example code.
The example is centered around three microservices: order-write-service, order-aggregation-service and order-read-service. These services are implemented as Spring-Boot applications in Java.
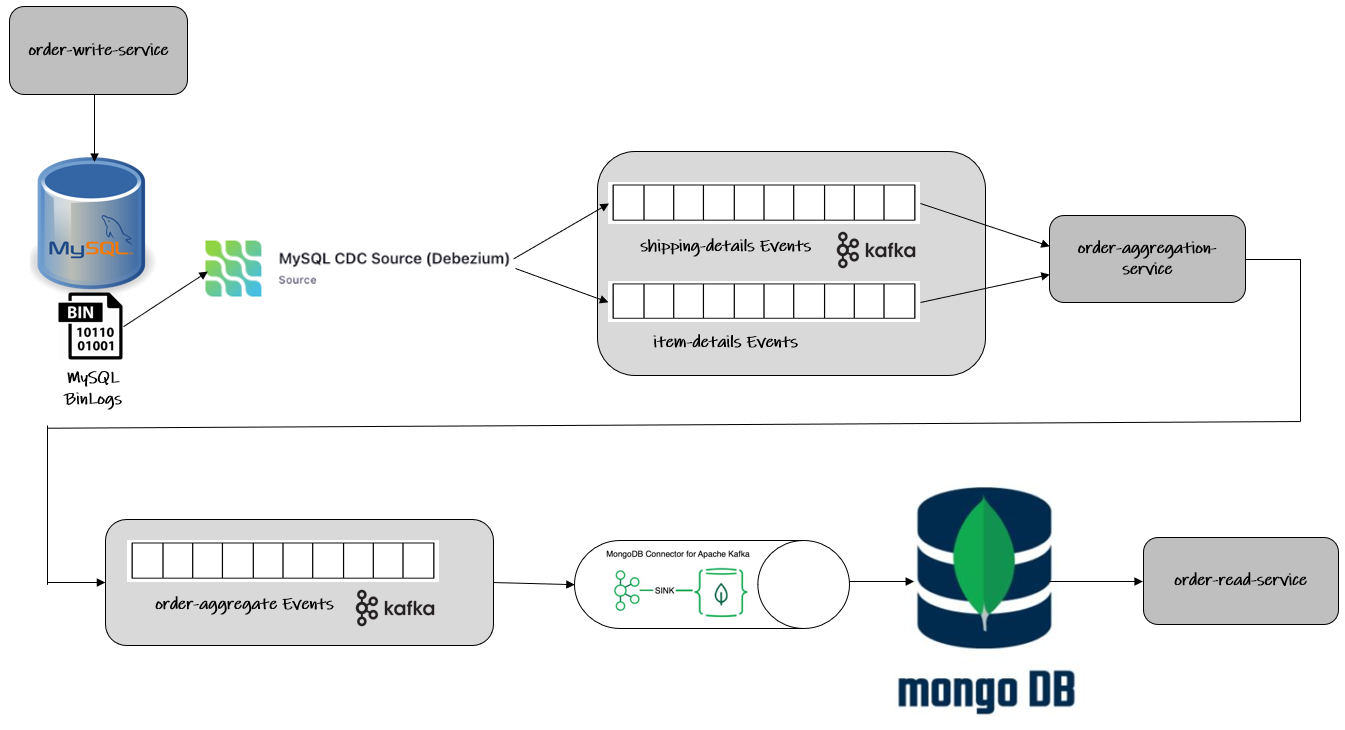
The order-write-service exposes two REST endpoints which persist shipping-details and item-details in their respective tables on MySQL database. Debezium tails the MySQL bin logs to capture any events in both these tables and publishes messages to Kafka topics. These topics are consumed by order-aggregation-service which is a Kafka-Streams application that joins data from both of these topics to create an Order-Aggregate object which is then published to a third topic. This topic is consumed by MongoDB Sink Connector and the data is persisted in MongoDB which is served by order-read-service.
The overall architecture of the solution can be seen in the following diagram:
REST Application: order-write-service
The first component that triggers the workflow starts is the order-write-service. This has been implemented as a Spring-Boot application and exposes two REST end-points:
-
POST:
api/shipping-detailsto persist shipping details in the MySQL database -
POST:
api/item-detailsto persist item details in the MySQL database
Both of these endpoints persist their data in their respective tables in the MySQL database.
Command Database: MySQL
The backend processing of the above-mentioned REST endpoints culminates in persisting the data in their respective tables in MySQL.
Shipping details are stored in a table called SHIPPING_DETAILS. And Item details are stored in a table called ITEM_DETAILS.
Here is the data-model of SHIPPING_DETAILS table, the column ORDER_ID is its primary key:

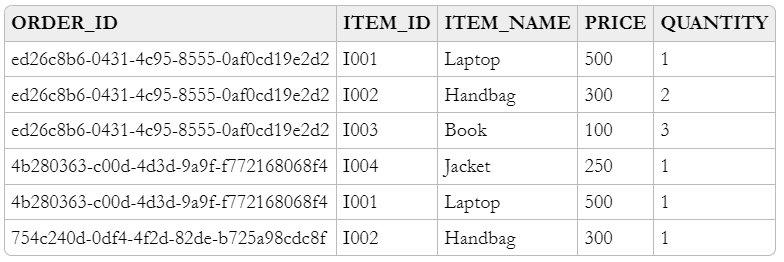
Here is the data-model of ITEM_DETAILS table, the column ORDER_ID + ITEM_ID is its primary key:
Kafka-Connect Source Connector: MySQL CDC Debezium
Change Data Capture (CDC) is a solution that captures change events from a database transaction log (called BinLogs in the case of MySQL) and forwards those events to downstream consumers ex. Kafka topic.
Debezium is a platform that provides a low latency data streaming platform for change data capture (CDC) and is built on top of Apache Kafka. It allows database row-level changes to be captured as events and published to Apache Kafka topics. We setup and configure Debezium to monitor our databases, and then our applications consume events for each row-level change made to the database.
In our case, we will be using Debezium MySQL Source connector to capture any new events in the aforementioned tables and relay them to Apache Kafka. To achieve this, we will be registering our connecter by POST-ing the following JSON request to the REST API of Kafka Connect:
{
"name": "app-mysql-db-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql_db_server",
"database.port": "3306",
"database.user": "custom_mysql_user",
"database.password": "custom_mysql_user_password",
"database.server.id": "184054",
"database.server.name": "app-mysql-server",
"database.whitelist": "app-mysql-db",
"table.whitelist": "app-mysql-db.shipping_details,app-mysql-db.item_details",
"database.history.kafka.bootstrap.servers": "kafka_server:29092",
"database.history.kafka.topic": "dbhistory.app-mysql-db",
"include.schema.changes": "true",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
}
}| The above configuration is based on Debezium 1.9.5.Final. Be aware that if you attempt to use the demo with Debezium 2.0+, a number of the above configuration properties have new names and the configuration will require some adjustments. |
This sets up an instance of io.debezium.connector.mysql.MySqlConnector, capturing changes from the specified MySQL instance. Note that by means of a table include list, only changes from the SHIPPING_DETAILS and ITEM_DETAILS tables are captured. It also applies a single message transform (SMT) named ExtractNewRecordState which extracts the after field from a Debezium change event in a Kafka record. The SMT replaces the original change event with only its after field to create a simple Kafka record.
By default, the Kafka topic name is “serverName.schemaName.tableName” which as per our connector configuration translates to:
-
app-mysql-server.app-mysql-db.item_details -
app-mysql-server.app-mysql-db.shipping_details
Kafka-Streams Application: order-aggregation-service
The Kafka-Streams application, namely order-aggregation-service, is going to process data from the two Kafka cdc-topics. These topics receive CDC events based on the shipping-details and item-details relations found in MySQL.
With that in place, the KStreams topology to create and maintain DDD order-aggregates on-the-fly can be built as follows.
The application reads the data from the shipping-details-cdc-topic. Since the Kafka topic records are in Debezium JSON format with unwrapped envelopes we need to parse the order-id and the shipping-details from it to create a KTable with order-id as the key and shipping-details as the value.
// Shipping Details Read
KStream<String, String> shippingDetailsSourceInputKStream = streamsBuilder.stream(shippingDetailsTopicName, Consumed.with(STRING_SERDE, STRING_SERDE));
// Change the Json value of the message to ShippingDetailsDto
KStream<String, ShippingDetailsDto> shippingDetailsDtoWithKeyAsOrderIdKStream = shippingDetailsSourceInputKStream
.map((orderIdJson, shippingDetailsJson) -> new KeyValue<>(parseOrderId(orderIdJson), parseShippingDetails(shippingDetailsJson)));
// Convert KStream to KTable
KTable<String, ShippingDetailsDto> shippingDetailsDtoWithKeyAsOrderIdKTable = shippingDetailsDtoWithKeyAsOrderIdKStream.toTable(
Materialized.<String, ShippingDetailsDto, KeyValueStore<Bytes, byte[]>>as(SHIPPING_DETAILS_DTO_STATE_STORE).withKeySerde(STRING_SERDE).withValueSerde(SHIPPING_DETAILS_DTO_SERDE));Similarly, the application reads the data from the item-details-cdc-topic and parses the order-id and the item from each individual message to group-by all the items pertaining to the same order-id in one list which is then aggregated to a KTable with order-id as key and the list of items pertaining to that specific order-id as value.
// Item Details Read
KStream<String, String> itemDetailsSourceInputKStream = streamsBuilder.stream(itemDetailsTopicName, Consumed.with(STRING_SERDE, STRING_SERDE));
// Change the Key of the message from ItemId + OrderId to only OrderId and parse the Json value to ItemDto
KStream<String, ItemDto> itemDtoWithKeyAsOrderIdKStream = itemDetailsSourceInputKStream
.map((itemIdOrderIdJson, itemDetailsJson) -> new KeyValue<>(parseOrderId(itemIdOrderIdJson), parseItemDetails(itemDetailsJson)));
// Group all the ItemDtos for each OrderId
KGroupedStream<String, ItemDto> itemDtoWithKeyAsOrderIdKGroupedStream = itemDtoWithKeyAsOrderIdKStream.groupByKey(Grouped.with(STRING_SERDE, ITEM_DTO_SERDE));
// Aggregate all the ItemDtos pertaining to each OrderId in a list
KTable<String, ArrayList<ItemDto>> itemDtoListWithKeyAsOrderIdKTable = itemDtoWithKeyAsOrderIdKGroupedStream.aggregate(
(Initializer<ArrayList<ItemDto>>) ArrayList::new,
(orderId, itemDto, itemDtoList) -> addItemToList(itemDtoList, itemDto),
Materialized.<String, ArrayList<ItemDto>, KeyValueStore<Bytes, byte[]>>as(ITEM_DTO_STATE_STORE).withKeySerde(STRING_SERDE).withValueSerde(ITEM_DTO_ARRAYLIST_SERDE));With both the KTables having order-id as the key, it’s easy enough to join them using order-id to create an aggregate called Order-Aggregate. Order-Aggregate is a composite object created by assimilating data from both the shipping-details as well as the item-details. This Order-Aggregate is then written to an order-aggregate Kafka topic.
// Joining the two tables: shippingDetailsDtoWithKeyAsOrderIdKTable and itemDtoListWithKeyAsOrderIdKTable
ValueJoiner<ShippingDetailsDto, ArrayList<ItemDto>, OrderAggregate> shippingDetailsAndItemListJoiner = (shippingDetailsDto, itemDtoList) -> instantiateOrderAggregate(shippingDetailsDto, itemDtoList);
KTable<String, OrderAggregate> orderAggregateKTable = shippingDetailsDtoWithKeyAsOrderIdKTable.join(itemDtoListWithKeyAsOrderIdKTable, shippingDetailsAndItemListJoiner);
// Outputting to Kafka Topic
orderAggregateKTable.toStream().to(orderAggregateTopicName, Produced.with(STRING_SERDE, ORDER_AGGREGATE_SERDE));Kafka-Connect Sink Connector: MongoDB Connector
The sink connector is a Kafka Connect connector that reads data from Apache Kafka and writes data to some data-store. Using a MongoDB sink connector, it is easy to have the DDD aggregates written into MongoDB. All it needs is a configuration which can be posted to the REST API of Kafka Connect in order to run the connector.
{
"name": "app-mongo-sink-connector",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"topics": "order_aggregate",
"connection.uri": "mongodb://root_mongo_user:root_mongo_user_password@mongodb_server:27017",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"database": "order_db",
"collection": "order",
"document.id.strategy.overwrite.existing": "true",
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy",
"transforms": "hk,hv",
"transforms.hk.type": "org.apache.kafka.connect.transforms.HoistField$Key",
"transforms.hk.field": "_id",
"transforms.hv.type": "org.apache.kafka.connect.transforms.HoistField$Value",
"transforms.hv.field": "order"
}
}Query Database: MongoDB
The DDD aggregate is written to the database order_db in the collection order on MongoDB. The order-id becomes the _id of the table and the order column stores the order-aggregate as JSON.
REST Application: order-read-service
The Order Aggregate persisted in MongoDB is served via a REST endpoint in order-read-service.
-
GET:
api/order/{order-id}to retrieve the order from the MongoDB database
Execution Instructions
The complete source code for this blog post is provided here in Github. Begin by cloning this repository and changing into the cdc-cqrs-pipeline directory. The project provides a Docker Compose file with services for all the components:
-
MySQL
-
Adminer (formerly known as phpMinAdmin), to manage MySQL via browser
-
MongoDB
-
Mongo Express, to manage MongoDB via browser
-
Zookeeper
-
Confluent Kafka
-
Kafka Connect
Once all services have started, register an instance of the Debezium MySQL connector & MongoDB Connector by executing the Create-MySQL-Debezium-Connector and Create-MongoDB-Sink-Connector request respectively from cdc-cqrs-pipeline.postman_collection.json. Execute the request Get-All-Connectors to verify that the connectors have been properly created.
Change into the individual directories and spin-up the three Spring-Boot applications:
-
order-write-service: runs on port no8070 -
order-aggregation-service: runs on port no8071 -
order-read-service: runs on port no8072
With this, our setup is complete.
To test the application, execute the request Post-Shipping-Details from the postman collection to insert shipping-details and Post-Item-Details to insert item-details for a particular order id.
Finally, execute the Get-Order-By-Order-Id request in the postman collection to retrieve the complete Order Aggregate.
Summary
Apache Kafka acts as a highly scalable and reliable backbone for the messaging amongst the services. Putting Apache Kafka into the center of the overall architecture also ensures a decoupling of involved services. If for instance single components of the solution fail or are not available for some time, events will simply be processed later on: after a restart, the Debezium connector will continue to tail the relevant tables from the point where it left off before. Similarly, any consumer will continue to process topics from its previous offset. By keeping track of already successfully processed messages, duplicates can be detected and excluded from repeated handling.
Naturally, such event pipeline between different services is eventually consistent, i.e. consumers such as the order-read-service may lag a bit behind producers such as the order-write-service. Usually, that’s just fine, though, and can be handled in terms of the application’s business logic. Also, end-to-end delays of the overall solution are typically low (seconds or even sub-second range), thanks to log-based change data capture which allows for emission of events in near-realtime.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.