
The team has been quite busy these last couple months preparing for a condensed release timeline for Debezium 2.3, and I am thrilled to announce that the next installment has arrived, Debezium 2.3.0.Final is now available!
Despite a condensed release schedule, this release is packed with tons of new features and improvements. Debezium 2.3 includes a brand-new notification subsystem, a rewrite of the signal subsystem to support additional means to send signals to Debezium connectors, the introduction of the JDBC storage module to maintain Debezium state in relational databases, parallelization of Vitess shard processing, PostgreSQL connector replica identity improvements, a brand-new Debezium Server operator for Kubernetes, support for exactly-once semantics for the PostgreSQL connector, and improvements to the Oracle connector.
Let’s take a few moments and talk about any breaking changes and all these improvements and why they’re so important!
You can also find a full list of changes in Debezium 2.3’s release notes.
Breaking changes
We generally attempt to avoid as many breaking changes across minor releases as possible, but unfortunately sometimes such changes are inevitable, particularly if a feature may have been introduced as experimental. Debezium 2.3 introduces two breaking changes depending on whether you are upgrading from a preview release or an earlier stable version:
PostgreSQL / MySQL secure connection changes
Debezium for PostgreSQL and MySQL can be configured to use a secured SSL connection. For PostgreSQL, this can be done by configuring database.sslmode while for MySQL this can be done with database.ssl.mode.
With Debezium 2.3, this configuration option no longer defaults to disable (PostgreSQL) or disabled (MySQL) but instead defaults to prefer (PostgreSQL) and preferred (MySQL). This means that when attempting to connect using an encrypted, secure connection is unavailable, the connector will fallback to using an unsecured connection by default unless configured otherwise.
JDBC storage encoding changes
Debezium 2.3.0.alpha1 introduced the new experimental JDBC storage module. This storage module defaulted to using UTF-16 as it’s default encoding; however, most databases prefer UTF-8 as a default. If you are upgrading from Debezium 2.3.0.Alpha1, Debezium 2.3.0.Beta1 and later now use UTF-8 when storing data using the JDBC storage module to align with typical database defaults.
New features and improvements
Debezium 2.3 includes a plethora of new features improvements, which include the following:
Debezium Server Operator for Kubernetes
This release introduces a preview version of the new Debezium Operator, providing the ability to deploy and manage Debezium Server instances within Kubernetes. Debezium Server allows you to stream change events from your data sources to a wide variety of messaging infrastructures. Our goal is to provide a Kafka-less alternative for the Debezium community who wish to utilize Kubernetes for scalability and high availability deployments.
Presently, the documentation is sparse as the operator is in early incubation stages; however, we do intend to improve upon this in upcoming release cycles. You can find a deployment example and basic description of the custom resource specification in the github repository that you can use as a reference for the short-term.
We do not recommend a production deployment of this component at this time; however, we encourage users to provide community feedback. The feedback will be valuable in evaluating if the component is feature ready or if there are still areas of improvement to meet everyone’s needs.
New notification subsystem
Debezium 2.3 introduces a brand-new feature called notifications, allowing Debezium to emit events that can be consumed by any external system to know the status of various stages of Debezium’s lifecycle.
Notification events are represented as a series of key/value tuples, with a structure that contains several out-of-the-box fields. The following is an example of a simple notification event.
{
"id": "c485ccc3-16ff-47cc-b4e8-b56a57c3bad2",
"aggregate_type": "Snapshot",
"type": "Started",
"additional_data": {
...
}
}Each notification event consists of an id field, a UUID to identify the notification, an aggregate_type field to which the notification is related based on the concept of domain-driven design, a type field that is mean to given more detail about the aggregate type itself, and an optional additional_data field which consists of a map of string-based key/value pairs with additional information about the event.
At this time, there are two notification event types supported by Debezium:
-
Status of the initial snapshot
-
Monitoring of the incremental snapshot
Initial Snapshot Notifications
An initial snapshot is the consistent capture of the existing data when a connector first starts. An initial snapshot event will have an aggregate type with the value of "Initial Snapshot" and the type of event will consist of one of three logical values:
SKIPPED-
Represents the initial snapshot was skipped.
ABORTED-
Represents the initial snapshot was aborted.
COMPLETED-
Represents the initial snapshot has concluded successfully.
The following is an example of a notification about the completion of the initial snapshot:
{
"id": "5563ae14-49f8-4579-9641-c1bbc2d76f99",
"aggregate_type": "Initial Snapshot",
"type": "COMPLETED"
}Incremental Snapshot Notifications
An incremental snapshot is a capture of the existing data from a configured set of tables while the connector is actively streaming changes. An incremental snapshot event will have an aggregate type with the value of "Incremental Snapshot" and the type will consist of one of several logical values:
STARTED-
Indicates an incremental snapshot has started.
PAUSED-
Indicates an incremental snapshot has been temporarily paused.
RESUMED-
Indicates an incremental snapshot that had been paused has now resumed.
STOPPED-
Indicates an incremental snapshot has stopped.
IN_PROGRESS-
Indicates an incremental snapshot is in-progress.
TABLE_SCAN_COMPLETED-
Indicates an incremental snapshot has concluded for a given table.
COMPLETED-
Indicates that an incremental snapshot has concluded for all tables.
Configuring Notifications
Debezium notifications are configured via the connector’s configuration. The following examples show how to configure the out-of-the-box Kafka Topic or Log based channels.
{
"notification.enable.channels": "sink",
"notification.sink.topic.name": "debezium_notifications",
...
}{
"notification.enable.channels": "log"
}New extensible signal subsystem
Debezium has supported the concept of a signal since the introduction of the Incremental Snapshot feature well back in Debezium 1.x. Signals are important as it allows you to provide metadata to instruct Debezium to perform a given task, whether that task is to write an entry to the connector log or perform an ad-hoc incremental snapshot.
In Debezium 2.3, the signal subsystem was reworked to introduce the concept called channel, which represents a medium for which Debezium watches or listens and reacts to signals. In previous versions, there was one channel supported universally across connectors, which was the database signal table. In this release, these channels have been unified and the following are available out of the box:
-
Database signal table
-
Kafka signal topic
-
Filesystem
-
JMX
But that’s not all, the signal channel contract is extensible, allowing you to write a custom implementation and make that available to your connectors with ease.
JMX signals and notifications integration
Debezium 2.3 previously introduced both a new signal channel and notification feature. This feature allows external applications to easily integrate with Debezium, sending signals to perform various tasks such as ad-hoc incremental snapshots, and to receive notifications about the progress of such tasks. This release builds on top of that functionality to allow the ability to send signals and receive notifications via JMX.
Sending signals
In this release, the signal channel subsystem has been improved to support sending signals via JMX. From the jconsole window, you can now see there are two new subsections for a connector, a notifications and signal section shown below:
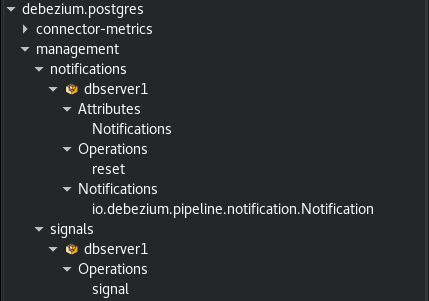
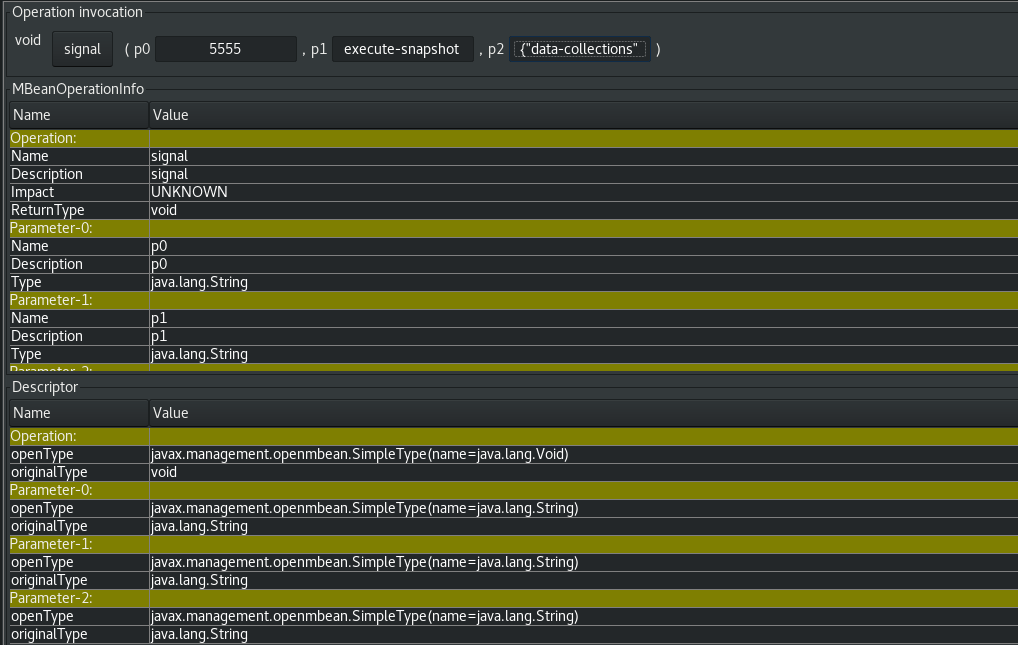
The new signals section allows you to invoke an operation on the JMX bean in order to transmit a signal to Debezium. This signal resembles the logical signal table structure where it accepts 3 parameters, a unique identifier, the signal type, and finally the signal payload. The following illustrates what this looks like from jconsole:
Receiving notifications
The new notifications section allows you to receive and react to notifications captured by the JMX bean from Debezium. The Debezium JMX bean will buffer all notifications to ensure that no notification is missed. The following illustrates what this looks like from jconsole:
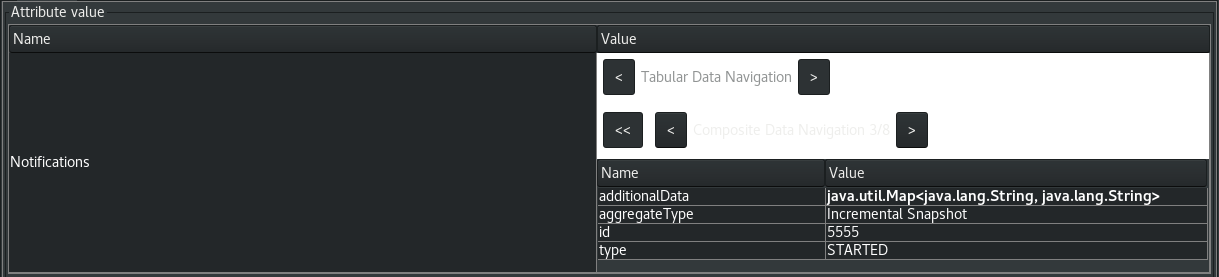
| The JMX bean does not automatically clear the notification queue. In order to avoid memory concerns, be sure to invoke the |
We look forward to your feedback on this new way to integrate signals and notifications with Debezium over JMX.
New JDBC storage subsystem
Debezium 2.3 introduces a new storage module implementation supporting the persistence of schema history and offset data in a datastore via JDBC. For environments where you may not have easy access to persistent filesystems, this offers yet another alternative for storage via a remote, persistent storage platform.
In order to take advantage of this new module, the following dependency must be added to your project or application:
<dependency>
<groupId>io.debezium</groupId>
<artifactId>debezium-storage-jdbc</artifactId>
<version>2.3.0.Final</version>
</dependency>The following examples show how to configure Offset or Schema History storage via the JDBC storage module:
{
"offset.storage.jdbc.url": "<jdbc-connection-url>",
"offset.storage.jdbc.user": "dbuser",
"offset.storage.jdbc.password": "secret",
"offset.storage.jdbc.offset_table_name": "debezium_offset_storage"
}{
"schema.history.internal.jdbc.url": "<jdbc-connection-url>",
"schema.history.internal.jdbc.user": "dbuser",
"schema.history.internal.jdbc.password": "secret",
"schema.history.internal.jdbc.schema.history.table.name": "debezium_database_history"
}Exactly once delivery for PostgreSQL streaming
Debezium has traditionally been an at-least-once delivery solution, guaranteeing that no change is ever missed. Exactly-Once is a proposal by the Apache Kafka community as a part of KIP-618. This proposal aims to address a common problem with producers (source connectors) when a producer retries, it may re-send a batch of events to the Kafka broker even if that batch had already been committed by the broker. This means there are situations where duplicate events may be sent and not every consumer (sink connector) may be capable of handling such situations easily.
Debezium plans to roll out exactly-once delivery semantics in a phased style. There are specific corner cases around snapshotting and streaming and these can vary by connector. And with that, Debezium 2.3 starts out by specifically only adding support for exactly-once semantics for the PostgreSQL during its streaming phase only!
In order to take advantage of exactly-once delivery, there is no connector configuration changes required; however, your Kafka Connect worker configuration will need to be adjusted to enable this feature. You can find a reference to the new configuration properties in KIP-618.
| If you are mixing connectors on the same connect cluster that do and do not support exactly once delivery, you will not be able to set |
PostgreSQL replica identity changes
Debezium 2.3 introduces a new PostgreSQL connector feature called "Autoset Replica Identity".
Replica identity is PostgreSQL’s way to identify what columns are captured in the database transaction logs for inserts, updates, and deletes. This new feature allows configuring a table’s replica identity via connector configuration and delegating the responsibility of setting this configuration to the connector at start-up.
The new configuration option, replica.identity.autoset.values, specifies a comma-separated list of table and replica identity tuples. If the table already has a given replica identity, the identity will be overwritten to match what is specified in this configuration if the table is included. PostgreSQL supports several replica identity types, more information on these can be found in the documentation.
When specifying the replica.identity.autoset.values, the value is a comma-separated list of values where each element uses the format of <fully-qualified-table-name>:<replica-identity>. An example is shown below where two tables are configured to have full replica identity:
{
"replica.identity.autoset.values": "public.table1:FULL,public.table2:FULL"
}Oracle RAC improvements
When connecting to an Oracle RAC installation, you must specify a rac.nodes configuration property with a minimum of the host or IP address of all individual nodes across the cluster. Older versions of the connector also supported a varied format, allowing the inclusion of a port for each node as not every node on the cluster may use the same port.
Debezium 2.3 improves the Oracle RAC support by also acknowledging that each node may not necessarily use the same Oracle Site Identifier (SID), and therefore, the SID can also now be included in the rac.nodes configuration property to support such installations.
The following example illustrates connecting to two Oracle RAC nodes, each using different ports and SID parameters:
{
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"rac.nodes": "host1.domain.com:1521/ORCLSID1,host2.domain.com:1522/ORCLSID2",
...
}Other fixes
There were quite a number of bugfixes and stability changes in this release, some noteworthy are:
-
Debezium Server stops sending events to Google Cloud Pub/Sub DBZ-5175
-
Toasted varying character array and date array are not correcly processed DBZ-6122
-
Upgrade to Infinispan 14.0.11.Final to fix CVE-2022-45047 DBZ-6193
-
Introduce LogMiner query filtering modes DBZ-6254
-
Lock contention on LOG_MINING_FLUSH table when multiple connectors deployed DBZ-6256
-
Ensure that the connector can start from a stale timestamp more than one hour into the past DBZ-6307
-
The rs_id field is null in Oracle change event source information block DBZ-6329
-
Add JWT authentication to HTTP Client DBZ-6348
-
Using pg_replication_slot_advance which is not supported by PostgreSQL10. DBZ-6353
-
log.mining.transaction.retention.hours should reference last offset and not sysdate DBZ-6355
-
Support multiple tasks when streaming shard list DBZ-6365
-
Code Improvements for skip.messages.without.change DBZ-6366
-
Kinesis Sink - AWS Credentials Provider DBZ-6372
-
Toasted hstore are not correctly processed DBZ-6379
-
Oracle DDL shrink space for table partition can not be parsed DBZ-6386
-
__source_ts_ms r (read) operation date is set to future for SQL Server DBZ-6388
-
PostgreSQL connector task fails to resume streaming because replication slot is active DBZ-6396
-
Date and Time values without timezones are not persisted correctly based on database.time_zone DBZ-6399
-
MongoDB connector crashes on invalid resume token DBZ-6402
-
Snapshot step 5 - Reading structure of captured tables time too long DBZ-6439
-
NPE on read-only MySQL connector start up DBZ-6440
-
Oracle parallel snapshots do not properly set PDB context when using multitenancy DBZ-6457
-
[MariaDB] Add support for userstat plugin keywords DBZ-6459
-
Debezium Server cannot recover from Google Pub/Sub errors DBZ-6461
-
"Ignoring invalid task provided offset" DBZ-6463
-
Oracle snapshot.include.collection.list should be prefixed with databaseName in documentation. DBZ-6474
-
Db2 connector can fail with NPE on notification sending DBZ-6485
-
ExtractNewRecordState SMT in combination with HeaderToValue SMT results in Unexpected field name exception DBZ-6486
-
BigDecimal fails when queue memory size limit is in place DBZ-6490
-
Allow schema to be specified in the Debezium Sink Connector configuration DBZ-6491
-
ORACLE table can not be captured, got runtime.NoViableAltException DBZ-6492
-
Signal poll interval has incorrect default value DBZ-6496
-
Oracle JDBC driver 23.x throws ORA-18716 - not in any time zone DBZ-6502
-
Alpine postgres images should use llvm/clang 15 explicitly DBZ-6506
-
FileSignalChannel is not loaded DBZ-6509
-
Utilize event.processing.failure.handling.mode in Vitess replication connection DBZ-6510
-
MySqlReadOnlyIncrementalSnapshotChangeEventSource enforces Kafka dependency during initialization DBZ-6511
-
Debezium incremental snapshot chunk size documentation unclear or incorrect DBZ-6512
-
Error value of negative seconds in convertOracleIntervalDaySecond DBZ-6513
-
Debezium incremental snapshot chunk size documentation unclear or incorrect DBZ-6515
-
Only use error processing mode on certain errors DBZ-6523
-
[PostgreSQL] LTree data is not being captured by streaming DBZ-6524
-
Oracle Connector: Snapshot fails with specific combination DBZ-6528
-
Use better hashing function for PartitionRouting DBZ-6529
-
Table order is incorrect on snapshots DBZ-6533
-
Start publishing nightly images for Debezium Operator DBZ-6541
-
Start releasing images for Debezium Operator DBZ-6542
-
Unhandled NullPointerException in PartitionRouting will crash the whole connect plugin DBZ-6543
-
Bug in field.name.adjustment.mode Property DBZ-6559
-
Operator sets incorrect value of transformation.predicate when no predicate is specified DBZ-6560
-
Upgrade MySQL JDBC driver to 8.0.33 DBZ-6563
-
Upgrade Google Cloud BOM to 26.17.0 DBZ-6570
-
Kubernetes-Config extension interferes with SSL tests due to k8 devservice starting up DBZ-6574
-
MySQL read-only connector with Kafka signals enabled fails on start up DBZ-6579
-
Redis schema history can fail upon startup DBZ-6580
Altogether, 138 issues were fixed for this release. A big thank you to all the contributors from the community who worked on this release: Andrei Isac, Angshuman Dey, Anil Dasari, Anisha Mohanty, Bertrand Paquet, Bob Roldan, Breno Moreira, Chris Cranford, Christian Jacob Mencias, David Beck, Frederic Laurent, Gong Chang Hua, Harvey Yue, Hidetomi Umaki, Hussain Ansari, Indra Shukla, Ismail Simsek, Jakub Cechacek, Jesse Ehrenzweig, Jiri Pechanec, Jochen Schalanda, Kanthi Subramanian, Katerina Galieva, Mario Fiore Vitale, Martin Medek, Miguel Angel Sotomayor, Nancy Xu, Nir Levy, Ondrej Babec, Oren Elias, RJ Nowling, René Kerner, Robert Roldan, Ronak Jain, Sergey Eizner, Shuran Zhang, Stephen Clarkson, Thomas Thornton, Tommy Karlsson, Tony Joseph, Vojtech Juranek, and 蔡灿材!
What’s next?
With Debezium 2.3 out, our major focus will be coordinating bugfixes to any reports for Debezium 2.3, but primarily on the upcoming new preview release for Debezium 2.4.
Debezium 2.4 is planned with a ton of changes, and we intend to tackle these changes in a bucketed fashion, with each bucket being assigned a priority. As with any schedule, priorities are subject to change but the following is an outline of what to expect:
- Priority 1
-
-
[Core] TimescaleDB single message transformation support
-
[Core] Timezone single message transformation to ease usages with Debezium temporal types
-
[Core] Initial snapshot notifications
-
[MongoDB] Database-wide change stream support
-
[MongoDB] Multi-task deployment metrics support
-
[Oracle] OpenLogReplicator adapter support
-
[Oracle] XML, LONG, RAW, and LONG RAW data type support
-
[Universal] Exactly-Once semantics support for other connectors
-
[Dependencies] Apache Kafka 3.5.x support
-
- Priority 2
-
-
[Operator] Next steps for Debezium operator
-
[Core] Ad-hoc blocking snapshot
-
[Dependencies] Use OpenTelemetry
-
- Priority 3
-
-
[Embedded Engine] Parallelization support
-
[MongoDB] Parallel incremental snapshots support
-
[MySQL] Parallel schema snapshots support
-
This is not an exhaustive list and its quite ambitious, but given the shortened time with Debezium 2.3, we hope the extra few weeks on Debezium 2.4 will make this next minor release possible with all these features and much more. The roadmap will be updated this week to align with the above for Debezium 2.4 and the future, so please be sure to get in touch with us on the mailing list or our chat if you have any ideas or suggestions.
Otherwise, I expect with summer in full swing for those of us in the north, holidays and much-deserved time-off will be normal for the next several months. To those who travel or intend to take some time for yourselves and family, enjoy and be safe!
Until next time…
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.