
As you probably noticed, we have started work on Debezium 2.0. One of the planned changes for the 2.0 release is to switch to Java 11 as a baseline. While some Java build providers still support Java 8, other Java 8 distributions already reached their end of life/support. Users are moving to Java 11 anyways, as surveys like New Relic’s State of the Java Ecosystem Report indicate. But it is not only matter of support: Java 11 comes with various performance improvements, useful tools like JDK Flight Recorder, which was open-sourced in Java 11, and more. So we felt it was about time to start thinking about using a more recent JDK as the baseline for Debezium, and the new major release is a natural milestone when to do the switch.
Starting with the first release of Debezium 2.0, 2.0.0.Alpha1, Debezium bits will be compiled to Java 11 byte code. Therefore, Java 11 will be required to run Debezium in the next major update. Also, if you use any of the Debezium bits as a library in your project (using the Debezium embedded engine), you will have to switch to Java 11.
But wait, what does Java 11/17 in the title mean? Is it there just to scare you, or we are going to actually switch to Java 17 right away?
<dramatic pause here>
No, we don’t want to scare you. We are actually planning to switch to Java 17, but only for the test suite. Please note that both Java 11 and 17 are long term support (LTS) releases. We don’t want to move Java 17 for the actual Debezium artifacts just yet, as it can be an issue for substantial amount of Debezium users; as e.g. the aforementioned New Relic report shows that most of the users are still on Java 11 and of course we don’t want to exclude them. However, using Java 17 for tests doesn’t affect users in any way, and will allow us to use some more recent Java features in the tests, like e.g. * text blocks, which for instance simplify the usage of multi-line JSON or SQL strings, * records, which can improve readability of the stream operations heavily used in our tests, * switch expressions, and more.
Pretty sweet, right?
Implementation
Setting different byte code levels for code and tests is pretty easy with Maven, you just need to set the following properties:
<maven.compiler.release>11</maven.compiler.release>
<maven.compiler.testRelease>17</maven.compiler.testRelease>Please note that we’re using the release option instead of the legacy source and target options, which prevents the accidental usage of Java APIs not present in the targeted Java version. See e.g. Gunnar’s blog post ByteBuffer and the Dreaded NoSuchMethodError for more details.
After switching to Java 11, the Maven Checkstyle plug-in and the ImpSort plug-in (a plug-in which takes care of proper import ordering) started to fail. However, bumping their versions to the latest releases has solved all the issues.
This was the easy part. The most difficult part was the Debezium connector for Apache Cassandra.
Cassandra Connector Tests
Since version 1.9, the Cassandra connector provides support for Cassandra 3 as well as for Cassandra 4. Cassandra 4 works like a charm with Java 11, but running Cassandra 3 with Java 11 is not possible (or at least requires some hacking). The existing test implementation for this connector didn’t run Cassandra in a container as we do it in tests for all other DB connectors, but instead runs Cassandra in embedded mode, i.e. within the same JVM and process as the tests themselves. Therefore if you wanted to run the tests with Java 11 (or 17), tests for the Cassandra 3 connector module would fail.
The obvious solution is to run Cassandra in a container with Java 8. This sounds good, but this approach has one pitfall. The Cassandra connector needs access to Cassandra log files as it obtains CDC events from them, so the tests need to access Cassandra files in the container. This can be solved quite easily using a temporary directory, for instance within the target directory, mounting it as a volume into the container running Cassandra. Cassandra running in the container can later on use this mounted volume for storing its data.
The real issue starts when you try to do the cleanup after the tests. As Cassandra runs in the container under a dedicated user named cassandra, which is very likely not present on the test machine (or with a different UID/GID), cleanup fails when it tries to delete the temporary directory with Cassandra files. These files were created in that temporal directory mounted into the container and not in Docker FS overlay, so that are present in the target directory. As the files were created by the cassandra user, which is very likely different user than one who runs the tests, user running the tests has insufficient rights to delete files created by cassandra user. Trying to delete them from Cassandra’s container on Cassandra exit in some wrapper script turned out to be quite cumbersome and not very reliable.
The most promising solution proved to involve starting a second container with the same cassandra user with access to the mounted volume and cleaning up the files after the first Cassandra container had already stopped.
We considered two options for running containers:
We use the Fabric8 plugin in the rest of the project, which suggests to use it also in this case to have uniformity across the project. On the other hand, using Testcontainers would make tests more convenient for the developers (who actually use tests after all!), as it allows to run the tests directly from IDE without starting the container manually.
In the end, the decision was driven by the fact that running a cleanup container is not possible with the Fabric8 plugin. Maven doesn’t allow to execute different configurations in the same phase and therefore it’s not possible to stop the Cassandra container in the post-integration-test phase and at the same time run a cleanup container in this phase. Testcontainers allow starting and stopping containers programmatically when needed, letting us define the images directly in the test code so we don’t need any additional Dockerfile , and cleaning up the container is just an implementation detail hidden in the test itself. Having the ability to run the tests directly from an IDE, without having to manually start and stop a container with the database, is a nice benefit on top of these things.
The only tricky thing when using Testcontainers was that when we tried to remove the log files using Docker’s cmd command, Testcontainers randomly failed, stating that the container didn’t start in spite of the fact that all Cassandra files were actually deleted. The container probably ran so fast that it finished before Testcontainers noticed it. Finally, we solved it by adding a short sleep in the container and executing an additional command in the container which does the cleanup.
The final cleanup code using Testcontainers looks like this:
@AfterClass
public static void tearDownClass() throws IOException, InterruptedException {
destroyTestKeyspace();
cassandra.stop();
GenericContainer cleanup = new GenericContainer(new ImageFromDockerfile()
.withDockerfileFromBuilder(builder -> builder
.from("eclipse-temurin:8-jre-focal")
.volume("/var/lib/cassandra")
.cmd("sleep", "10") // Give TC some time to find out container is running.
.build()))
.withFileSystemBind(cassandraDir, CASSANDRA_SERVER_DIR, BindMode.READ_WRITE);
cleanup.start();
cleanup.execInContainer(
"rm", "-rf",
CASSANDRA_SERVER_DIR + "/data",
CASSANDRA_SERVER_DIR + "/cdc_raw_directory",
CASSANDRA_SERVER_DIR + "/commitlog",
CASSANDRA_SERVER_DIR + "/hints",
CASSANDRA_SERVER_DIR + "/saved_caches");
cleanup.stop();
}Once we solved the issue with the Cassandra tests, we were mostly done and were ready to use Java 11 in the main Debezium code and Java 17 for our tests.
Open Issues
We need more battle testing to be sure that everything works well with Java 11/17. Your help with testing and bug reports would be very valuable here and more than welcome. Currently we are aware of one minor unsolved issue related to the Java update. Some IDEs cannot distinguish between maven.compiler.release and maven.compiler.testRelease (or it’s not very clear to us how to set it up). For example this test using a text block is marked as an error in the IDE:
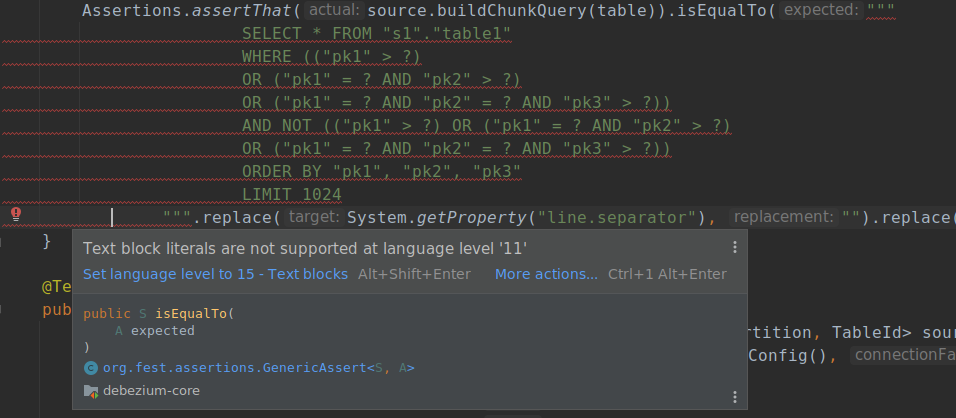
Test using text block in IntelliJ Idea.
You can manually set the Java level to 17, but in this case you may unintentionally use Java > 11 features in non-test code without the IDE letting you know (which admittedly isn’t too much of a problem, as the next Maven build, e.g. on CI, would catch that issue). Moreover, e.g. Idea resets the code level upon any changes in the pom.xml files. Have you solved this issue? Or do you use an IDE which doesn’t have issues with mixing different Java levels? Please share your experiences in the discussion!
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.