
I am very happy to share the news that Debezium 1.9.0.Final has been released!
Besides the usual set of bug fixes and improvements, key features of this release are support for Apache Cassandra 4, multi-database support for the Debezium connector for SQL Server, the ability to use Debezium Server as a Knative event source, as well as many improvements to the integration of Debezium Server with Redis Streams.
Exactly 276 issues have been fixed by the community for the 1.9 release; a big thank you to each and everyone who helped to make this happen!
Support for Apache Cassandra 4
Added right in time for the candidate release of Debezium 1.9, support for Cassandra 4 has been added to the Debezium Cassandra connector. Or, more specifically, a new connector has been added. I.e. you should now either download the debezium-connector-cassandra-3 or the debezium-connector-cassandra-4 connector archive, depending on your database version. While we usually strive for multi-version support within indvidual connectors, the code changes required to support the new version were that substantial, that we decided to have two separate code bases for the two connector versions (with commonalities extracted into a shared module).
Both connectors, for Cassandra 3 and 4, remain in incubating state for the time being and you can expect further improvements to them within the near feature. A massive thank you to Štefan Miklošovič and Ahmed Eljami for this huge piece of work, which also paves the road towards moving to Java 11 as the baseline for Debezium in the near future.
SQL Server Multi-Database Support
SQL Server allows for setting up multiple logical databases on one physical host, which for instance comes in handy for separating the data of different tenants of a multi-tenant capable application. Historically, this required to set up one instance of the Debezium connector for SQL Server per logical database, which could become a bit cumbersome when dealing with tens or even hundreds of databases, as often the case for multi-tenancy use cases.
Over the last year, Sergei Morozov and his team at SugarCRM reworked the Debezium SQL Server connector and the Debezium connector framework to be multi-partition aware for address sitations like this: the framework is now capable of streaming changes from multiple source partitions, which are split up between connector tasks (in Kafka Connect terminology), which in turn can be distributed amongst the worker nodes of a Kafka Connect cluster.
In case of the SQL Server connector, a logical database equates to one such source partition, so that you now can stream for instance 20 databases from one physical SQL Server host, spread across four source tasks running on five Kafka Connect worker nodes. To use the new multi-partition mode, configure the names of the databases to capture via the new database.names connector configuration property (rather than using the previously existing database.dbname), and optionally set the value of tasks.max to a value larger than 1. Note that the schema and topic names as well as the structure of connector metrics differs between single and multi-partition mode, so as to account for the name of the logical database and the id of the source task, respectively.
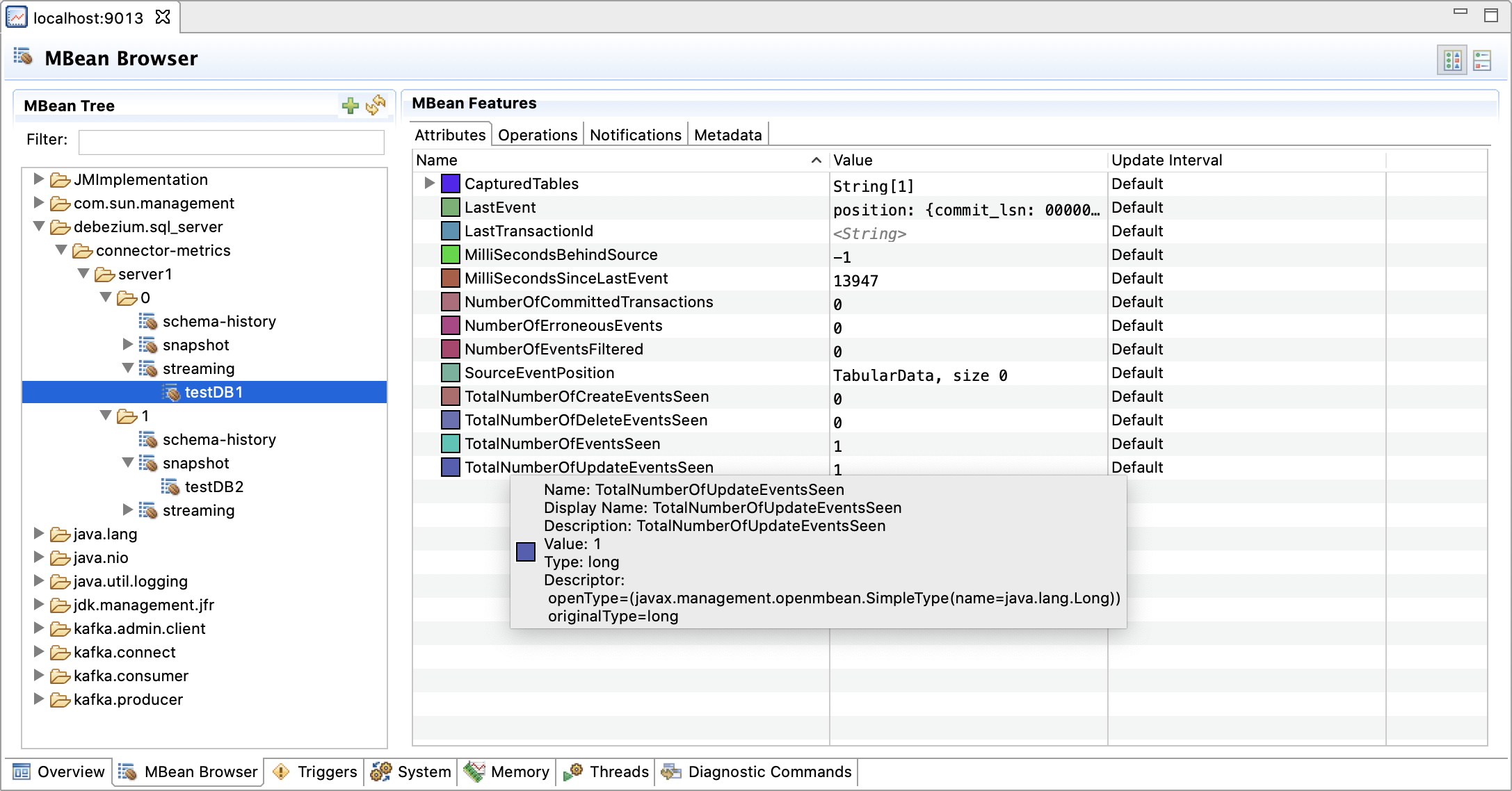
Multi-partition mode is experimental as of the 1.9 release and is planned to fully replace the legacy single partition mode for the SQL Server connector in a future release, i.e. also if you’d capture changes from only one single logical database, you’ll be using the multi-partition mode then. Multi-partition mode will also be rolled out for other connectors where it’s possible, e.g. for the connectors for Oracle and IBM Db2.
Thanks a lot to Sergei and team for their excellent collaboration around that feature!
Further Changes
Let’s take a look at some more features new in Debezium 1.9. First, Debezium Server now includes a sink adaptor for HTTP, which means it can be used as a "native" event source for Knative Serving, without the need for sending messages through a message broker like Apache Kafka first.
Then, the friendly folks over at Redis stepped up and contributed several improvements to how Debezium (Server) integrates with Redis Streams: besides several performance improvements, the database history for connectors like the MySQL one can now be stored in Redis, also offsets can be stored there now. But they didn’t stop there: for instance, Debezium Server now supports custom configuration providers, as already provided in Kafka Connect.
Going forward, the Redis team is planning to work on further cool improvements to Debezium at large, such as better retrying logic in case of failures. Looking forward to those!
To learn more about all the features, improvements and bug fixes shipped in Debezium 1.9, please check out the original release announcements (Alpha1, Alpha2, Beta1, and CR1) as well as the 1.9 release notes!
Many thanks to all the folks from the Debezium community which contributed code changes to this release:
Aidas, Andrei Isac, Anisha Mohanty, Bob Roldan, Chris Baumbauer, Chris Cranford, Christian Stein, Clément Loiselet, David Haglund, Dominique Chanet, Ethan Zou, Farid Uyar, Gunnar Morling, Hady Willi, Harvey Yue, Ismail Simsek, Jacob Gminder, Jakub Cechacek, JapuDCret, Jason Schweier, Jiri Novotny, Jiri Pechanec, Jose Luis Sánchez, Josh Ribera, Katerina Galieva, Li Mo, M Sazzadul Hoque, Mark Drilling, Martin Medek, Mike Kamornikov, Nansen, Nathan Smit, Nenad Stojanovikj, Oren Elias, Oscar Romero, Paweł Malon, Poonam Meghnani, Qishang Zhong, René Kerner, Richard Kolkovich, Robert Roldan, Sebastian Bruckner, Sergei Morozov, Shichao An, Snigdhajyoti Ghosh, Stefan Miklosovic, Vojtěch Juránek, Willie Zhu, Yang, Yingying Tang, Yossi Shirizli, and 胡琴!
Coming Up
So what’s next after 1.9? You may think 1.10, but that’s not what we’ll do; instead, we’re planning to release Debezium 2.0 as a new major version later this year!
While we don’t strictly adhere to semantic versioning (i.e. a new minor release like 1.9 may require some small degree of consideration), one of our key objectives with Debezium releases is to limit breaking changes for existing users as much as possible. That’s why for instance configuration options that became superfluous are not just removed but deprecated. The same applies for changes to the change event format, which are rolled out gradually. Over time, this has led to a number of legacy options and other aspects which we finally want to iron out. Debezium 2.0 will be the release where we will get rid of this kind of legacy cruft. For instance, we are planning to
-
Remove the legacy implementations of the connectors for MySQL and MongoDB (superseded by more capable and mature implementations based on Debezium’s standard connector framework, which have been enabled by default for quite some time)
-
Drop wal2json support for Postgres (superseded by pgoutput)
-
Use Java 11 as a baseline (for instance allowing to emit JDK Flight Recorder events for better diagnostics)
-
Default to multi-partition mode metrics (improved consistency)
-
Make default topic names more consistent, for instance for the heartbeat topic
-
Change the default type mappings for a small number of column types
Planning for this is in full swing right now, and you are very much invited to join the discussion either on the mailing list or on the DBZ-3899 issue in Jira. Note that while we want to take the opportunity to clean up some odditities which have accumulated over time, backwards compatibility will be key concern as always, and we’ll try to minimize the impact on existing users. But as you would expect it from a new major release, upgrading may take a slightly larger effort in comparison to the usual minor releases.
In terms of a timeline, due to the size and number of planned changes, we’re going to deviate from the usual quarterly release cadence and instead reserve two quarters for working on Debezium 2.0, i.e. you can look forward to that release at the end of September. In the meantime, there will be bugfix releases of the 1.9 version, as needed per incoming bug reports.
Upwards and onwards!
Gunnar Morling
Gunnar is a software engineer and open-source enthusiast by heart, currently working as a Technologist at Confluent. Previously, he helped to build a realtime stream processing platform based on Apache Flink and led the Debezium project, a distributed platform for change data capture. He is a Java Champion and has founded multiple open source projects such as JfrUnit, kcctl, and MapStruct. Gunnar is an avid blogger (morling.dev) and has spoken at various conferences like QCon, Java One, and Devoxx. He lives in Hamburg, Germany.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.