
I am happy to announce the release of Debezium 1.9.0.Beta1!
This release includes many new features for Debezium Server, including Knative Eventing support and offset storage management with the Redis sink, multi-partitioned scaling for the SQL Server connector, and various of bugfixes and improvements. Overall, 56 issues have been fixed for this release.
Let’s take a closer look at a couple of them.
Debezium Server Knative Eventing
Debezium Server has grown quite a lot since its introduction to the Debezium portfolio in version 1.2. In this release, we have added a new sink implementation to support Knative Eventing.
Knative Eventing "provides tools and infrastructure to route events from a producer to consumers", in a very similar way in which Apache Kafka allows the exchange of events via message topics. With Debezium Server, you can now leverage the new debezium-server-http sink to deliver Debezium change data events to a Knative Broker, a Kubernetes resource that defines a mesh for collecting and distributing CloudEvents to consumers. In other words, Debezium Server can act as a "native" Knative event source.
In order to get started with Debezium and Knative Eventing, you simply need to configure the Debezium Server with your desired source connector and then configure the sink side with the following:
debezium.sink.type=http
debezium.format.value=cloudeventsThe sink will attempt to automatically detect the endpoint based on the K_SINK environment variable. If no value is defined by this variable, you can explicitly provide the end-point URL directly using:
debezium.sink.http.url=https://<hostname>/<end-point>We’re super excited about this new sink connector and we look forward to all your feedback. A big thank you to Chris Baumbauer for this excellent contribution!
Redis-managed Offsets for Debezium Server
Several folks from Redis stepped up lately for improving the story around integrating Debezium and Redis Streams. After the performance improvements done in 1.9.0.Alpha1 (by means of batching), another result of that work is the ability to store connector offsets in Redis. For the next 1.9 early access release you can expect a database history implementation backed by Redis, and the team also is working on implementing retry support for Debezium Server. Thanks a lot to Yossi Shirizli, Oren Elias and all the other Redis folks contributing not only to the Redis Streams sink, but also to Debezium and Debezium Server at large!
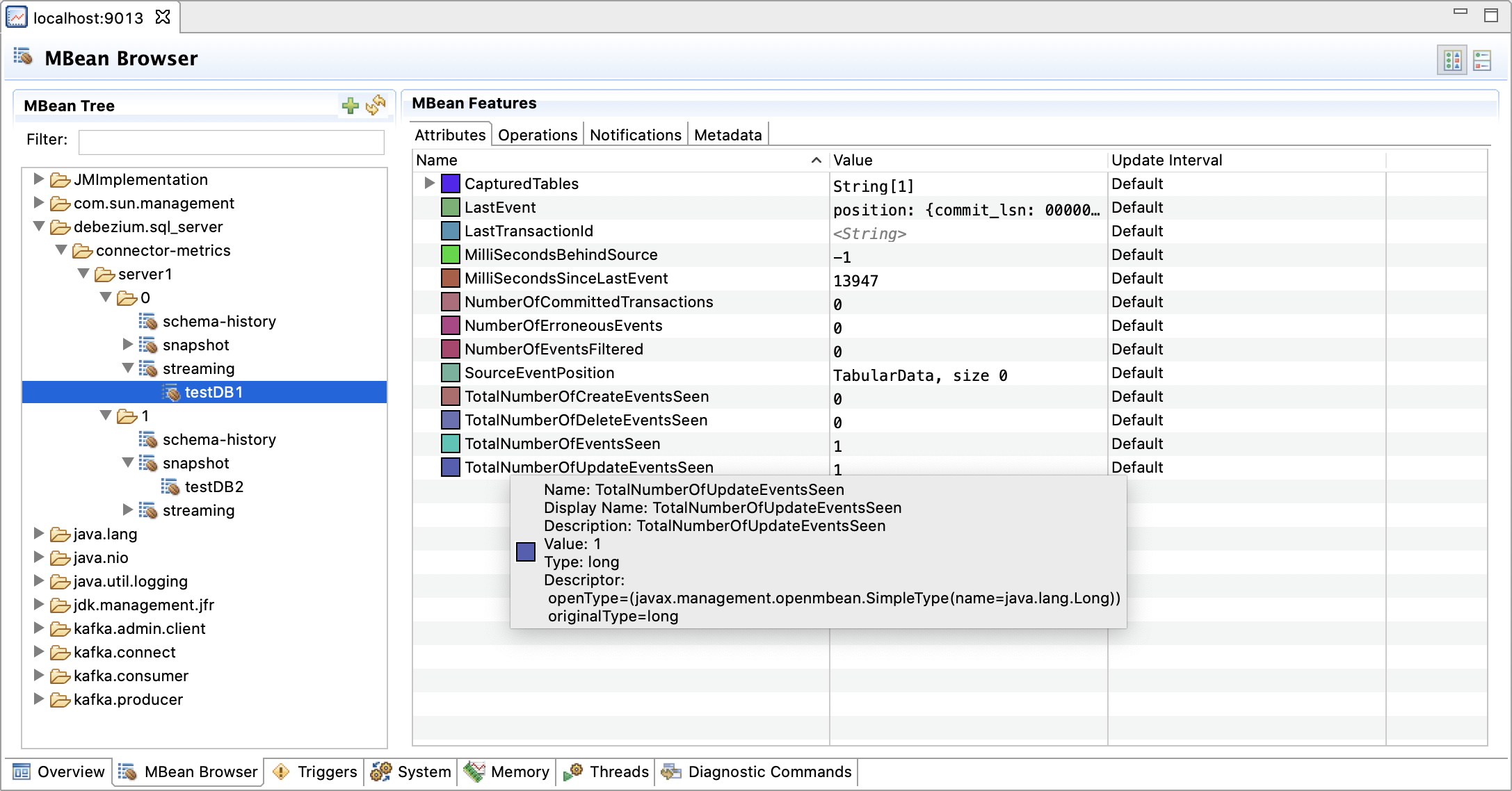
Multi-partitioned Scaling for SQL Server Connector
Some database platforms, such as SQL Server and Oracle, support the creation and management of multiple logical databases within a single physical database server instance. Traditionally, streaming changes from the multiple logical databases required a separate connector deployment. Now there isn’t anything innately wrong with such a deployment strategy, but it can quickly start to show its shortcomings if you have many logical databases; for instance in case of multi-tenancy scenarios with one logical database per tenant, the overhead of setting up and operating one connector per database can become a bottleneck. Besides that, processing change events from multiple logical databases lends itself perfectly well to parallelization by means of Kafka Connect’s concept of tasks.
Over the last several 1.x releases, a tremendous amount of work has gone into key fundamental changes to Debezium’s common connector framework, setting the stage for a new horizontal scaling strategy.
One of the initial goals of this new strategy is to eliminate the need for multiple connector deployments when streaming changes from multiple logical databases within a single SQL Server instance. Additionally, it was critical to expose metrics in a way that enables monitoring tools to report on the state and health of the connector both from a connector-centric perspective but also from each logical database being processed. In this release, we’ve achieved those goals.
But this is just the beginning folks!
This foundation prepares the groundwork where we can move toward new horizontal scaling strategies. Debezium uses a single-task based architecture and this opens the possibilities to really harness the power of a multi-node Kafka Connect cluster and distribute chunks of work across multiple tasks. Furthermore, this can be extended to other connectors such as Oracle.
This work has been led by the team around Sergei Morozov of SugarCRM, who already deploy the SQL Server connector in multi-partition mode built from an internal fork, which they internally maintain until the entire work has been upstreamed. We’d like to say a huge, huge thank you to Sergei, Jacob Gminder, Mike Kamornikov, and everyone else from SugarCRM who worked tirelessly to make this possible for the Debezium community, and we’re looking forward very much to continuing and further expanding this close collaboration.
Other Fixes and Changes
Further fixes and improvements in the 1.9.0.Beta1 release include:
Please refer to the release notes to learn more about these and further fixes in this release.
As always, a big thank you to everyone contributing to this release:
Aidas, Anisha Mohanty, Bob Roldan, Chris Baumbauer, Chris Cranford, Dominique Chanet, Gunnar Morling, Harvey Yue, Jacob Gminder, Jakub Cechacek, Jiri Novotny, Jiri Pechanec, Josh Ribera, Li Mo, Martin Medek, Mike Kamornikov, M Sazzadul Hoque, Oren Elias, René Kerner, Robert Roldan, Sergei Morozov, Snigdhajyoti Ghosh, Vojtech Juranek, Willie Zhu, Yang, Yingying Tang, and Yossi Shirizli
Outlook
With the Beta1 release done, we are approaching the final phase of the 1.9 release cycle. Depending on the incoming issue reports, you can expect a new release in the next few weeks to likely be CR1.
As we turn and look ahead beyond 1.9, you can expect work on Debezium 2.0 to begin in early April 2022. The current roadmap is to devote 2 full release cycles, which means you can expect Debezium 2.0 sometime near the end of September 2022. In the meantime, you can expect regular updates to Debezium 1.9 throughout this process.
If you are interested in Debezium 2.0, we have collected a number of items in DBZ-3899 thus far. This is not an exhaustive list nor has this list been prioritized and scoped to what you can expect in totality of 2.0; however, it is what we’ve identified to be things that either the community or the team feel are actionable tasks for this new major release. If there is something you would like to see, please take a moment and either raise a discussion on the above Jira ticket or join the discussion on this topic on our mailing list.
About Debezium
Debezium is an open source distributed platform that turns your existing databases into event streams, so applications can see and respond almost instantly to each committed row-level change in the databases. Debezium is built on top of Kafka and provides Kafka Connect compatible connectors that monitor specific database management systems. Debezium records the history of data changes in Kafka logs, so your application can be stopped and restarted at any time and can easily consume all of the events it missed while it was not running, ensuring that all events are processed correctly and completely. Debezium is open source under the Apache License, Version 2.0.
Get involved
We hope you find Debezium interesting and useful, and want to give it a try. Follow us on Twitter @debezium, chat with us on Zulip, or join our mailing list to talk with the community. All of the code is open source on GitHub, so build the code locally and help us improve ours existing connectors and add even more connectors. If you find problems or have ideas how we can improve Debezium, please let us know or log an issue.